 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Query Selection for Crowd-Based Reinforcement Learning
Aug 26, 2025Preference-based reinforcement learning has gained prominence as a strategy for training agents in environments where the reward signal is difficult to specify or misaligned with human intent. However, its effectiveness is often limited by the high cost and low availability of reliable human input, especially in domains where expert feedback is scarce or errors are costly. To address this, we propose a novel framework that combines two complementary strategies: probabilistic crowd modelling to handle noisy, multi-annotator feedback, and active learning to prioritize feedback on the most informative agent actions. We extend the Advise algorithm to support multiple trainers, estimate their reliability online, and incorporate entropy-based query selection to guide feedback requests. We evaluate our approach in a set of environments that span both synthetic and real-world-inspired settings, including 2D games (Taxi, Pacman, Frozen Lake) and a blood glucose control task for Type 1 Diabetes using the clinically approved UVA/Padova simulator. Our preliminary results demonstrate that agents trained with feedback on uncertain trajectories exhibit faster learning in most tasks, and we outperform the baselines for the blood glucose control task.
Beyond Pruning Criteria: The Dominant Role of Fine-Tuning and Adaptive Ratios in Neural Network Robustness
Oct 19, 2024
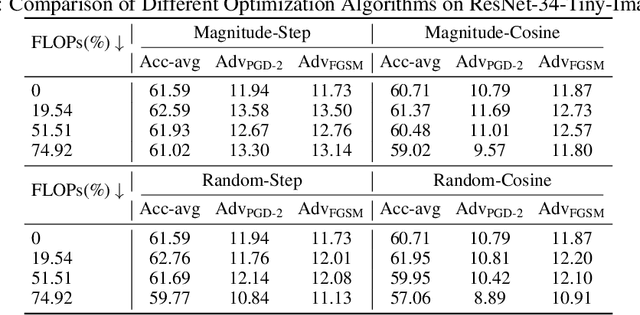

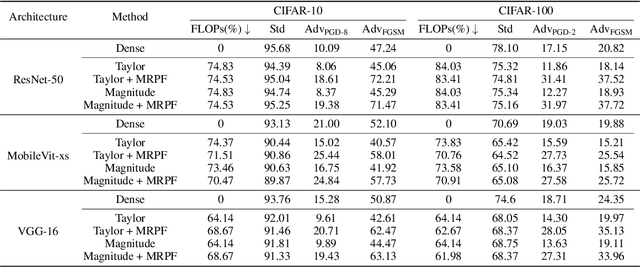
Deep neural networks (DNNs) excel in tasks like image recognition and natural language processing, but their increasing complexity complicates deployment in resource-constrained environments and increases susceptibility to adversarial attacks. While traditional pruning methods reduce model size, they often compromise the network's ability to withstand subtle perturbations. This paper challenges the conventional emphasis on weight importance scoring as the primary determinant of a pruned network's performance. Through extensive analysis, including experiments conducted on CIFAR, Tiny-ImageNet, and various network architectures, we demonstrate that effective fine-tuning plays a dominant role in enhancing both performance and adversarial robustness, often surpassing the impact of the chosen pruning criteria. To address this issue, we introduce Module Robust Sensitivity, a novel metric that adaptively adjusts the pruning ratio for each network layer based on its sensitivity to adversarial perturbations. By integrating this metric into the pruning process, we develop a stable algorithm that maintains accuracy and robustness simultaneously. Experimental results show that our approach enables the practical deployment of more robust and efficient neural networks.
Learning Confidence Bounds for Classification with Imbalanced Data
Jul 16, 2024



Class imbalance poses a significant challenge in classification tasks, where traditional approaches often lead to biased models and unreliable predictions. Undersampling and oversampling techniques have been commonly employed to address this issue, yet they suffer from inherent limitations stemming from their simplistic approach such as loss of information and additional biases respectively. In this paper, we propose a novel framework that leverages learning theory and concentration inequalities to overcome the shortcomings of traditional solutions. We focus on understanding the uncertainty in a class-dependent manner, as captured by confidence bounds that we directly embed into the learning process. By incorporating class-dependent estimates, our method can effectively adapt to the varying degrees of imbalance across different classes, resulting in more robust and reliable classification outcomes. We empirically show how our framework provides a promising direction for handling imbalanced data in classification tasks, offering practitioners a valuable tool for building more accurate and trustworthy models.
