 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Multi-GPU Training with PPLL: A Pipeline Parallelism Framework Leveraging Local Learning
Nov 19, 2024



Currently, training large-scale deep learning models is typically achieved through parallel training across multiple GPUs. However, due to the inherent communication overhead and synchronization delays in traditional model parallelism methods, seamless parallel training cannot be achieved, which, to some extent, affects overall training efficiency. To address this issue, we present PPLL (Pipeline Parallelism based on Local Learning), a novel framework that leverages local learning algorithms to enable effective parallel training across multiple GPUs. PPLL divides the model into several distinct blocks, each allocated to a separate GPU. By utilizing queues to manage data transfers between GPUs, PPLL ensures seamless cross-GPU communication, allowing multiple blocks to execute forward and backward passes in a pipelined manner. This design minimizes idle times and prevents bottlenecks typically caused by sequential gradient updates, thereby accelerating the overall training process. We validate PPLL through extensive experiments using ResNet and Vision Transformer (ViT) architectures on CIFAR-10, SVHN, and STL-10 datasets. Our results demonstrate that PPLL significantly enhances the training speed of the local learning method while achieving comparable or even superior training speed to traditional pipeline parallelism (PP) without sacrificing model performance. In a 4-GPU training setup, PPLL accelerated local learning training on ViT and ResNet by 162% and 33%, respectively, achieving 1.25x and 0.85x the speed of traditional pipeline parallelism.
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Jun 01, 2024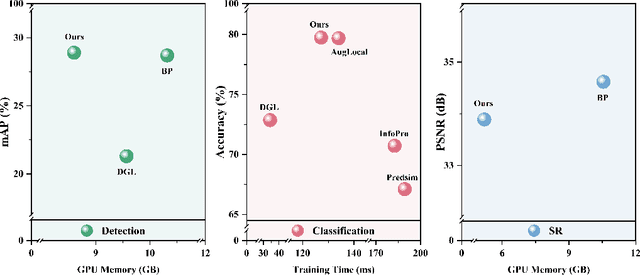
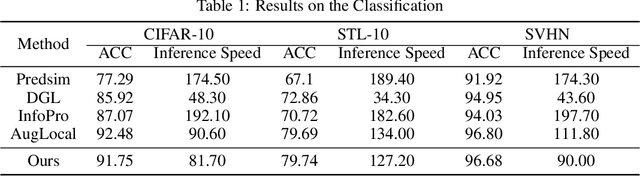
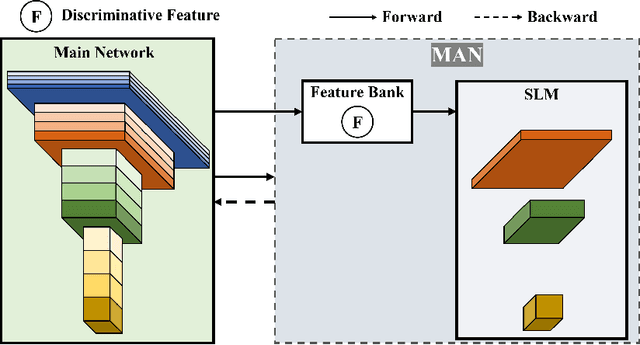
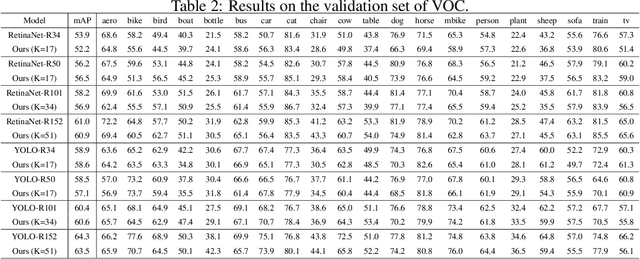
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
May 12, 2024Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E