 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUB: An LLM-Enhanced Personality-Driven User Behaviour Simulator for Recommender System Evaluation
Jun 05, 2025Traditional offline evaluation methods for recommender systems struggle to capture the complexity of modern platforms due to sparse behavioural signals, noisy data, and limited modelling of user personality traits. While simulation frameworks can generate synthetic data to address these gaps, existing methods fail to replicate behavioural diversity, limiting their effectiveness. To overcome these challenges, we propose the Personality-driven User Behaviour Simulator (PUB), an LLM-based simulation framework that integrates the Big Five personality traits to model personalised user behaviour. PUB dynamically infers user personality from behavioural logs (e.g., ratings, reviews) and item metadata, then generates synthetic interactions that preserve statistical fidelity to real-world data. Experiments on the Amazon review datasets show that logs generated by PUB closely align with real user behaviour and reveal meaningful associations between personality traits and recommendation outcomes. These results highlight the potential of the personality-driven simulator to advance recommender system evaluation, offering scalable, controllable, high-fidelity alternatives to resource-intensive real-world experiments.
Multi-stage Large Language Model Pipelines Can Outperform GPT-4o in Relevance Assessment
Jan 24, 2025



The effectiveness of search systems is evaluated using relevance labels that indicate the usefulness of documents for specific queries and users. While obtaining these relevance labels from real users is ideal, scaling such data collection is challenging. Consequently, third-party annotators are employed, but their inconsistent accuracy demands costly auditing, training, and monitoring. We propose an LLM-based modular classification pipeline that divides the relevance assessment task into multiple stages, each utilising different prompts and models of varying sizes and capabilities. Applied to TREC Deep Learning (TREC-DL), one of our approaches showed an 18.4% Krippendorff's $\alpha$ accuracy increase over OpenAI's GPT-4o mini while maintaining a cost of about 0.2 USD per million input tokens, offering a more efficient and scalable solution for relevance assessment. This approach beats the baseline performance of GPT-4o (5 USD). With a pipeline approach, even the accuracy of the GPT-4o flagship model, measured in $\alpha$, could be improved by 9.7%.
Towards Detecting and Mitigating Cognitive Bias in Spoken Conversational Search
May 21, 2024Instruments such as eye-tracking devices have contributed to understanding how users interact with screen-based search engines. However, user-system interactions in audio-only channels -- as is the case for Spoken Conversational Search (SCS) -- are harder to characterize, given the lack of instruments to effectively and precisely capture interactions. Furthermore, in this era of information overload, cognitive bias can significantly impact how we seek and consume information -- especially in the context of controversial topics or multiple viewpoints. This paper draws upon insights from multiple disciplines (including information seeking, psychology, cognitive science, and wearable sensors) to provoke novel conversations in the community. To this end, we discuss future opportunities and propose a framework including multimodal instruments and methods for experimental designs and settings. We demonstrate preliminary results as an example. We also outline the challenges and offer suggestions for adopting this multimodal approach, including ethical considerations, to assist future researchers and practitioners in exploring cognitive biases in SCS.
Characterizing Information Seeking Processes with Multiple Physiological Signals
May 01, 2024Information access systems are getting complex, and our understanding of user behavior during information seeking processes is mainly drawn from qualitative methods, such as observational studies or surveys. Leveraging the advances in sensing technologies, our study aims to characterize user behaviors with physiological signals, particularly in relation to cognitive load, affective arousal, and valence. We conduct a controlled lab study with 26 participants, and collect data including Electrodermal Activities, Photoplethysmogram, Electroencephalogram, and Pupillary Responses. This study examines informational search with four stages: the realization of Information Need (IN), Query Formulation (QF), Query Submission (QS), and Relevance Judgment (RJ). We also include different interaction modalities to represent modern systems, e.g., QS by text-typing or verbalizing, and RJ with text or audio information. We analyze the physiological signals across these stages and report outcomes of pairwise non-parametric repeated-measure statistical tests. The results show that participants experience significantly higher cognitive loads at IN with a subtle increase in alertness, while QF requires higher attention. QS involves demanding cognitive loads than QF. Affective responses are more pronounced at RJ than QS or IN, suggesting greater interest and engagement as knowledge gaps are resolved. To the best of our knowledge, this is the first study that explores user behaviors in a search process employing a more nuanced quantitative analysis of physiological signals. Our findings offer valuable insights into user behavior and emotional responses in information seeking processes. We believe our proposed methodology can inform the characterization of more complex processes, such as conversational information seeking.
Walert: Putting Conversational Search Knowledge into Action by Building and Evaluating a Large Language Model-Powered Chatbot
Jan 14, 2024


Creating and deploying customized applications is crucial for operational success and enriching user experiences in the rapidly evolving modern business world. A prominent facet of modern user experiences is the integration of chatbots or voice assistants. The rapid evolution of Large Language Models (LLMs) has provided a powerful tool to build conversational applications. We present Walert, a customized LLM-based conversational agent able to answer frequently asked questions about computer science degrees and programs at RMIT University. Our demo aims to showcase how conversational information-seeking researchers can effectively communicate the benefits of using best practices to stakeholders interested in developing and deploying LLM-based chatbots. These practices are well-known in our community but often overlooked by practitioners who may not have access to this knowledge. The methodology and resources used in this demo serve as a bridge to facilitate knowledge transfer from experts, address industry professionals' practical needs, and foster a collaborative environment. The data and code of the demo are available at https://github.com/rmit-ir/walert.
Designing and Evaluating Presentation Strategies for Fact-Checked Content
Aug 20, 2023



