 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the properties and limitations of contrastive learning for Out-of-Distribution detection
Paper and Code
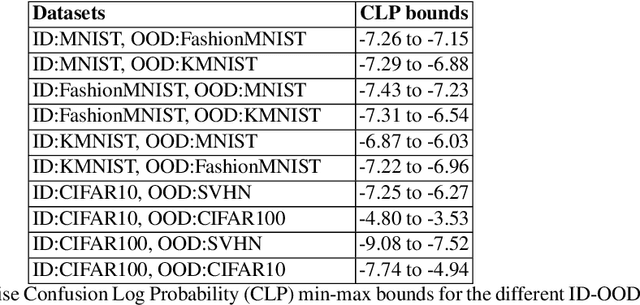
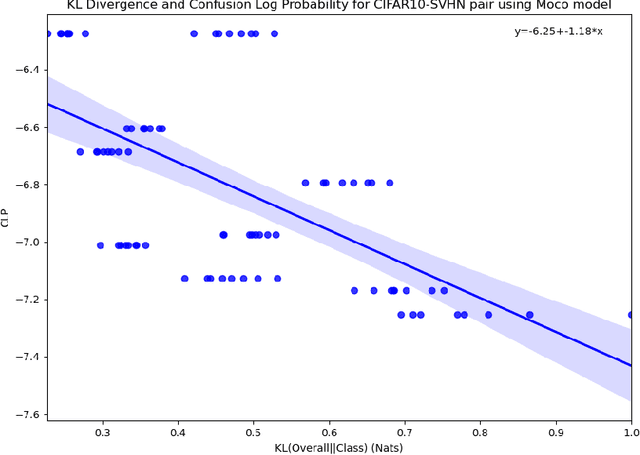
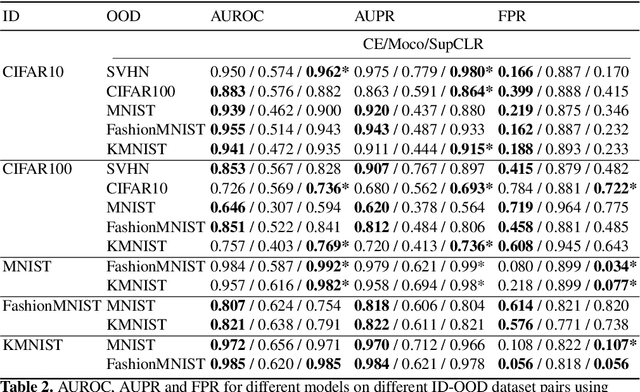
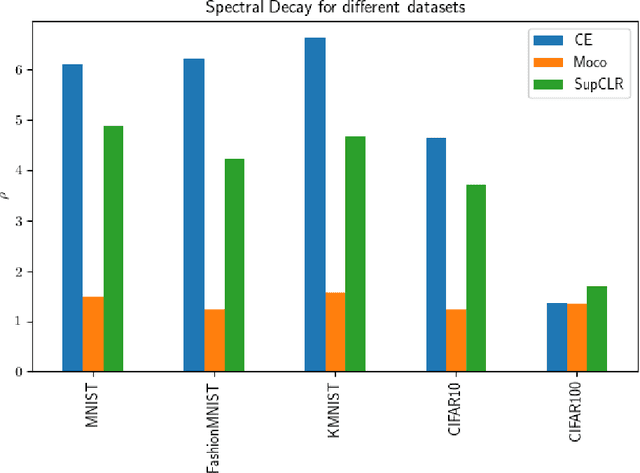
A recent popular approach to out-of-distribution (OOD) detection is based on a self-supervised learning technique referred to as contrastive learning. There are two main variants of contrastive learning, namely instance and class discrimination, targeting features that can discriminate between different instances for the former, and different classes for the latter. In this paper, we aim to understand the effectiveness and limitation of existing contrastive learning methods for OOD detection. We approach this in 3 ways. First, we systematically study the performance difference between the instance discrimination and supervised contrastive learning variants in different OOD detection settings. Second, we study which in-distribution (ID) classes OOD data tend to be classified into. Finally, we study the spectral decay property of the different contrastive learning approaches and examine how it correlates with OOD detection performance. In scenarios where the ID and OOD datasets are sufficiently different from one another, we see that instance discrimination, in the absence of fine-tuning, is competitive with supervised approaches in OOD detection. We see that OOD samples tend to be classified into classes that have a distribution similar to the distribution of the entire dataset. Furthermore, we show that contrastive learning learns a feature space that contains singular vectors containing several directions with a high variance which can be detrimental or beneficial to OOD detection depending on the inference approach used.