 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutCoT: Unleashing the Deep Reasoning Potential of Large Language Models for Layout Generation
Apr 15, 2025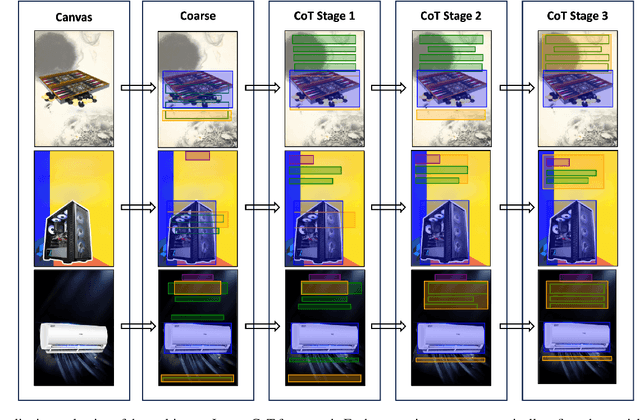
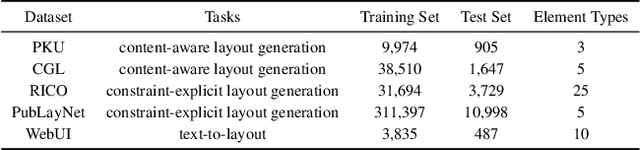
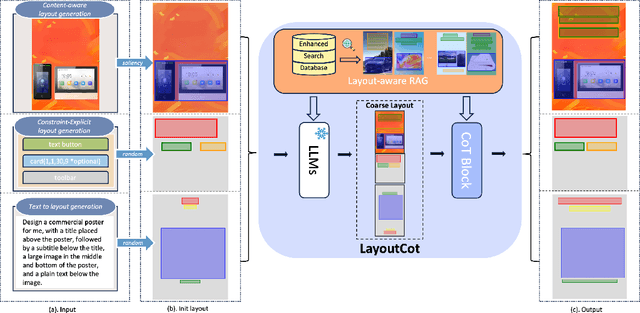
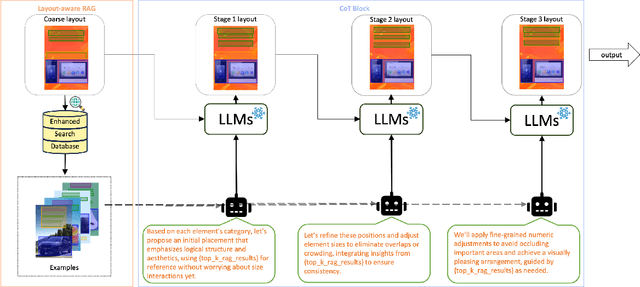
Conditional layout generation aims to automatically generate visually appealing and semantically coherent layouts from user-defined constraints. While recent methods based on generative models have shown promising results, they typically require substantial amounts of training data or extensive fine-tuning, limiting their versatility and practical applicability. Alternatively, some training-free approaches leveraging in-context learning with Large Language Models (LLMs) have emerged, but they often suffer from limited reasoning capabilities and overly simplistic ranking mechanisms, which restrict their ability to generate consistently high-quality layouts. To this end, we propose LayoutCoT, a novel approach that leverages the reasoning capabilities of LLMs through a combination of Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) techniques. Specifically, LayoutCoT transforms layout representations into a standardized serialized format suitable for processing by LLMs. A Layout-aware RAG is used to facilitate effective retrieval and generate a coarse layout by LLMs. This preliminary layout, together with the selected exemplars, is then fed into a specially designed CoT reasoning module for iterative refinement, significantly enhancing both semantic coherence and visual quality. We conduct extensive experiments on five public datasets spanning three conditional layout generation tasks. Experimental results demonstrate that LayoutCoT achieves state-of-the-art performance without requiring training or fine-tuning. Notably, our CoT reasoning module enables standard LLMs, even those without explicit deep reasoning abilities, to outperform specialized deep-reasoning models such as deepseek-R1, highlighting the potential of our approach in unleashing the deep reasoning capabilities of LLMs for layout generation tasks.
