 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODEStream: A Buffer-Free Online Learning Framework with ODE-based Adaptor for Streaming Time Series Forecasting
Nov 11, 2024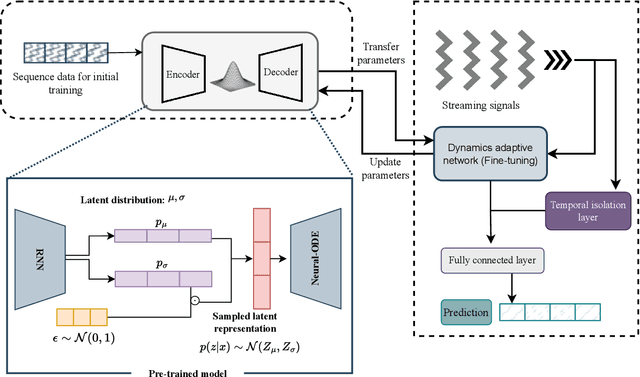

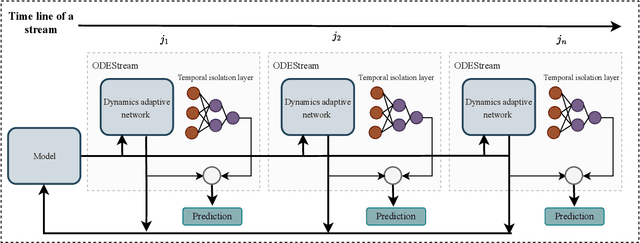
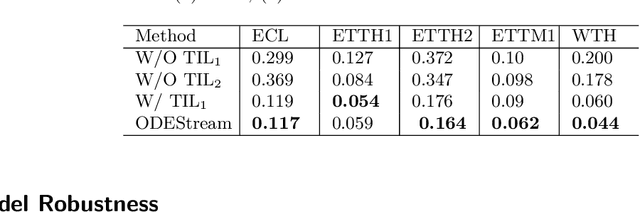
Addressing the challenges of irregularity and concept drift in streaming time series is crucial in real-world predictive modelling. Previous studies in time series continual learning often propose models that require buffering of long sequences, potentially restricting the responsiveness of the inference system. Moreover, these models are typically designed for regularly sampled data, an unrealistic assumption in real-world scenarios. This paper introduces ODEStream, a novel buffer-free continual learning framework that incorporates a temporal isolation layer that integrates temporal dependencies within the data. Simultaneously, it leverages the capability of neural ordinary differential equations to process irregular sequences and generate a continuous data representation, enabling seamless adaptation to changing dynamics in a data streaming scenario. Our approach focuses on learning how the dynamics and distribution of historical data change with time, facilitating the direct processing of streaming sequences. Evaluations on benchmark real-world datasets demonstrate that ODEStream outperforms the state-of-the-art online learning and streaming analysis baselines, providing accurate predictions over extended periods while minimising performance degradation over time by learning how the sequence dynamics change.
Walert: Putting Conversational Search Knowledge into Action by Building and Evaluating a Large Language Model-Powered Chatbot
Jan 14, 2024


