 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacement Learning: Training Neural Networks with Fewer Parameters
May 19, 2026End-to-end training with full-depth backpropagation remains the dominant paradigm for optimizing deep neural networks, but its efficiency deteriorates as models grow deeper. Since every block must be executed and differentiated under a single global objective, full-depth BP introduces substantial parameter redundancy, activation-memory cost, and training latency, especially when neighboring layers exhibit highly correlated learning patterns. Directly skipping or removing layers can reduce cost, but often weakens representation capacity or requires architecture-specific reuse designs. In this paper, we propose Replacement Learning (RepL), a training-time paradigm that reduces full-depth redundancy by replacing selected blocks rather than simply discarding them. For each removed block, RepL inserts a lightweight computing layer that synthesizes a surrogate operator from the parameters of its adjacent preceding and succeeding blocks through a learnable transformation, and applies the synthesized operator to the preceding activation. In this way, RepL preserves local contextual continuity while avoiding unnecessary full-layer computation. We instantiate RepL for CNNs and ViTs with tailored parameter-fusion blocks that handle convolutional channels, feature resolutions, and transformer submodules. Extensive experiments on CIFAR-10, SVHN, STL-10, ImageNet, COCO, and CityScapes show that RepL reduces trainable parameters, GPU memory usage, and training time while matching or surpassing standard end-to-end training across classification, detection, and segmentation. Additional results on WikiText-2, transfer learning, inference throughput, checkpointing, stochastic depth, and INT8 quantization further demonstrate its generality and compatibility.
Rethinking Local Learning: A Cheaper and Faster Recipe for LLM Post-Training
May 06, 2026LLM post-training typically propagates task gradients through the full depth of the model. Although this end-to-end structure is simple and general, it couples task adaptation to full-depth activation storage, long-range backward dependencies and direct task-gradient access to pretrained representations. We argue that this full-depth backward coupling can be unnecessarily expensive and intrusive, particularly when post-training supervision is much narrower than pre-training. To this end, we propose \textbf{LoPT}: Local-Learning Post-Training, a simple post-training strategy that makes gradient reach an explicit design choice. LoPT places a single gradient boundary at the transformer midpoint: the second-half block learns from the task objective, while the first-half block is updated by a lightweight feature-reconstruction objective to preserve useful representations and maintain interface compatibility. LoPT shortens the task-induced backward path while limiting direct interference from narrow task gradients on early-layer representations. Extensive experiments demonstrate that LoPT achieves competitive performance with lower memory cost, higher training efficiency and better retention of pretrained capabilities. Our code is available at: https://github.com/HumyuShi/LoPT
Faster Multi-GPU Training with PPLL: A Pipeline Parallelism Framework Leveraging Local Learning
Nov 19, 2024



Currently, training large-scale deep learning models is typically achieved through parallel training across multiple GPUs. However, due to the inherent communication overhead and synchronization delays in traditional model parallelism methods, seamless parallel training cannot be achieved, which, to some extent, affects overall training efficiency. To address this issue, we present PPLL (Pipeline Parallelism based on Local Learning), a novel framework that leverages local learning algorithms to enable effective parallel training across multiple GPUs. PPLL divides the model into several distinct blocks, each allocated to a separate GPU. By utilizing queues to manage data transfers between GPUs, PPLL ensures seamless cross-GPU communication, allowing multiple blocks to execute forward and backward passes in a pipelined manner. This design minimizes idle times and prevents bottlenecks typically caused by sequential gradient updates, thereby accelerating the overall training process. We validate PPLL through extensive experiments using ResNet and Vision Transformer (ViT) architectures on CIFAR-10, SVHN, and STL-10 datasets. Our results demonstrate that PPLL significantly enhances the training speed of the local learning method while achieving comparable or even superior training speed to traditional pipeline parallelism (PP) without sacrificing model performance. In a 4-GPU training setup, PPLL accelerated local learning training on ViT and ResNet by 162% and 33%, respectively, achieving 1.25x and 0.85x the speed of traditional pipeline parallelism.
