 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Recommendation from Noisy Implicit Feedback: A GMM-Weighted Bayes-label Transition Matrix Framework
May 20, 2026Learning from implicit feedback in recommender systems is fundamentally challenged by pervasive label noise. While conventional denoising approaches often discard noisy instances to ensure robustness, this strategy inevitably suffers from low data utilization. Alternative methods that employ a Bayes-label transition matrix (BLTM) can leverage all available data, but their estimates tend to be biased in practical recommendation scenarios. To address these limitations, this paper proposes a Robust GMM-weighted Bayes-label Transition Matrix framework (RGBT). Our solution utilizes a Gaussian Mixture Model (GMM) to derive instance-specific reliability scores, which systematically calibrate the BLTM estimation to mitigate bias. Theoretical analysis confirms that our approach, by leveraging the BLTM framework with GMM calibration, simultaneously ensures full sample utilization, delivers consistent estimation, and critically, achieves a significant reduction in estimation variance. Extensive experiments on multiple real-world and synthetically flipped datasets demonstrate that RGBT not only utilizes noisy samples more effectively than mainstream reliable sample-based denoising methods, but also achieves significantly superior calibration capability of the transition matrix compared to state-of-the-art transition matrix-based denoising approaches.
WiFo-MiSAC: A Wireless Foundation Model for Multimodal Sensing and Communication Integration via Synesthesia of Machines (SoM)
Apr 20, 2026Current learning-based wireless methods struggle with generalization due to the fragmented processing of communication and sensing data. WiFo-MiSAC addresses this as a task-agnostic foundation model that tokenizes heterogeneous signals into a unified space for self-supervised pre-training. A shared-specific disentangled mixture-of-experts (SS-DMoE) architecture is employed to decouple modality-shared and modality-specific representations, facilitating interaction without cross-modal interference. By combining masked reconstruction with contrastive alignment, the model achieves state-of-the-art performance across downstream tasks, including beam prediction and channel estimation. Experimental results demonstrate robust few-shot adaptation and seamless integration of new modalities, positioning WiFo-MiSAC as a scalable backbone for future integrated sensing and communication systems.
Large Wireless Foundation Models: Stronger over Bigger
Jan 16, 2026AI-communication integration is widely regarded as a core enabling technology for 6G. Most existing AI-based physical-layer designs rely on task-specific models that are separately tailored to individual modules, resulting in poor generalization. In contrast, communication systems are inherently general-purpose and should support broad applicability and robustness across diverse scenarios. Foundation models offer a promising solution through strong reasoning and generalization, yet wireless-system constraints hinder a direct transfer of large language model (LLM)-style success to the wireless domain. Therefore, we introduce the concept of large wireless foundation models (LWFMs) and present a novel framework for empowering the physical layer with foundation models under wireless constraints. Specifically, we propose two paradigms for realizing LWFMs, including leveraging existing general-purpose foundation models and building novel wireless foundation models. Based on recent progress, we distill two roadmaps for each paradigm and formulate design principles under wireless constraints. We further provide case studies of LWFM-empowered wireless systems to intuitively validate their advantages. Finally, we characterize the notion of "large" in LWFMs through a multidimensional analysis of existing work and outline promising directions for future research.
DSConv: Dynamic Splitting Convolution for Pansharpening
Aug 08, 2025Aiming to obtain a high-resolution image, pansharpening involves the fusion of a multi-spectral image (MS) and a panchromatic image (PAN), the low-level vision task remaining significant and challenging in contemporary research. Most existing approaches rely predominantly on standard convolutions, few making the effort to adaptive convolutions, which are effective owing to the inter-pixel correlations of remote sensing images. In this paper, we propose a novel strategy for dynamically splitting convolution kernels in conjunction with attention, selecting positions of interest, and splitting the original convolution kernel into multiple smaller kernels, named DSConv. The proposed DSConv more effectively extracts features of different positions within the receptive field, enhancing the network's generalization, optimization, and feature representation capabilities. Furthermore, we innovate and enrich concepts of dynamic splitting convolution and provide a novel network architecture for pansharpening capable of achieving the tasks more efficiently, building upon this methodology. Adequate fair experiments illustrate the effectiveness and the state-of-the-art performance attained by DSConv.Comprehensive and rigorous discussions proved the superiority and optimal usage conditions of DSConv.
