 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Negative Sampling for Implicit Collaborative Filtering
Aug 20, 2025



Implicit collaborative filtering recommenders are usually trained to learn user positive preferences. Negative sampling, which selects informative negative items to form negative training data, plays a crucial role in this process. Since items are often clustered in the latent space, existing negative sampling strategies normally oversample negative items from the dense regions. This leads to homogeneous negative data and limited model expressiveness. In this paper, we propose Diverse Negative Sampling (DivNS), a novel approach that explicitly accounts for diversity in negative training data during the negative sampling process. DivNS first finds hard negative items with large preference scores and constructs user-specific caches that store unused but highly informative negative samples. Then, its diversity-augmented sampler selects a diverse subset of negative items from the cache while ensuring dissimilarity from the user's hard negatives. Finally, a synthetic negatives generator combines the selected diverse negatives with hard negatives to form more effective training data. The resulting synthetic negatives are both informative and diverse, enabling recommenders to learn a broader item space and improve their generalisability. Extensive experiments on four public datasets demonstrate the effectiveness of DivNS in improving recommendation quality while maintaining computational efficiency.
Artificial Intelligence Should Genuinely Support Clinical Reasoning and Decision Making To Bridge the Translational Gap
Jun 05, 2025Artificial intelligence promises to revolutionise medicine, yet its impact remains limited because of the pervasive translational gap. We posit that the prevailing technology-centric approaches underpin this challenge, rendering such systems fundamentally incompatible with clinical practice, specifically diagnostic reasoning and decision making. Instead, we propose a novel sociotechnical conceptualisation of data-driven support tools designed to complement doctors' cognitive and epistemic activities. Crucially, it prioritises real-world impact over superhuman performance on inconsequential benchmarks.
All You Need for Counterfactual Explainability Is Principled and Reliable Estimate of Aleatoric and Epistemic Uncertainty
Feb 24, 2025This position paper argues that, to its detriment, transparency research overlooks many foundational concepts of artificial intelligence. Here, we focus on uncertainty quantification -- in the context of ante-hoc interpretability and counterfactual explainability -- showing how its adoption could address key challenges in the field. First, we posit that uncertainty and ante-hoc interpretability offer complementary views of the same underlying idea; second, we assert that uncertainty provides a principled unifying framework for counterfactual explainability. Consequently, inherently transparent models can benefit from human-centred explanatory insights -- like counterfactuals -- which are otherwise missing. At a higher level, integrating artificial intelligence fundamentals into transparency research promises to yield more reliable, robust and understandable predictive models.
Perfect Counterfactuals in Imperfect Worlds: Modelling Noisy Implementation of Actions in Sequential Algorithmic Recourse
Oct 03, 2024Algorithmic recourse provides actions to individuals who have been adversely affected by automated decision-making and helps them achieve a desired outcome. Knowing the recourse, however, does not guarantee that users would implement it perfectly, either due to environmental variability or personal choices. Recourse generation should thus anticipate its sub-optimal or noisy implementation. While several approaches have constructed recourse that accounts for robustness to small perturbation (i.e., noisy recourse implementation), they assume an entire recourse to be implemented in a single step and thus apply one-off uniform noise to it. Such assumption is unrealistic since recourse often includes multiple sequential steps which becomes harder to implement and subject to more noise. In this work, we consider recourse under plausible noise that adapts to the local data geometry and accumulates at every step of the way. We frame this problem as a Markov Decision Process and demonstrate that the distribution of our plausible noise satisfies the Markov property. We then propose the RObust SEquential (ROSE) recourse generator to output a sequence of steps that will lead to the desired outcome even under imperfect implementation. Given our plausible modelling of sub-optimal human actions and greater recourse robustness to accumulated uncertainty, ROSE can grant users higher chances of success under low recourse costs. Empirical evaluation shows our algorithm manages the inherent trade-off between recourse robustness and costs more effectively while ensuring its low sparsity and fast computation.
What Does Evaluation of Explainable Artificial Intelligence Actually Tell Us? A Case for Compositional and Contextual Validation of XAI Building Blocks
Mar 19, 2024Despite significant progress, evaluation of explainable artificial intelligence remains elusive and challenging. In this paper we propose a fine-grained validation framework that is not overly reliant on any one facet of these sociotechnical systems, and that recognises their inherent modular structure: technical building blocks, user-facing explanatory artefacts and social communication protocols. While we concur that user studies are invaluable in assessing the quality and effectiveness of explanation presentation and delivery strategies from the explainees' perspective in a particular deployment context, the underlying explanation generation mechanisms require a separate, predominantly algorithmic validation strategy that accounts for the technical and human-centred desiderata of their (numerical) outputs. Such a comprehensive sociotechnical utility-based evaluation framework could allow to systematically reason about the properties and downstream influence of different building blocks from which explainable artificial intelligence systems are composed -- accounting for a diverse range of their engineering and social aspects -- in view of the anticipated use case.
Counterfactual Explanations via Locally-guided Sequential Algorithmic Recourse
Sep 08, 2023Counterfactuals operationalised through algorithmic recourse have become a powerful tool to make artificial intelligence systems explainable. Conceptually, given an individual classified as y -- the factual -- we seek actions such that their prediction becomes the desired class y' -- the counterfactual. This process offers algorithmic recourse that is (1) easy to customise and interpret, and (2) directly aligned with the goals of each individual. However, the properties of a "good" counterfactual are still largely debated; it remains an open challenge to effectively locate a counterfactual along with its corresponding recourse. Some strategies use gradient-driven methods, but these offer no guarantees on the feasibility of the recourse and are open to adversarial attacks on carefully created manifolds. This can lead to unfairness and lack of robustness. Other methods are data-driven, which mostly addresses the feasibility problem at the expense of privacy, security and secrecy as they require access to the entire training data set. Here, we introduce LocalFACE, a model-agnostic technique that composes feasible and actionable counterfactual explanations using locally-acquired information at each step of the algorithmic recourse. Our explainer preserves the privacy of users by only leveraging data that it specifically requires to construct actionable algorithmic recourse, and protects the model by offering transparency solely in the regions deemed necessary for the intervention.
Navigating Explanatory Multiverse Through Counterfactual Path Geometry
Jun 05, 2023