Replacement Learning: Training Vision Tasks with Fewer Learnable Parameters
Oct 02, 2024



Traditional end-to-end deep learning models often enhance feature representation and overall performance by increasing the depth and complexity of the network during training. However, this approach inevitably introduces issues of parameter redundancy and resource inefficiency, especially in deeper networks. While existing works attempt to skip certain redundant layers to alleviate these problems, challenges related to poor performance, computational complexity, and inefficient memory usage remain. To address these issues, we propose an innovative training approach called Replacement Learning, which mitigates these limitations by completely replacing all the parameters of the frozen layers with only two learnable parameters. Specifically, Replacement Learning selectively freezes the parameters of certain layers, and the frozen layers utilize parameters from adjacent layers, updating them through a parameter integration mechanism controlled by two learnable parameters. This method leverages information from surrounding structures, reduces computation, conserves GPU memory, and maintains a balance between historical context and new inputs, ultimately enhancing overall model performance. We conducted experiments across four benchmark datasets, including CIFAR-10, STL-10, SVHN, and ImageNet, utilizing various architectures such as CNNs and ViTs to validate the effectiveness of Replacement Learning. Experimental results demonstrate that our approach reduces the number of parameters, training time, and memory consumption while completely surpassing the performance of end-to-end training.
MLAAN: Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network
Jun 24, 2024End-to-end (E2E) training approaches are commonly plagued by high memory consumption, reduced efficiency in training, challenges in model parallelization, and suboptimal biocompatibility. Local learning is considered a novel interactive training method that holds promise as an alternative to E2E. Nonetheless, conventional local learning methods fall short in achieving high model accuracy due to inadequate local inter-module interactions. In this paper, we introduce a new model known as the Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network (MLAAN). MLAAN features an innovative supervised local learning approach coupled with a robust reinforcement module. This dual-component design enables the MLAAN to integrate smoothly with established local learning techniques, thereby enhancing the efficacy of the foundational methods. The method simultaneously acquires the local and global features of the model separately by constructing an independent auxiliary network and a cascade auxiliary network on the one hand and incorporates a leap augmented module, which serves to counteract the reduced learning capacity often associated with weaker supervision. This architecture not only augments the exchange of information amongst the local modules but also effectively mitigates the model's tendency toward myopia. The experimental evaluations conducted on four benchmark datasets, CIFAR-10, STL-10, SVHN, and ImageNet, demonstrate that the integration of MLAAN with existing supervised local learning methods significantly enhances the original methodologies. Of particular note, MLAAN enables local learning methods to comprehensively outperform end-to-end training approaches in terms of optimal performance while saving GPU memory.
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Jun 01, 2024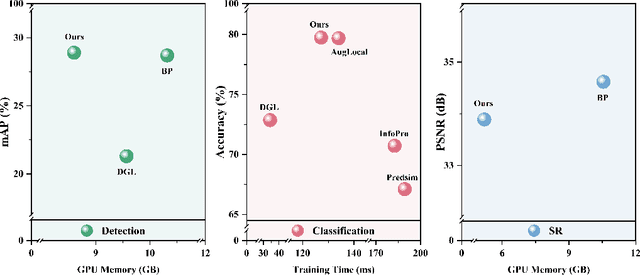
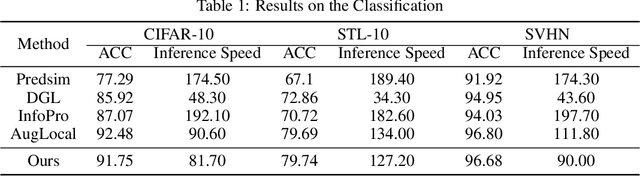
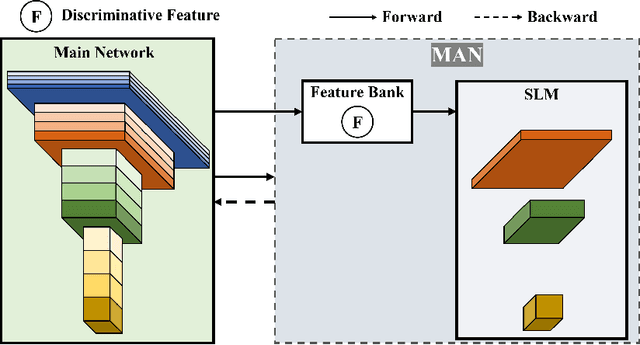
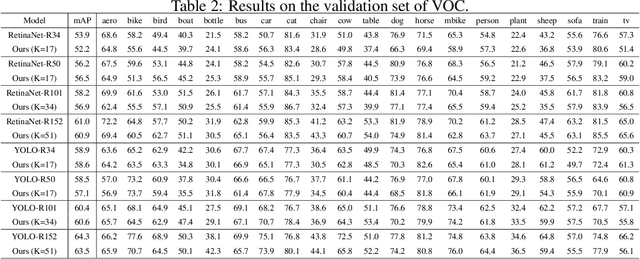
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.