 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEX: Feature Importance from Layered Counterfactual Explanations
Nov 14, 2025

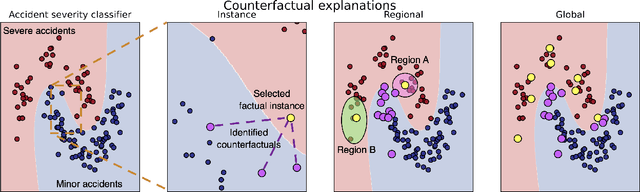

Machine learning models achieve state-of-the-art performance across domains, yet their lack of interpretability limits safe deployment in high-stakes settings. Counterfactual explanations are widely used to provide actionable "what-if" recourse, but they typically remain instance-specific and do not quantify which features systematically drive outcome changes within coherent regions of the feature space or across an entire dataset. We introduce FLEX (Feature importance from Layered counterfactual EXplanations), a model- and domain-agnostic framework that converts sets of counterfactuals into feature change frequency scores at local, regional, and global levels. FLEX generalises local change-frequency measures by aggregating across instances and neighbourhoods, offering interpretable rankings that reflect how often each feature must change to flip predictions. The framework is compatible with different counterfactual generation methods, allowing users to emphasise characteristics such as sparsity, feasibility, or actionability, thereby tailoring the derived feature importances to practical constraints. We evaluate FLEX on two contrasting tabular tasks: traffic accident severity prediction and loan approval, and compare FLEX to SHAP- and LIME-derived feature importance values. Results show that (i) FLEX's global rankings correlate with SHAP while surfacing additional drivers, and (ii) regional analyses reveal context-specific factors that global summaries miss. FLEX thus bridges the gap between local recourse and global attribution, supporting transparent and intervention-oriented decision-making in risk-sensitive applications.
Prototype-enhanced prediction in graph neural networks for climate applications
Apr 24, 2025