An Interactive Human-Machine Learning Interface for Collecting and Learning from Complex Annotations
Mar 28, 2024Human-Computer Interaction has been shown to lead to improvements in machine learning systems by boosting model performance, accelerating learning and building user confidence. In this work, we aim to alleviate the expectation that human annotators adapt to the constraints imposed by traditional labels by allowing for extra flexibility in the form that supervision information is collected. For this, we propose a human-machine learning interface for binary classification tasks which enables human annotators to utilise counterfactual examples to complement standard binary labels as annotations for a dataset. Finally we discuss the challenges in future extensions of this work.
Monitoring Sustainable Global Development Along Shared Socioeconomic Pathways
Dec 07, 2023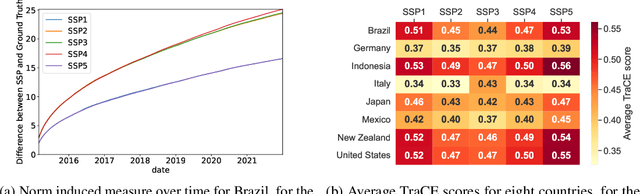
Sustainable global development is one of the most prevalent challenges facing the world today, hinging on the equilibrium between socioeconomic growth and environmental sustainability. We propose approaches to monitor and quantify sustainable development along the Shared Socioeconomic Pathways (SSPs), including mathematically derived scoring algorithms, and machine learning methods. These integrate socioeconomic and environmental datasets, to produce an interpretable metric for SSP alignment. An initial study demonstrates promising results, laying the groundwork for the application of different methods to the monitoring of sustainable global development.
Privacy in Multimodal Federated Human Activity Recognition
May 20, 2023



Human Activity Recognition (HAR) training data is often privacy-sensitive or held by non-cooperative entities. Federated Learning (FL) addresses such concerns by training ML models on edge clients. This work studies the impact of privacy in federated HAR at a user, environment, and sensor level. We show that the performance of FL for HAR depends on the assumed privacy level of the FL system and primarily upon the colocation of data from different sensors. By avoiding data sharing and assuming privacy at the human or environment level, as prior works have done, the accuracy decreases by 5-7%. However, extending this to the modality level and strictly separating sensor data between multiple clients may decrease the accuracy by 19-42%. As this form of privacy is necessary for the ethical utilisation of passive sensing methods in HAR, we implement a system where clients mutually train both a general FL model and a group-level one per modality. Our evaluation shows that this method leads to only a 7-13% decrease in accuracy, making it possible to build HAR systems with diverse hardware.
Sampling Based On Natural Image Statistics Improves Local Surrogate Explainers
Aug 08, 2022


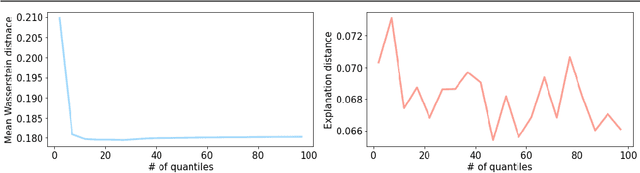
Many problems in computer vision have recently been tackled using models whose predictions cannot be easily interpreted, most commonly deep neural networks. Surrogate explainers are a popular post-hoc interpretability method to further understand how a model arrives at a particular prediction. By training a simple, more interpretable model to locally approximate the decision boundary of a non-interpretable system, we can estimate the relative importance of the input features on the prediction. Focusing on images, surrogate explainers, e.g., LIME, generate a local neighbourhood around a query image by sampling in an interpretable domain. However, these interpretable domains have traditionally been derived exclusively from the intrinsic features of the query image, not taking into consideration the manifold of the data the non-interpretable model has been exposed to in training (or more generally, the manifold of real images). This leads to suboptimal surrogates trained on potentially low probability images. We address this limitation by aligning the local neighbourhood on which the surrogate is trained with the original training data distribution, even when this distribution is not accessible. We propose two approaches to do so, namely (1) altering the method for sampling the local neighbourhood and (2) using perceptual metrics to convey some of the properties of the distribution of natural images.
