 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Impact of Uncontrolled Variables on Physiological Signals in User Studies for Information Processing Activities
Apr 26, 2023Physiological signals can potentially be applied as objective measures to understand the behavior and engagement of users interacting with information access systems. However, the signals are highly sensitive, and many controls are required in laboratory user studies. To investigate the extent to which controlled or uncontrolled (i.e., confounding) variables such as task sequence or duration influence the observed signals, we conducted a pilot study where each participant completed four types of information-processing activities (READ, LISTEN, SPEAK, and WRITE). Meanwhile, we collected data on blood volume pulse, electrodermal activity, and pupil responses. We then used machine learning approaches as a mechanism to examine the influence of controlled and uncontrolled variables that commonly arise in user studies. Task duration was found to have a substantial effect on the model performance, suggesting it represents individual differences rather than giving insight into the target variables. This work contributes to our understanding of such variables in using physiological signals in information retrieval user studies.
Ethical and Fairness Implications of Model Multiplicity
Mar 14, 2022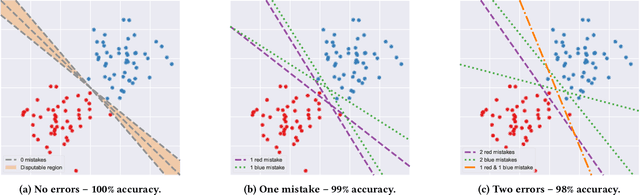

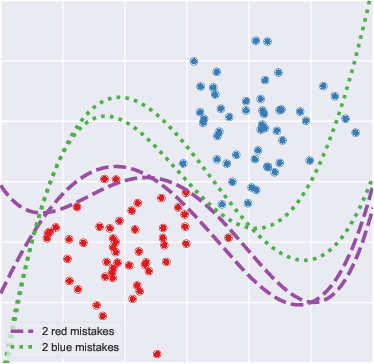

While predictive models are a purely technological feat, they may operate in a social context in which benign engineering choices entail unexpected real-life consequences. Fairness -- pertaining both to individuals and groups -- is one of such considerations; it surfaces when data capture protected characteristics of people who may be discriminated upon these attributes. This notion has predominantly been studied for a fixed predictive model, sometimes under different classification thresholds, striving to identify and eradicate its undesirable behaviour. Here we backtrack on this assumption and explore a novel definition of fairness where individuals can be harmed when one predictor is chosen ad hoc from a group of equally well performing models, i.e., in view of model multiplicity. Since a person may be classified differently across models that are otherwise considered equivalent, this individual could argue for a model with a more favourable outcome, possibly causing others to be adversely affected. We introduce this scenario with a two-dimensional example based on linear classification; then investigate its analytical properties in a broader context; and finally present experimental results on data sets popular in fairness studies. Our findings suggest that such unfairness can be found in real-life situations and may be difficult to mitigate with technical measures alone, as doing so degrades certain metrics of predictive performance.
FADACS: A Few-shot Adversarial Domain Adaptation Architecture for Context-Aware Parking Availability Sensing
Jul 13, 2020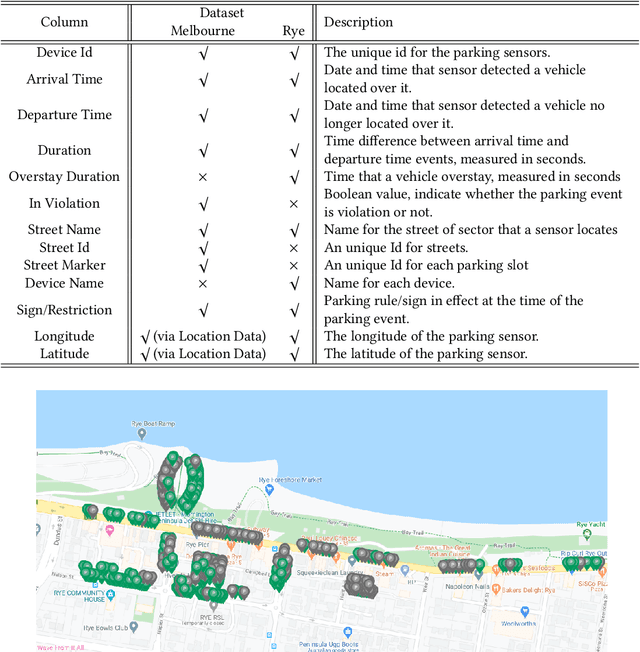
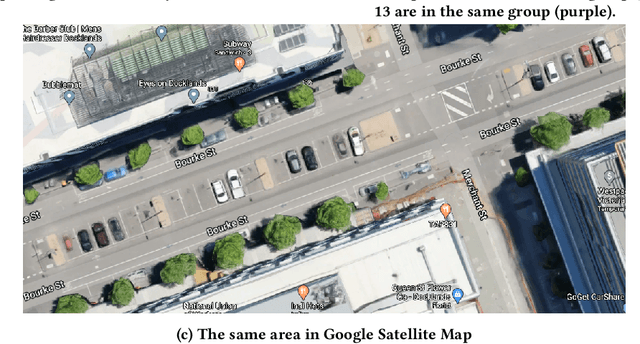

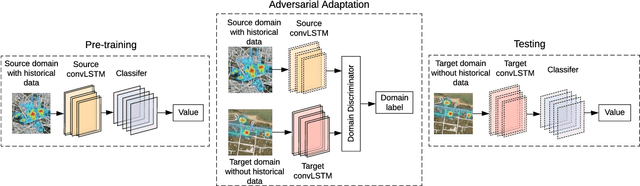
The existing research on parking availability sensing mainly relies on extensive contextual and historical information. In practice, it is challenging to have such information available as it requires continuous collection of sensory signals. In this paper, we design an end-to-end transfer learning framework for parking availability sensing to predict the parking occupancy in areas where the parking data is insufficient to feed into data-hungry models. This framework overcomes two main challenges: 1) many real-world cases cannot provide enough data for most existing data-driven models. 2) it is difficult to merge sensor data and heterogeneous contextual information due to the differing urban fabric and spatial characteristics. Our work adopts a widely-used concept called adversarial domain adaptation to predict the parking occupancy in an area without abundant sensor data by leveraging data from other areas with similar features. In this paper, we utilise more than 35 million parking data records from sensors placed in two different cities, one is a city centre, and another one is a coastal tourist town. We also utilise heterogeneous spatio-temporal contextual information from external resources including weather and point of interests. We quantify the strength of our proposed framework in different cases and compare it to the existing data-driven approaches. The results show that the proposed framework outperforms existing methods and also provide a few valuable insights for parking availability prediction.