Foundation Model Empowered Synesthesia of Machines (SoM): AI-native Intelligent Multi-Modal Sensing-Communication Integration
Jun 09, 2025To support future intelligent multifunctional sixth-generation (6G) wireless communication networks, Synesthesia of Machines (SoM) is proposed as a novel paradigm for artificial intelligence (AI)-native intelligent multi-modal sensing-communication integration. However, existing SoM system designs rely on task-specific AI models and face challenges such as scarcity of massive high-quality datasets, constrained modeling capability, poor generalization, and limited universality. Recently, foundation models (FMs) have emerged as a new deep learning paradigm and have been preliminarily applied to SoM-related tasks, but a systematic design framework is still lacking. In this paper, we for the first time present a systematic categorization of FMs for SoM system design, dividing them into general-purpose FMs, specifically large language models (LLMs), and SoM domain-specific FMs, referred to as wireless foundation models. Furthermore, we derive key characteristics of FMs in addressing existing challenges in SoM systems and propose two corresponding roadmaps, i.e., LLM-based and wireless foundation model-based design. For each roadmap, we provide a framework containing key design steps as a guiding pipeline and several representative case studies of FM-empowered SoM system design. Specifically, we propose LLM-based path loss generation (LLM4PG) and scatterer generation (LLM4SG) schemes, and wireless channel foundation model (WiCo) for SoM mechanism exploration, LLM-based wireless multi-task SoM transceiver (LLM4WM) and wireless foundation model (WiFo) for SoM-enhanced transceiver design, and wireless cooperative perception foundation model (WiPo) for SoM-enhanced cooperative perception, demonstrating the significant superiority of FMs over task-specific models. Finally, we summarize and highlight potential directions for future research.
Multi-Granularity Vision Fastformer with Fusion Mechanism for Skin Lesion Segmentation
Apr 04, 2025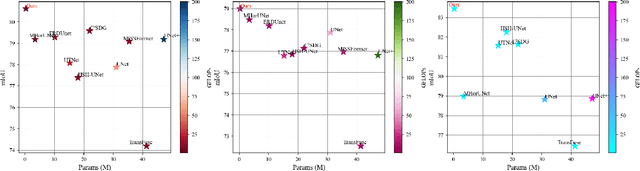
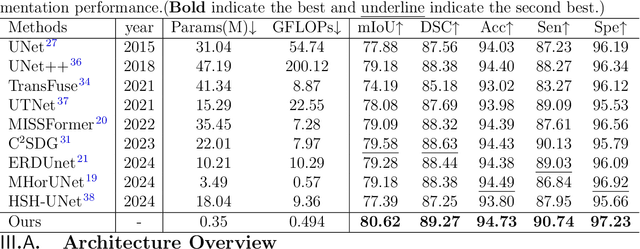


Background:Convolutional Neural Networks(CNN) and Vision Transformers(ViT) are the main techniques used in Medical image segmentation. However, CNN is limited to local contextual information, and ViT's quadratic complexity results in significant computational costs. At the same time, equipping the model to distinguish lesion boundaries with varying degrees of severity is also a challenge encountered in skin lesion segmentation. Purpose:This research aims to optimize the balance between computational costs and long-range dependency modelling and achieve excellent generalization across lesions with different degrees of severity. Methods:we propose a lightweight U-shape network that utilizes Vision Fastformer with Fusion Mechanism (VFFM-UNet). We inherit the advantages of Fastformer's additive attention mechanism, combining element-wise product and matrix product for comprehensive feature extraction and channel reduction to save computational costs. In order to accurately identify the lesion boundaries with varying degrees of severity, we designed Fusion Mechanism including Multi-Granularity Fusion and Channel Fusion, which can process the feature maps in the granularity and channel levels to obtain different contextual information. Results:Comprehensive experiments on the ISIC2017, ISIC2018 and PH2 datasets demonstrate that VFFM-UNet outperforms existing state-of-the-art models regarding parameter numbers, computational complexity and segmentation performance. In short, compared to MISSFormer, our model achieves superior segmentation performance while reducing parameter and computation costs by 101x and 15x, respectively. Conclusions:Both quantitative and qualitative analyses show that VFFM-UNet sets a new benchmark by reaching an ideal balance between parameter numbers, computational complexity, and segmentation performance compared to existing state-of-the-art models.
Static Batching of Irregular Workloads on GPUs: Framework and Application to Efficient MoE Model Inference
Jan 27, 2025
It has long been a problem to arrange and execute irregular workloads on massively parallel devices. We propose a general framework for statically batching irregular workloads into a single kernel with a runtime task mapping mechanism on GPUs. We further apply this framework to Mixture-of-Experts (MoE) model inference and implement an optimized and efficient CUDA kernel. Our MoE kernel achieves up to 91% of the peak Tensor Core throughput on NVIDIA H800 GPU and 95% on NVIDIA H20 GPU.
WiFo: Wireless Foundation Model for Channel Prediction
Dec 12, 2024



Channel prediction permits to acquire channel state information (CSI) without signaling overhead. However, almost all existing channel prediction methods necessitate the deployment of a dedicated model to accommodate a specific configuration. Leveraging the powerful modeling and multi-task learning capabilities of foundation models, we propose the first space-time-frequency (STF) wireless foundation model (WiFo) to address time-frequency channel prediction tasks in a one-for-all manner. Specifically, WiFo is initially pre-trained over massive and extensive diverse CSI datasets. Then, the model will be instantly used for channel prediction under various CSI configurations without any fine-tuning. We propose a masked autoencoder (MAE)-based network structure for WiFo to handle heterogeneous STF CSI data, and design several mask reconstruction tasks for self-supervised pre-training to capture the inherent 3D variations of CSI. To fully unleash its predictive power, we build a large-scale heterogeneous simulated CSI dataset consisting of 160K CSI samples for pre-training. Simulations validate its superior unified learning performance across multiple datasets and demonstrate its state-of-the-art (SOTA) zero-shot generalization performance via comparisons with other full-shot baselines.