Model-Based Reinforcement Learning for Type 1Diabetes Blood Glucose Control
Oct 13, 2020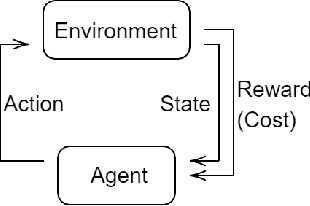
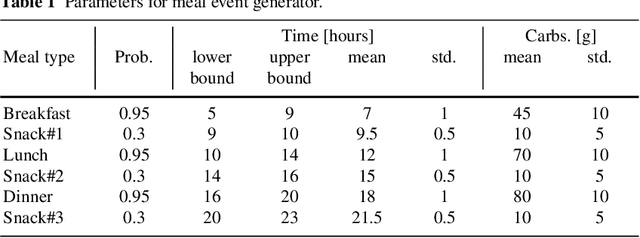
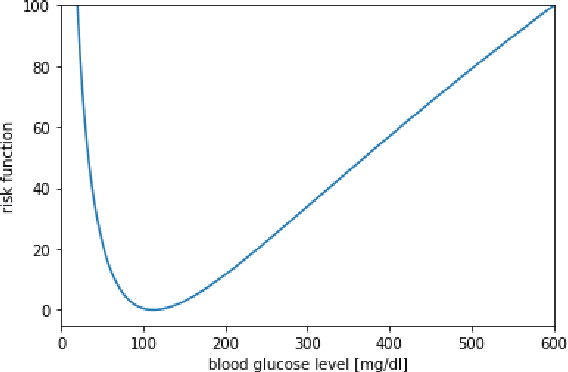
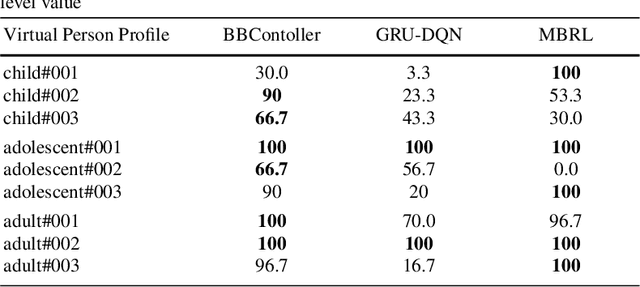
In this paper we investigate the use of model-based reinforcement learning to assist people with Type 1 Diabetes with insulin dose decisions. The proposed architecture consists of multiple Echo State Networks to predict blood glucose levels combined with Model Predictive Controller for planning. Echo State Network is a version of recurrent neural networks which allows us to learn long term dependencies in the input of time series data in an online manner. Additionally, we address the quantification of uncertainty for a more robust control. Here, we used ensembles of Echo State Networks to capture model (epistemic) uncertainty. We evaluated the approach with the FDA-approved UVa/Padova Type 1 Diabetes simulator and compared the results against baseline algorithms such as Basal-Bolus controller and Deep Q-learning. The results suggest that the model-based reinforcement learning algorithm can perform equally or better than the baseline algorithms for the majority of virtual Type 1 Diabetes person profiles tested.