Faster Multi-GPU Training with PPLL: A Pipeline Parallelism Framework Leveraging Local Learning
Nov 19, 2024



Currently, training large-scale deep learning models is typically achieved through parallel training across multiple GPUs. However, due to the inherent communication overhead and synchronization delays in traditional model parallelism methods, seamless parallel training cannot be achieved, which, to some extent, affects overall training efficiency. To address this issue, we present PPLL (Pipeline Parallelism based on Local Learning), a novel framework that leverages local learning algorithms to enable effective parallel training across multiple GPUs. PPLL divides the model into several distinct blocks, each allocated to a separate GPU. By utilizing queues to manage data transfers between GPUs, PPLL ensures seamless cross-GPU communication, allowing multiple blocks to execute forward and backward passes in a pipelined manner. This design minimizes idle times and prevents bottlenecks typically caused by sequential gradient updates, thereby accelerating the overall training process. We validate PPLL through extensive experiments using ResNet and Vision Transformer (ViT) architectures on CIFAR-10, SVHN, and STL-10 datasets. Our results demonstrate that PPLL significantly enhances the training speed of the local learning method while achieving comparable or even superior training speed to traditional pipeline parallelism (PP) without sacrificing model performance. In a 4-GPU training setup, PPLL accelerated local learning training on ViT and ResNet by 162% and 33%, respectively, achieving 1.25x and 0.85x the speed of traditional pipeline parallelism.
Replacement Learning: Training Vision Tasks with Fewer Learnable Parameters
Oct 02, 2024



Traditional end-to-end deep learning models often enhance feature representation and overall performance by increasing the depth and complexity of the network during training. However, this approach inevitably introduces issues of parameter redundancy and resource inefficiency, especially in deeper networks. While existing works attempt to skip certain redundant layers to alleviate these problems, challenges related to poor performance, computational complexity, and inefficient memory usage remain. To address these issues, we propose an innovative training approach called Replacement Learning, which mitigates these limitations by completely replacing all the parameters of the frozen layers with only two learnable parameters. Specifically, Replacement Learning selectively freezes the parameters of certain layers, and the frozen layers utilize parameters from adjacent layers, updating them through a parameter integration mechanism controlled by two learnable parameters. This method leverages information from surrounding structures, reduces computation, conserves GPU memory, and maintains a balance between historical context and new inputs, ultimately enhancing overall model performance. We conducted experiments across four benchmark datasets, including CIFAR-10, STL-10, SVHN, and ImageNet, utilizing various architectures such as CNNs and ViTs to validate the effectiveness of Replacement Learning. Experimental results demonstrate that our approach reduces the number of parameters, training time, and memory consumption while completely surpassing the performance of end-to-end training.
HPFF: Hierarchical Locally Supervised Learning with Patch Feature Fusion
Jul 09, 2024Traditional deep learning relies on end-to-end backpropagation for training, but it suffers from drawbacks such as high memory consumption and not aligning with biological neural networks. Recent advancements have introduced locally supervised learning, which divides networks into modules with isolated gradients and trains them locally. However, this approach can lead to performance lag due to limited interaction between these modules, and the design of auxiliary networks occupies a certain amount of GPU memory. To overcome these limitations, we propose a novel model called HPFF that performs hierarchical locally supervised learning and patch-level feature computation on the auxiliary networks. Hierarchical Locally Supervised Learning (HiLo) enables the network to learn features at different granularity levels along their respective local paths. Specifically, the network is divided into two-level local modules: independent local modules and cascade local modules. The cascade local modules combine two adjacent independent local modules, incorporating both updates within the modules themselves and information exchange between adjacent modules. Patch Feature Fusion (PFF) reduces GPU memory usage by splitting the input features of the auxiliary networks into patches for computation. By averaging these patch-level features, it enhances the network's ability to focus more on those patterns that are prevalent across multiple patches. Furthermore, our method exhibits strong generalization capabilities and can be seamlessly integrated with existing techniques. We conduct experiments on CIFAR-10, STL-10, SVHN, and ImageNet datasets, and the results demonstrate that our proposed HPFF significantly outperforms previous approaches, consistently achieving state-of-the-art performance across different datasets. Our code is available at: https://github.com/Zeudfish/HPFF.