Data-driven emulators are increasingly being used to learn and emulate physics-based simulations, reducing computational expense and run time. Here, we present a structured way to improve the quality of these high-dimensional emulated outputs, through the use of prototypes: an approximation of the emulator's output passed as an input, which informs the model and leads to better predictions. We demonstrate our approach to emulate atmospheric dispersion, key for greenhouse gas emissions monitoring, by comparing a baseline model to models trained using prototypes as an additional input. The prototype models achieve better performance, even with few prototypes and even if they are chosen at random, but we show that choosing the prototypes through data-driven methods (k-means) can lead to almost 10\% increased performance in some metrics.
Exploring the Requirements of Clinicians for Explainable AI Decision Support Systems in Intensive Care
Nov 18, 2024There is a growing need to understand how digital systems can support clinical decision-making, particularly as artificial intelligence (AI) models become increasingly complex and less human-interpretable. This complexity raises concerns about trustworthiness, impacting safe and effective adoption of such technologies. Improved understanding of decision-making processes and requirements for explanations coming from decision support tools is a vital component in providing effective explainable solutions. This is particularly relevant in the data-intensive, fast-paced environments of intensive care units (ICUs). To explore these issues, group interviews were conducted with seven ICU clinicians, representing various roles and experience levels. Thematic analysis revealed three core themes: (T1) ICU decision-making relies on a wide range of factors, (T2) the complexity of patient state is challenging for shared decision-making, and (T3) requirements and capabilities of AI decision support systems. We include design recommendations from clinical input, providing insights to inform future AI systems for intensive care.
TraCE: Trajectory Counterfactual Explanation Scores
Sep 27, 2023Counterfactual explanations, and their associated algorithmic recourse, are typically leveraged to understand, explain, and potentially alter a prediction coming from a black-box classifier. In this paper, we propose to extend the use of counterfactuals to evaluate progress in sequential decision making tasks. To this end, we introduce a model-agnostic modular framework, TraCE (Trajectory Counterfactual Explanation) scores, which is able to distill and condense progress in highly complex scenarios into a single value. We demonstrate TraCE's utility across domains by showcasing its main properties in two case studies spanning healthcare and climate change.
Two-step counterfactual generation for OOD examples
Feb 10, 2023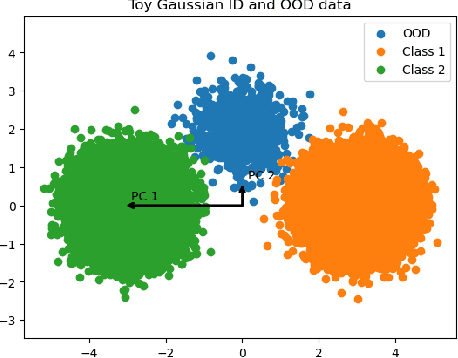
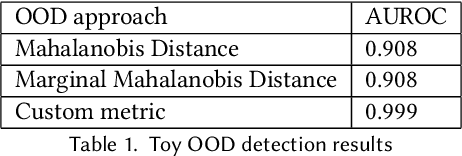
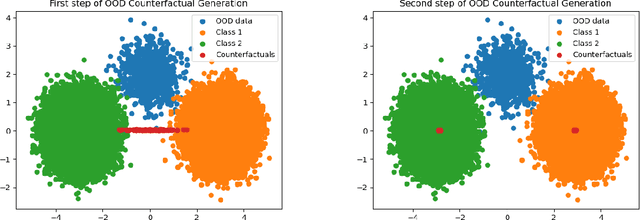
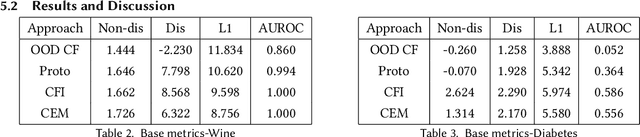
Two fundamental requirements for the deployment of machine learning models in safety-critical systems are to be able to detect out-of-distribution (OOD) data correctly and to be able to explain the prediction of the model. Although significant effort has gone into both OOD detection and explainable AI, there has been little work on explaining why a model predicts a certain data point is OOD. In this paper, we address this question by introducing the concept of an OOD counterfactual, which is a perturbed data point that iteratively moves between different OOD categories. We propose a method for generating such counterfactuals, investigate its application on synthetic and benchmark data, and compare it to several benchmark methods using a range of metrics.
Understanding the properties and limitations of contrastive learning for Out-of-Distribution detection
Nov 06, 2022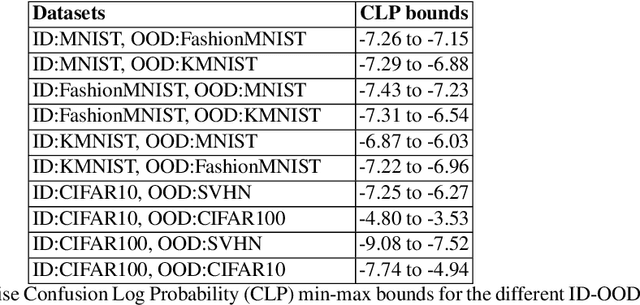
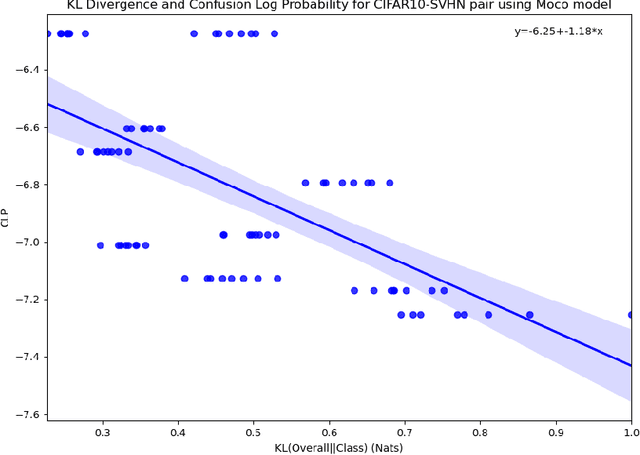
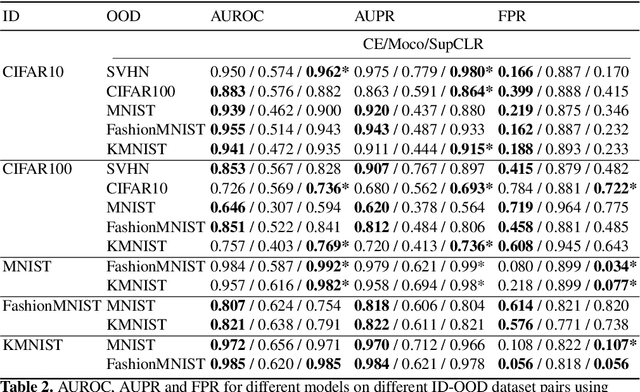
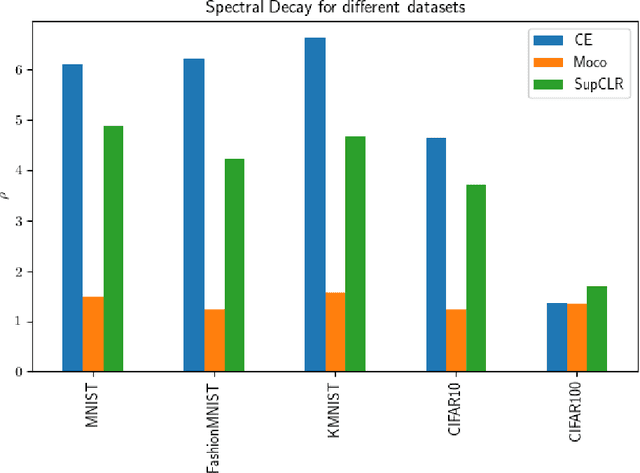
A recent popular approach to out-of-distribution (OOD) detection is based on a self-supervised learning technique referred to as contrastive learning. There are two main variants of contrastive learning, namely instance and class discrimination, targeting features that can discriminate between different instances for the former, and different classes for the latter. In this paper, we aim to understand the effectiveness and limitation of existing contrastive learning methods for OOD detection. We approach this in 3 ways. First, we systematically study the performance difference between the instance discrimination and supervised contrastive learning variants in different OOD detection settings. Second, we study which in-distribution (ID) classes OOD data tend to be classified into. Finally, we study the spectral decay property of the different contrastive learning approaches and examine how it correlates with OOD detection performance. In scenarios where the ID and OOD datasets are sufficiently different from one another, we see that instance discrimination, in the absence of fine-tuning, is competitive with supervised approaches in OOD detection. We see that OOD samples tend to be classified into classes that have a distribution similar to the distribution of the entire dataset. Furthermore, we show that contrastive learning learns a feature space that contains singular vectors containing several directions with a high variance which can be detrimental or beneficial to OOD detection depending on the inference approach used.