Online Feature Selection for Activity Recognition using Reinforcement Learning with Multiple Feedback
Aug 16, 2019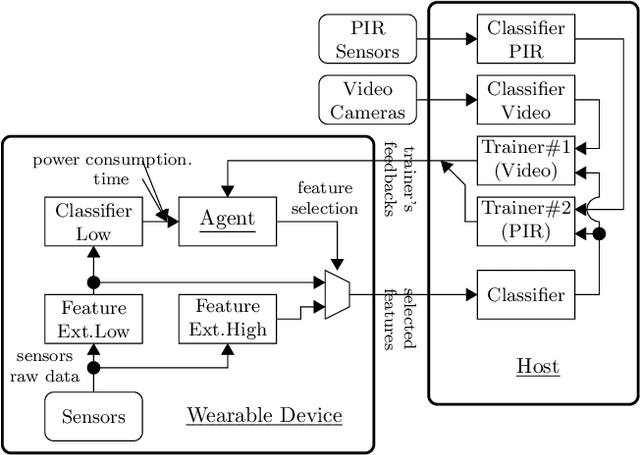
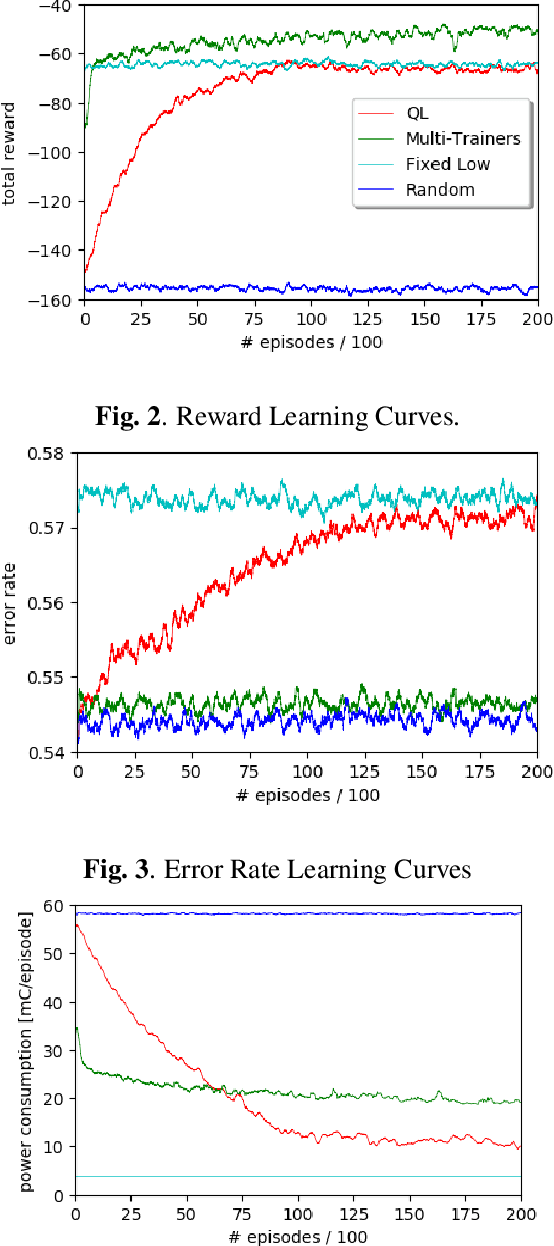
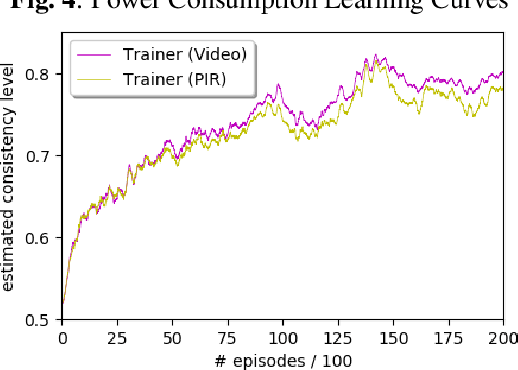
Recent advances in both machine learning and Internet-of-Things have attracted attention to automatic Activity Recognition, where users wear a device with sensors and their outputs are mapped to a predefined set of activities. However, few studies have considered the balance between wearable power consumption and activity recognition accuracy. This is particularly important when part of the computational load happens on the wearable device. In this paper, we present a new methodology to perform feature selection on the device based on Reinforcement Learning (RL) to find the optimum balance between power consumption and accuracy. To accelerate the learning speed, we extend the RL algorithm to address multiple sources of feedback, and use them to tailor the policy in conjunction with estimating the feedback accuracy. We evaluated our system on the SPHERE challenge dataset, a publicly available research dataset. The results show that our proposed method achieves a good trade-off between wearable power consumption and activity recognition accuracy.
