 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Attribution of Adversarial Attacks via Multi-Task Learning
Feb 25, 2023Deep neural networks (DNNs) can be easily fooled by adversarial attacks during inference phase when attackers add imperceptible perturbations to original examples, i.e., adversarial examples. Many works focus on adversarial detection and adversarial training to defend against adversarial attacks. However, few works explore the tool-chains behind adversarial examples, which can help defenders to seize the clues about the originator of the attack, their goals, and provide insight into the most effective defense algorithm against corresponding attacks. With such a gap, it is necessary to develop techniques that can recognize tool-chains that are leveraged to generate the adversarial examples, which is called Adversarial Attribution Problem (AAP). In this paper, AAP is defined as the recognition of three signatures, i.e., {\em attack algorithm}, {\em victim model} and {\em hyperparameter}. Current works transfer AAP into single label classification task and ignore the relationship between these signatures. The former will meet combination explosion problem as the number of signatures is increasing. The latter dictates that we cannot treat AAP simply as a single task problem. We first conduct some experiments to validate the attributability of adversarial examples. Furthermore, we propose a multi-task learning framework named Multi-Task Adversarial Attribution (MTAA) to recognize the three signatures simultaneously. MTAA contains perturbation extraction module, adversarial-only extraction module and classification and regression module. It takes the relationship between attack algorithm and corresponding hyperparameter into account and uses the uncertainty weighted loss to adjust the weights of three recognition tasks. The experimental results on MNIST and ImageNet show the feasibility and scalability of the proposed framework as well as its effectiveness in dealing with false alarms.
Is It Time to Redefine the Classification Task for Deep Neural Networks?
Oct 11, 2020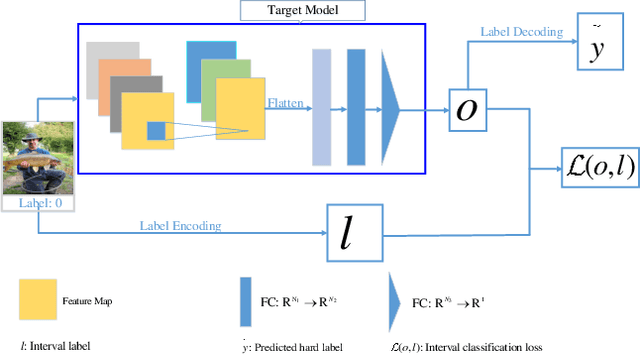



Deep neural networks (DNNs) is demonstrated to be vulnerable to the adversarial example, which is generated by adding small adversarial perturbation into the original legitimate example to cause the wrong outputs of DNNs. Nowadays, most works focus on the robustness of the deep model, while few works pay attention to the robustness of the learning task itself defined on DNNs. So we redefine this issue as the robustness of deep neural learning system. A deep neural learning system consists of the deep model and the learning task defined on the deep model. Moreover, the deep model is usually a deep neural network, involving the model architecture, data, training loss and training algorithm. We speculate that the vulnerability of the deep learning system also roots in the learning task itself. This paper defines the interval-label classification task for the deep classification system, whose labels are predefined non-overlapping intervals, instead of a fixed value (hard label) or probability vector (soft label). The experimental results demonstrate that the interval-label classification task is more robust than the traditional classification task while retaining accuracy.