With the rapid growth of online misinformation, it is crucial to have reliable fact-checking methods. Recent research on finding check-worthy claims and automated fact-checking have made significant advancements. However, limited guidance exists regarding the presentation of fact-checked content to effectively convey verified information to users. We address this research gap by exploring the critical design elements in fact-checking reports and investigating whether credibility and presentation-based design improvements can enhance users' ability to interpret the report accurately. We co-developed potential content presentation strategies through a workshop involving fact-checking professionals, communication experts, and researchers. The workshop examined the significance and utility of elements such as veracity indicators and explored the feasibility of incorporating interactive components for enhanced information disclosure. Building on the workshop outcomes, we conducted an online experiment involving 76 crowd workers to assess the efficacy of different design strategies. The results indicate that proposed strategies significantly improve users' ability to accurately interpret the verdict of fact-checking articles. Our findings underscore the critical role of effective presentation of fact reports in addressing the spread of misinformation. By adopting appropriate design enhancements, the effectiveness of fact-checking reports can be maximized, enabling users to make informed judgments.
Examining the Impact of Uncontrolled Variables on Physiological Signals in User Studies for Information Processing Activities
Apr 26, 2023Physiological signals can potentially be applied as objective measures to understand the behavior and engagement of users interacting with information access systems. However, the signals are highly sensitive, and many controls are required in laboratory user studies. To investigate the extent to which controlled or uncontrolled (i.e., confounding) variables such as task sequence or duration influence the observed signals, we conducted a pilot study where each participant completed four types of information-processing activities (READ, LISTEN, SPEAK, and WRITE). Meanwhile, we collected data on blood volume pulse, electrodermal activity, and pupil responses. We then used machine learning approaches as a mechanism to examine the influence of controlled and uncontrolled variables that commonly arise in user studies. Task duration was found to have a substantial effect on the model performance, suggesting it represents individual differences rather than giving insight into the target variables. This work contributes to our understanding of such variables in using physiological signals in information retrieval user studies.
Helpful, Misleading or Confusing: How Humans Perceive Fundamental Building Blocks of Artificial Intelligence Explanations
Mar 02, 2023Explainable artificial intelligence techniques are evolving at breakneck speed, but suitable evaluation approaches currently lag behind. With explainers becoming increasingly complex and a lack of consensus on how to assess their utility, it is challenging to judge the benefit and effectiveness of different explanations. To address this gap, we take a step back from complex predictive algorithms and instead look into explainability of simple mathematical models. In this setting, we aim to assess how people perceive comprehensibility of different model representations such as mathematical formulation, graphical representation and textual summarisation (of varying scope). This allows diverse stakeholders -- engineers, researchers, consumers, regulators and the like -- to judge intelligibility of fundamental concepts that more complex artificial intelligence explanations are built from. This position paper charts our approach to establishing appropriate evaluation methodology as well as a conceptual and practical framework to facilitate setting up and executing relevant user studies.
Does a Face Mask Protect my Privacy?: Deep Learning to Predict Protected Attributes from Masked Face Images
Dec 15, 2021
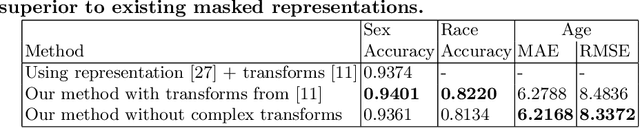
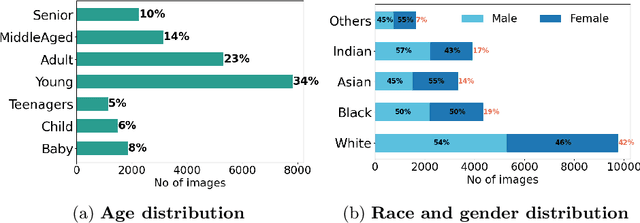
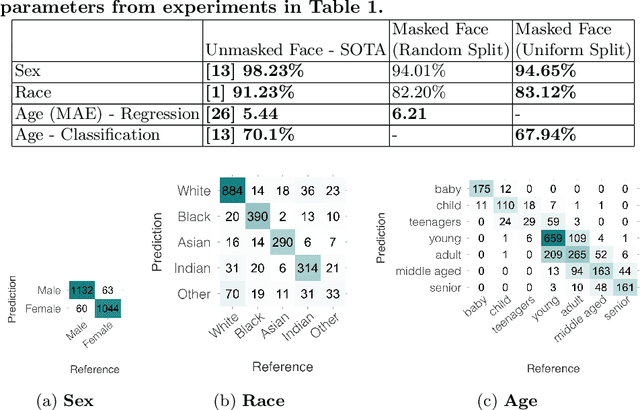
Contactless and efficient systems are implemented rapidly to advocate preventive methods in the fight against the COVID-19 pandemic. Despite the positive benefits of such systems, there is potential for exploitation by invading user privacy. In this work, we analyse the privacy invasiveness of face biometric systems by predicting privacy-sensitive soft-biometrics using masked face images. We train and apply a CNN based on the ResNet-50 architecture with 20,003 synthetic masked images and measure the privacy invasiveness. Despite the popular belief of the privacy benefits of wearing a mask among people, we show that there is no significant difference to privacy invasiveness when a mask is worn. In our experiments we were able to accurately predict sex (94.7%),race (83.1%) and age (MAE 6.21 and RMSE 8.33) from masked face images. Our proposed approach can serve as a baseline utility to evaluate the privacy-invasiveness of artificial intelligence systems that make use of privacy-sensitive information. We open-source all contributions for re-producibility and broader use by the research community.