 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Requirements of Clinicians for Explainable AI Decision Support Systems in Intensive Care
Nov 18, 2024There is a growing need to understand how digital systems can support clinical decision-making, particularly as artificial intelligence (AI) models become increasingly complex and less human-interpretable. This complexity raises concerns about trustworthiness, impacting safe and effective adoption of such technologies. Improved understanding of decision-making processes and requirements for explanations coming from decision support tools is a vital component in providing effective explainable solutions. This is particularly relevant in the data-intensive, fast-paced environments of intensive care units (ICUs). To explore these issues, group interviews were conducted with seven ICU clinicians, representing various roles and experience levels. Thematic analysis revealed three core themes: (T1) ICU decision-making relies on a wide range of factors, (T2) the complexity of patient state is challenging for shared decision-making, and (T3) requirements and capabilities of AI decision support systems. We include design recommendations from clinical input, providing insights to inform future AI systems for intensive care.
Towards Personalised Patient Risk Prediction Using Temporal Hospital Data Trajectories
Jul 12, 2024Quantifying a patient's health status provides clinicians with insight into patient risk, and the ability to better triage and manage resources. Early Warning Scores (EWS) are widely deployed to measure overall health status, and risk of adverse outcomes, in hospital patients. However, current EWS are limited both by their lack of personalisation and use of static observations. We propose a pipeline that groups intensive care unit patients by the trajectories of observations data throughout their stay as a basis for the development of personalised risk predictions. Feature importance is considered to provide model explainability. Using the MIMIC-IV dataset, six clusters were identified, capturing differences in disease codes, observations, lengths of admissions and outcomes. Applying the pipeline to data from just the first four hours of each ICU stay assigns the majority of patients to the same cluster as when the entire stay duration is considered. In-hospital mortality prediction models trained on individual clusters had higher F1 score performance in five of the six clusters when compared against the unclustered patient cohort. The pipeline could form the basis of a clinical decision support tool, working to improve the clinical characterisation of risk groups and the early detection of patient deterioration.
Monitoring Sustainable Global Development Along Shared Socioeconomic Pathways
Dec 07, 2023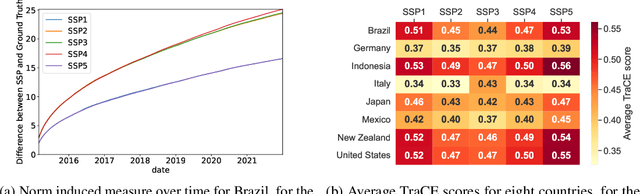
Sustainable global development is one of the most prevalent challenges facing the world today, hinging on the equilibrium between socioeconomic growth and environmental sustainability. We propose approaches to monitor and quantify sustainable development along the Shared Socioeconomic Pathways (SSPs), including mathematically derived scoring algorithms, and machine learning methods. These integrate socioeconomic and environmental datasets, to produce an interpretable metric for SSP alignment. An initial study demonstrates promising results, laying the groundwork for the application of different methods to the monitoring of sustainable global development.
TraCE: Trajectory Counterfactual Explanation Scores
Sep 27, 2023Counterfactual explanations, and their associated algorithmic recourse, are typically leveraged to understand, explain, and potentially alter a prediction coming from a black-box classifier. In this paper, we propose to extend the use of counterfactuals to evaluate progress in sequential decision making tasks. To this end, we introduce a model-agnostic modular framework, TraCE (Trajectory Counterfactual Explanation) scores, which is able to distill and condense progress in highly complex scenarios into a single value. We demonstrate TraCE's utility across domains by showcasing its main properties in two case studies spanning healthcare and climate change.
Counterfactual Explanations via Locally-guided Sequential Algorithmic Recourse
Sep 08, 2023Counterfactuals operationalised through algorithmic recourse have become a powerful tool to make artificial intelligence systems explainable. Conceptually, given an individual classified as y -- the factual -- we seek actions such that their prediction becomes the desired class y' -- the counterfactual. This process offers algorithmic recourse that is (1) easy to customise and interpret, and (2) directly aligned with the goals of each individual. However, the properties of a "good" counterfactual are still largely debated; it remains an open challenge to effectively locate a counterfactual along with its corresponding recourse. Some strategies use gradient-driven methods, but these offer no guarantees on the feasibility of the recourse and are open to adversarial attacks on carefully created manifolds. This can lead to unfairness and lack of robustness. Other methods are data-driven, which mostly addresses the feasibility problem at the expense of privacy, security and secrecy as they require access to the entire training data set. Here, we introduce LocalFACE, a model-agnostic technique that composes feasible and actionable counterfactual explanations using locally-acquired information at each step of the algorithmic recourse. Our explainer preserves the privacy of users by only leveraging data that it specifically requires to construct actionable algorithmic recourse, and protects the model by offering transparency solely in the regions deemed necessary for the intervention.
Identification, explanation and clinical evaluation of hospital patient subtypes
Jan 19, 2023We present a pipeline in which unsupervised machine learning techniques are used to automatically identify subtypes of hospital patients admitted between 2017 and 2021 in a large UK teaching hospital. With the use of state-of-the-art explainability techniques, the identified subtypes are interpreted and assigned clinical meaning. In parallel, clinicians assessed intra-cluster similarities and inter-cluster differences of the identified patient subtypes within the context of their clinical knowledge. By confronting the outputs of both automatic and clinician-based explanations, we aim to highlight the mutual benefit of combining machine learning techniques with clinical expertise.