 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutCoT: Unleashing the Deep Reasoning Potential of Large Language Models for Layout Generation
Paper and Code
Apr 15, 2025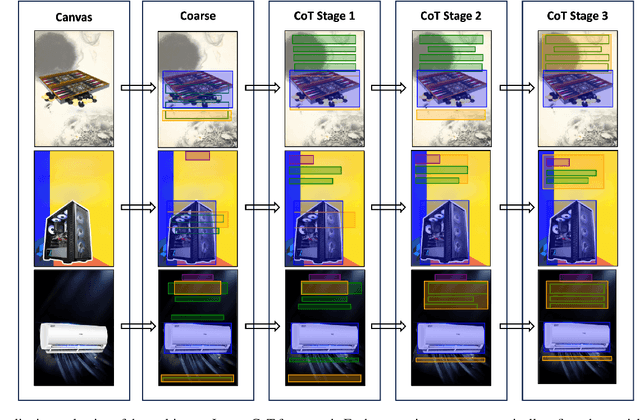
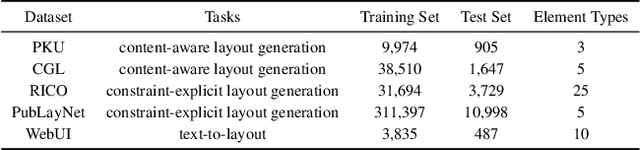
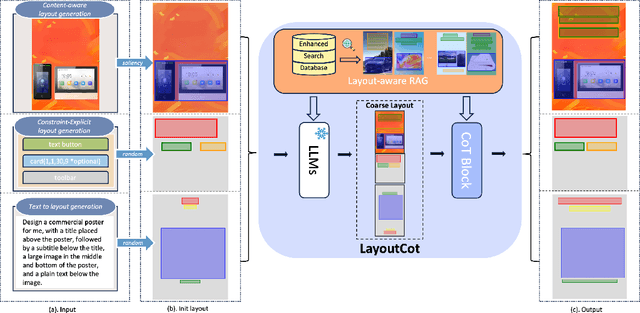
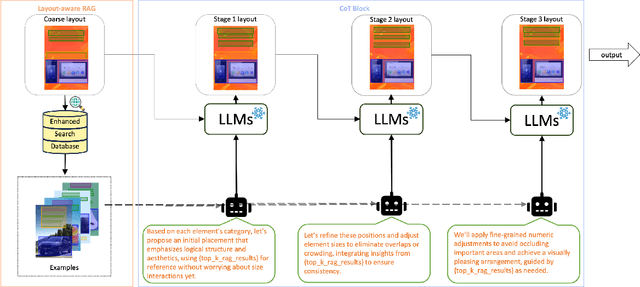
Conditional layout generation aims to automatically generate visually appealing and semantically coherent layouts from user-defined constraints. While recent methods based on generative models have shown promising results, they typically require substantial amounts of training data or extensive fine-tuning, limiting their versatility and practical applicability. Alternatively, some training-free approaches leveraging in-context learning with Large Language Models (LLMs) have emerged, but they often suffer from limited reasoning capabilities and overly simplistic ranking mechanisms, which restrict their ability to generate consistently high-quality layouts. To this end, we propose LayoutCoT, a novel approach that leverages the reasoning capabilities of LLMs through a combination of Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) techniques. Specifically, LayoutCoT transforms layout representations into a standardized serialized format suitable for processing by LLMs. A Layout-aware RAG is used to facilitate effective retrieval and generate a coarse layout by LLMs. This preliminary layout, together with the selected exemplars, is then fed into a specially designed CoT reasoning module for iterative refinement, significantly enhancing both semantic coherence and visual quality. We conduct extensive experiments on five public datasets spanning three conditional layout generation tasks. Experimental results demonstrate that LayoutCoT achieves state-of-the-art performance without requiring training or fine-tuning. Notably, our CoT reasoning module enables standard LLMs, even those without explicit deep reasoning abilities, to outperform specialized deep-reasoning models such as deepseek-R1, highlighting the potential of our approach in unleashing the deep reasoning capabilities of LLMs for layout generation tasks.