Momentum Auxiliary Network for Supervised Local Learning
Jul 09, 2024



Deep neural networks conventionally employ end-to-end backpropagation for their training process, which lacks biological credibility and triggers a locking dilemma during network parameter updates, leading to significant GPU memory use. Supervised local learning, which segments the network into multiple local blocks updated by independent auxiliary networks. However, these methods cannot replace end-to-end training due to lower accuracy, as gradients only propagate within their local block, creating a lack of information exchange between blocks. To address this issue and establish information transfer across blocks, we propose a Momentum Auxiliary Network (MAN) that establishes a dynamic interaction mechanism. The MAN leverages an exponential moving average (EMA) of the parameters from adjacent local blocks to enhance information flow. This auxiliary network, updated through EMA, helps bridge the informational gap between blocks. Nevertheless, we observe that directly applying EMA parameters has certain limitations due to feature discrepancies among local blocks. To overcome this, we introduce learnable biases, further boosting performance. We have validated our method on four image classification datasets (CIFAR-10, STL-10, SVHN, ImageNet), attaining superior performance and substantial memory savings. Notably, our method can reduce GPU memory usage by more than 45\% on the ImageNet dataset compared to end-to-end training, while achieving higher performance. The Momentum Auxiliary Network thus offers a new perspective for supervised local learning. Our code is available at: https://github.com/JunhaoSu0/MAN.
GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection
Jul 01, 2024



Safety issues at construction sites have long plagued the industry, posing risks to worker safety and causing economic damage due to potential hazards. With the advancement of artificial intelligence, particularly in the field of computer vision, the automation of safety monitoring on construction sites has emerged as a solution to this longstanding issue. Despite achieving impressive performance, advanced object detection methods like YOLOv8 still face challenges in handling the complex conditions found at construction sites. To solve these problems, this study presents the Global Stability Optimization YOLO (GSO-YOLO) model to address challenges in complex construction sites. The model integrates the Global Optimization Module (GOM) and Steady Capture Module (SCM) to enhance global contextual information capture and detection stability. The innovative AIoU loss function, which combines CIoU and EIoU, improves detection accuracy and efficiency. Experiments on datasets like SODA, MOCS, and CIS show that GSO-YOLO outperforms existing methods, achieving SOTA performance.
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Jun 01, 2024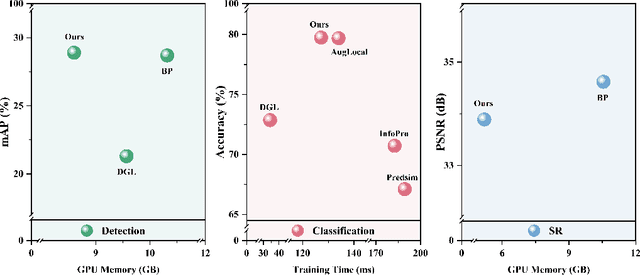
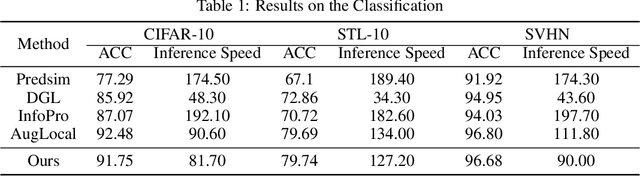
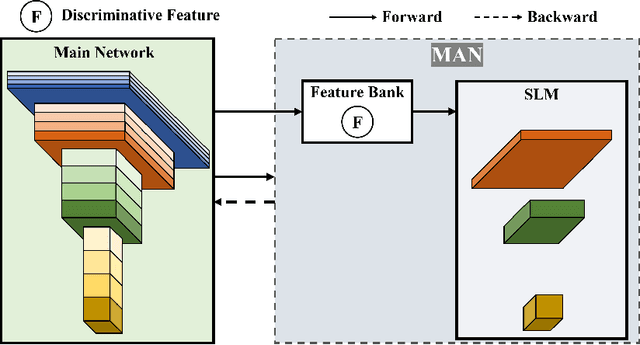
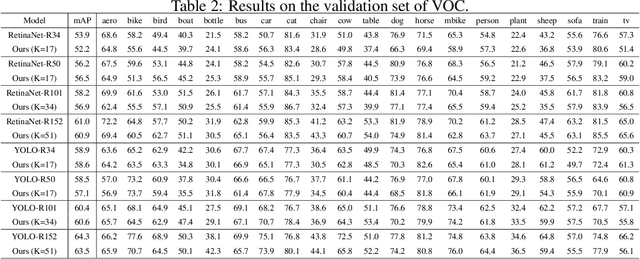
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
May 12, 2024Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E