Creating and deploying customized applications is crucial for operational success and enriching user experiences in the rapidly evolving modern business world. A prominent facet of modern user experiences is the integration of chatbots or voice assistants. The rapid evolution of Large Language Models (LLMs) has provided a powerful tool to build conversational applications. We present Walert, a customized LLM-based conversational agent able to answer frequently asked questions about computer science degrees and programs at RMIT University. Our demo aims to showcase how conversational information-seeking researchers can effectively communicate the benefits of using best practices to stakeholders interested in developing and deploying LLM-based chatbots. These practices are well-known in our community but often overlooked by practitioners who may not have access to this knowledge. The methodology and resources used in this demo serve as a bridge to facilitate knowledge transfer from experts, address industry professionals' practical needs, and foster a collaborative environment. The data and code of the demo are available at https://github.com/rmit-ir/walert.
CrossPyramid: Neural Ordinary Differential Equations Architecture for Partially-observed Time-series
Dec 07, 2022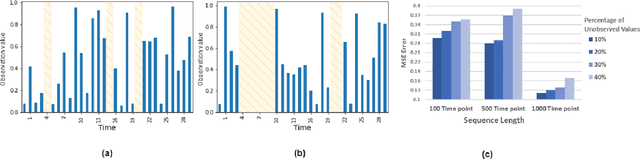
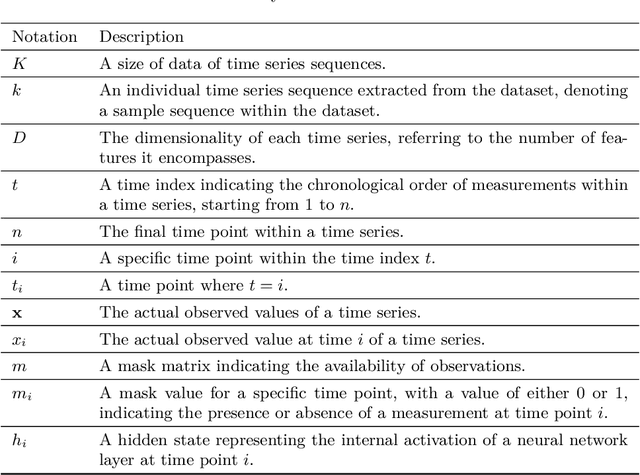
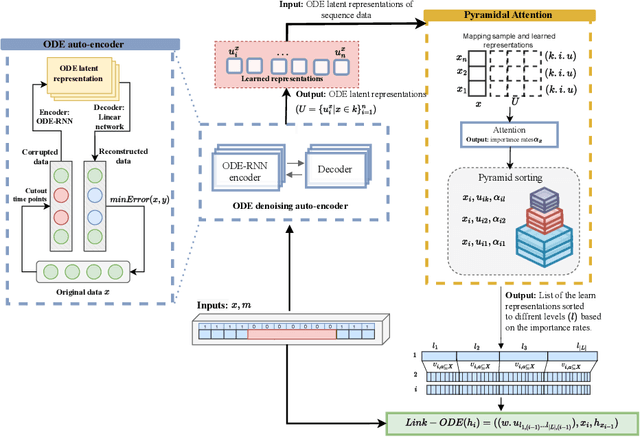
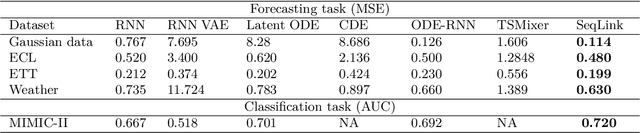
Ordinary Differential Equations (ODE)-based models have become popular foundation models to solve many time-series problems. Combining neural ODEs with traditional RNN models has provided the best representation for irregular time series. However, ODE-based models require the trajectory of hidden states to be defined based on the initial observed value or the last available observation. This fact raises questions about how long the generated hidden state is sufficient and whether it is effective when long sequences are used instead of the typically used shorter sequences. In this article, we introduce CrossPyramid, a novel ODE-based model that aims to enhance the generalizability of sequences representation. CrossPyramid does not rely only on the hidden state from the last observed value; it also considers ODE latent representations learned from other samples. The main idea of our proposed model is to define the hidden state for the unobserved values based on the non-linear correlation between samples. Accordingly, CrossPyramid is built with three distinctive parts: (1) ODE Auto-Encoder to learn the best data representation. (2) Pyramidal attention method to categorize the learned representations (hidden state) based on the relationship characteristics between samples. (3) Cross-level ODE-RNN to integrate the previously learned information and provide the final latent state for each sample. Through extensive experiments on partially-observed synthetic and real-world datasets, we show that the proposed architecture can effectively model the long gaps in intermittent series and outperforms state-of-the-art approaches. The results show an average improvement of 10\% on univariate and multivariate datasets for both forecasting and classification tasks.
PIETS: Parallelised Irregularity Encoders for Forecasting with Heterogeneous Time-Series
Oct 06, 2021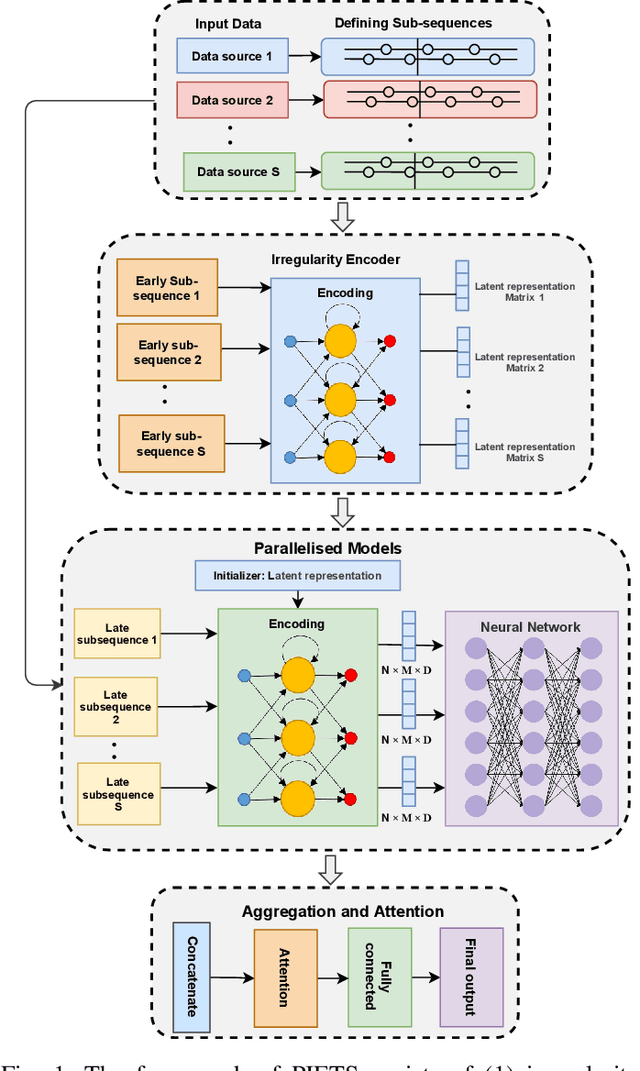



Heterogeneity and irregularity of multi-source data sets present a significant challenge to time-series analysis. In the literature, the fusion of multi-source time-series has been achieved either by using ensemble learning models which ignore temporal patterns and correlation within features or by defining a fixed-size window to select specific parts of the data sets. On the other hand, many studies have shown major improvement to handle the irregularity of time-series, yet none of these studies has been applied to multi-source data. In this work, we design a novel architecture, PIETS, to model heterogeneous time-series. PIETS has the following characteristics: (1) irregularity encoders for multi-source samples that can leverage all available information and accelerate the convergence of the model; (2) parallelised neural networks to enable flexibility and avoid information overwhelming; and (3) attention mechanism that highlights different information and gives high importance to the most related data. Through extensive experiments on real-world data sets related to COVID-19, we show that the proposed architecture is able to effectively model heterogeneous temporal data and outperforms other state-of-the-art approaches in the prediction task.