Ordinal Regression as Structured Classification
May 31, 2019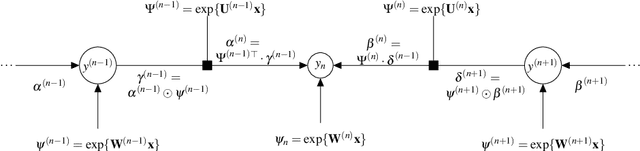
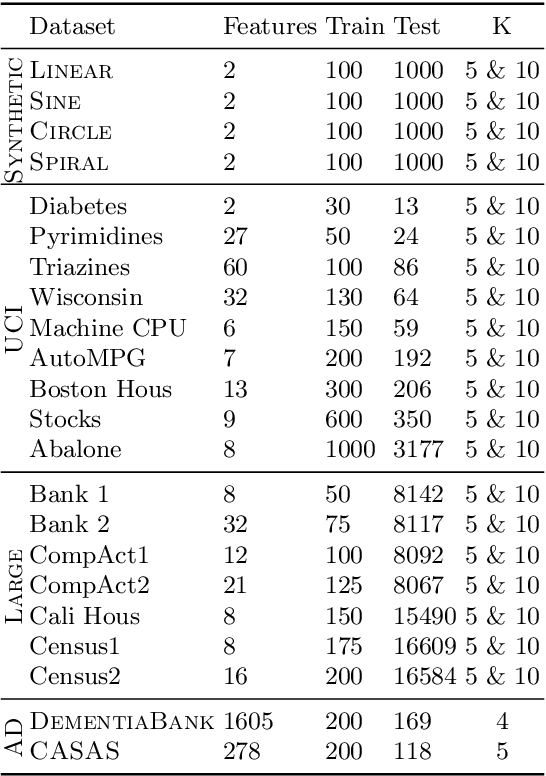
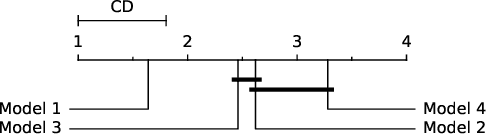
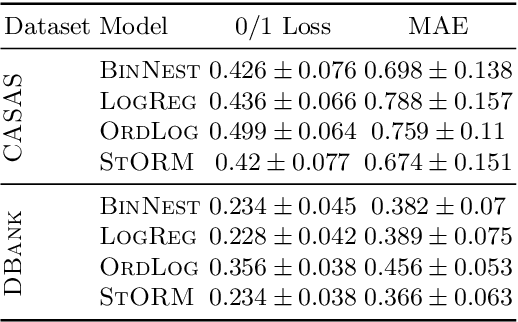
This paper extends the class of ordinal regression models with a structured interpretation of the problem by applying a novel treatment of encoded labels. The net effect of this is to transform the underlying problem from an ordinal regression task to a (structured) classification task which we solve with conditional random fields, thereby achieving a coherent and probabilistic model in which all model parameters are jointly learnt. Importantly, we show that although we have cast ordinal regression to classification, our method still fall within the class of decomposition methods in the ordinal regression ontology. This is an important link since our experience is that many applications of machine learning to healthcare ignores completely the important nature of the label ordering, and hence these approaches should considered naive in this ontology. We also show that our model is flexible both in how it adapts to data manifolds and in terms of the operations that are available for practitioner to execute. Our empirical evaluation demonstrates that the proposed approach overwhelmingly produces superior and often statistically significant results over baseline approaches on forty popular ordinal regression models, and demonstrate that the proposed model significantly out-performs baselines on synthetic and real datasets. Our implementation, together with scripts to reproduce the results of this work, will be available on a public GitHub repository.