 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Vision Fastformer with Fusion Mechanism for Skin Lesion Segmentation
Apr 04, 2025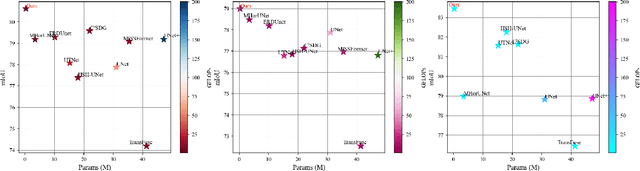
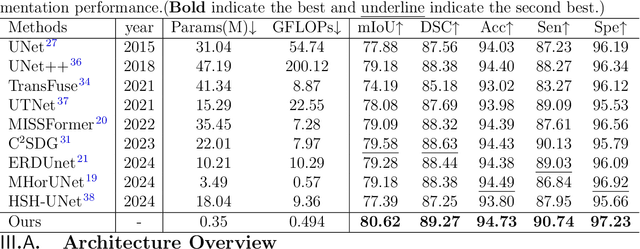


Background:Convolutional Neural Networks(CNN) and Vision Transformers(ViT) are the main techniques used in Medical image segmentation. However, CNN is limited to local contextual information, and ViT's quadratic complexity results in significant computational costs. At the same time, equipping the model to distinguish lesion boundaries with varying degrees of severity is also a challenge encountered in skin lesion segmentation. Purpose:This research aims to optimize the balance between computational costs and long-range dependency modelling and achieve excellent generalization across lesions with different degrees of severity. Methods:we propose a lightweight U-shape network that utilizes Vision Fastformer with Fusion Mechanism (VFFM-UNet). We inherit the advantages of Fastformer's additive attention mechanism, combining element-wise product and matrix product for comprehensive feature extraction and channel reduction to save computational costs. In order to accurately identify the lesion boundaries with varying degrees of severity, we designed Fusion Mechanism including Multi-Granularity Fusion and Channel Fusion, which can process the feature maps in the granularity and channel levels to obtain different contextual information. Results:Comprehensive experiments on the ISIC2017, ISIC2018 and PH2 datasets demonstrate that VFFM-UNet outperforms existing state-of-the-art models regarding parameter numbers, computational complexity and segmentation performance. In short, compared to MISSFormer, our model achieves superior segmentation performance while reducing parameter and computation costs by 101x and 15x, respectively. Conclusions:Both quantitative and qualitative analyses show that VFFM-UNet sets a new benchmark by reaching an ideal balance between parameter numbers, computational complexity, and segmentation performance compared to existing state-of-the-art models.
Scalable Attribution of Adversarial Attacks via Multi-Task Learning
Feb 25, 2023Deep neural networks (DNNs) can be easily fooled by adversarial attacks during inference phase when attackers add imperceptible perturbations to original examples, i.e., adversarial examples. Many works focus on adversarial detection and adversarial training to defend against adversarial attacks. However, few works explore the tool-chains behind adversarial examples, which can help defenders to seize the clues about the originator of the attack, their goals, and provide insight into the most effective defense algorithm against corresponding attacks. With such a gap, it is necessary to develop techniques that can recognize tool-chains that are leveraged to generate the adversarial examples, which is called Adversarial Attribution Problem (AAP). In this paper, AAP is defined as the recognition of three signatures, i.e., {\em attack algorithm}, {\em victim model} and {\em hyperparameter}. Current works transfer AAP into single label classification task and ignore the relationship between these signatures. The former will meet combination explosion problem as the number of signatures is increasing. The latter dictates that we cannot treat AAP simply as a single task problem. We first conduct some experiments to validate the attributability of adversarial examples. Furthermore, we propose a multi-task learning framework named Multi-Task Adversarial Attribution (MTAA) to recognize the three signatures simultaneously. MTAA contains perturbation extraction module, adversarial-only extraction module and classification and regression module. It takes the relationship between attack algorithm and corresponding hyperparameter into account and uses the uncertainty weighted loss to adjust the weights of three recognition tasks. The experimental results on MNIST and ImageNet show the feasibility and scalability of the proposed framework as well as its effectiveness in dealing with false alarms.