Atrial Fibrillation Detection System via Acoustic Sensing for Mobile Phones
Oct 28, 2024


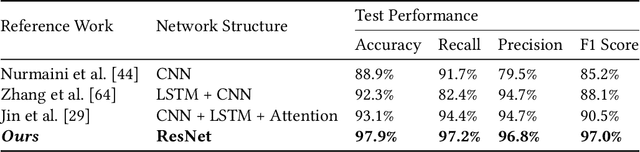
Atrial fibrillation (AF) is characterized by irregular electrical impulses originating in the atria, which can lead to severe complications and even death. Due to the intermittent nature of the AF, early and timely monitoring of AF is critical for patients to prevent further exacerbation of the condition. Although ambulatory ECG Holter monitors provide accurate monitoring, the high cost of these devices hinders their wider adoption. Current mobile-based AF detection systems offer a portable solution, however, these systems have various applicability issues such as being easily affected by environmental factors and requiring significant user effort. To overcome the above limitations, we present MobileAF, a novel smartphone-based AF detection system using speakers and microphones. In order to capture minute cardiac activities, we propose a multi-channel pulse wave probing method. In addition, we enhance the signal quality by introducing a three-stage pulse wave purification pipeline. What's more, a ResNet-based network model is built to implement accurate and reliable AF detection. We collect data from 23 participants utilizing our data collection application on the smartphone. Extensive experimental results demonstrate the superior performance of our system, with 97.9% accuracy, 96.8% precision, 97.2% recall, 98.3% specificity, and 97.0% F1 score.
AcousAF: Acoustic Sensing-Based Atrial Fibrillation Detection System for Mobile Phones
Aug 09, 2024
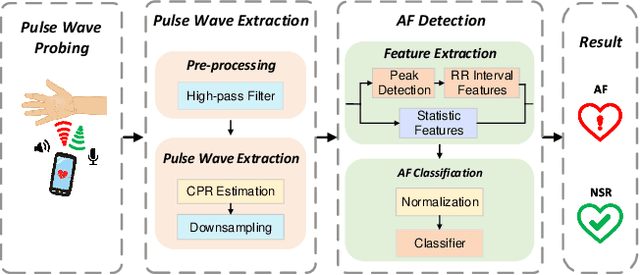
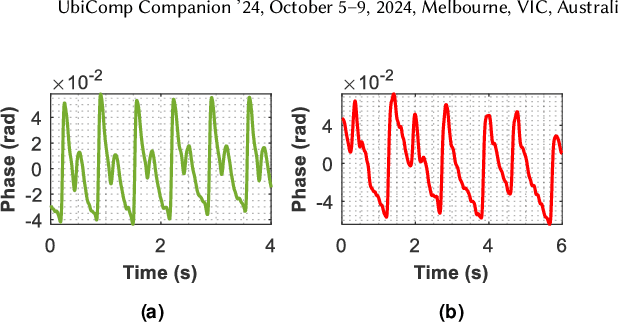
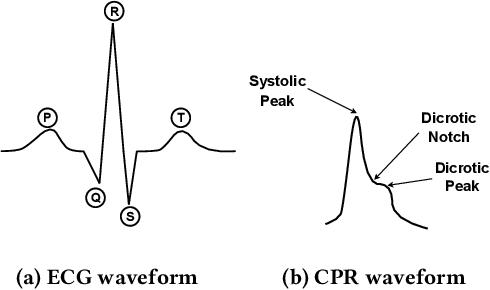
Atrial fibrillation (AF) is characterized by irregular electrical impulses originating in the atria, which can lead to severe complications and even death. Due to the intermittent nature of the AF, early and timely monitoring of AF is critical for patients to prevent further exacerbation of the condition. Although ambulatory ECG Holter monitors provide accurate monitoring, the high cost of these devices hinders their wider adoption. Current mobile-based AF detection systems offer a portable solution. However, these systems have various applicability issues, such as being easily affected by environmental factors and requiring significant user effort. To overcome the above limitations, we present AcousAF, a novel AF detection system based on acoustic sensors of smartphones. Particularly, we explore the potential of pulse wave acquisition from the wrist using smartphone speakers and microphones. In addition, we propose a well-designed framework comprised of pulse wave probing, pulse wave extraction, and AF detection to ensure accurate and reliable AF detection. We collect data from 20 participants utilizing our custom data collection application on the smartphone. Extensive experimental results demonstrate the high performance of our system, with 92.8% accuracy, 86.9% precision, 87.4% recall, and 87.1% F1 Score.