Counterfactual explanations are the de facto standard when tasked with interpreting decisions of (opaque) predictive models. Their generation is often subject to algorithmic and domain-specific constraints -- such as density-based feasibility for the former and attribute (im)mutability or directionality of change for the latter -- that aim to maximise their real-life utility. In addition to desiderata with respect to the counterfactual instance itself, the existence of a viable path connecting it with the factual data point, known as algorithmic recourse, has become an important technical consideration. While both of these requirements ensure that the steps of the journey as well as its destination are admissible, current literature neglects the multiplicity of such counterfactual paths. To address this shortcoming we introduce the novel concept of explanatory multiverse that encompasses all the possible counterfactual journeys and shows how to navigate, reason about and compare the geometry of these paths -- their affinity, branching, divergence and possible future convergence -- with two methods: vector spaces and graphs. Implementing this (interactive) explanatory process grants explainees more agency by allowing them to select counterfactuals based on the properties of the journey leading to them in addition to their absolute differences.
(Un)reasonable Allure of Ante-hoc Interpretability for High-stakes Domains: Transparency Is Necessary but Insufficient for Explainability
Jun 04, 2023
Ante-hoc interpretability has become the holy grail of explainable machine learning for high-stakes domains such as healthcare; however, this notion is elusive, lacks a widely-accepted definition and depends on the deployment context. It can refer to predictive models whose structure adheres to domain-specific constraints, or ones that are inherently transparent. The latter notion assumes observers who judge this quality, whereas the former presupposes them to have technical and domain expertise, in certain cases rendering such models unintelligible. Additionally, its distinction from the less desirable post-hoc explainability, which refers to methods that construct a separate explanatory model, is vague given that transparent predictors may still require (post-)processing to yield satisfactory explanatory insights. Ante-hoc interpretability is thus an overloaded concept that comprises a range of implicit properties, which we unpack in this paper to better understand what is needed for its safe deployment across high-stakes domains. To this end, we outline model- and explainer-specific desiderata that allow us to navigate its distinct realisations in view of the envisaged application and audience.
Equalised Odds is not Equal Individual Odds: Post-processing for Group and Individual Fairness
Apr 19, 2023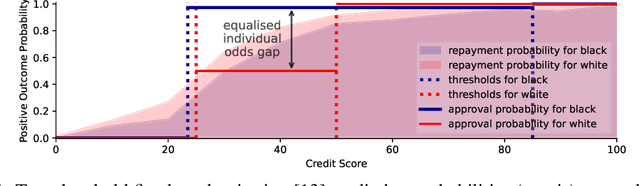



Group fairness is achieved by equalising prediction distributions between protected sub-populations; individual fairness requires treating similar individuals alike. These two objectives, however, are incompatible when a scoring model is calibrated through discontinuous probability functions, where individuals can be randomly assigned an outcome determined by a fixed probability. This procedure may provide two similar individuals from the same protected group with classification odds that are disparately different -- a clear violation of individual fairness. Assigning unique odds to each protected sub-population may also prevent members of one sub-population from ever receiving equal chances of a positive outcome to another, which we argue is another type of unfairness called individual odds. We reconcile all this by constructing continuous probability functions between group thresholds that are constrained by their Lipschitz constant. Our solution preserves the model's predictive power, individual fairness and robustness while ensuring group fairness.
More Is Less: When Do Recommenders Underperform for Data-rich Users?
Apr 15, 2023Users of recommender systems tend to differ in their level of interaction with these algorithms, which may affect the quality of recommendations they receive and lead to undesirable performance disparity. In this paper we investigate under what conditions the performance for data-rich and data-poor users diverges for a collection of popular evaluation metrics applied to ten benchmark datasets. We find that Precision is consistently higher for data-rich users across all the datasets; Mean Average Precision is comparable across user groups but its variance is large; Recall yields a counter-intuitive result where the algorithm performs better for data-poor than for data-rich users, which bias is further exacerbated when negative item sampling is employed during evaluation. The final observation suggests that as users interact more with recommender systems, the quality of recommendations they receive degrades (when measured by Recall). Our insights clearly show the importance of an evaluation protocol and its influence on the reported results when studying recommender systems.