 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley Machine: A Game-Theoretic Framework for N-Agent Ad Hoc Teamwork
Jun 12, 2025Open multi-agent systems are increasingly important in modeling real-world applications, such as smart grids, swarm robotics, etc. In this paper, we aim to investigate a recently proposed problem for open multi-agent systems, referred to as n-agent ad hoc teamwork (NAHT), where only a number of agents are controlled. Existing methods tend to be based on heuristic design and consequently lack theoretical rigor and ambiguous credit assignment among agents. To address these limitations, we model and solve NAHT through the lens of cooperative game theory. More specifically, we first model an open multi-agent system, characterized by its value, as an instance situated in a space of cooperative games, generated by a set of basis games. We then extend this space, along with the state space, to accommodate dynamic scenarios, thereby characterizing NAHT. Exploiting the justifiable assumption that basis game values correspond to a sequence of n-step returns with different horizons, we represent the state values for NAHT in a form similar to $\lambda$-returns. Furthermore, we derive Shapley values to allocate state values to the controlled agents, as credits for their contributions to the ad hoc team. Different from the conventional approach to shaping Shapley values in an explicit form, we shape Shapley values by fulfilling the three axioms uniquely describing them, well defined on the extended game space describing NAHT. To estimate Shapley values in dynamic scenarios, we propose a TD($\lambda$)-like algorithm. The resulting reinforcement learning (RL) algorithm is referred to as Shapley Machine. To our best knowledge, this is the first time that the concepts from cooperative game theory are directly related to RL concepts. In experiments, we demonstrate the effectiveness of Shapley Machine and verify reasonableness of our theory.
Collective Anomaly Perception During Multi-Robot Patrol: Constrained Interactions Can Promote Accurate Consensus
Dec 19, 2023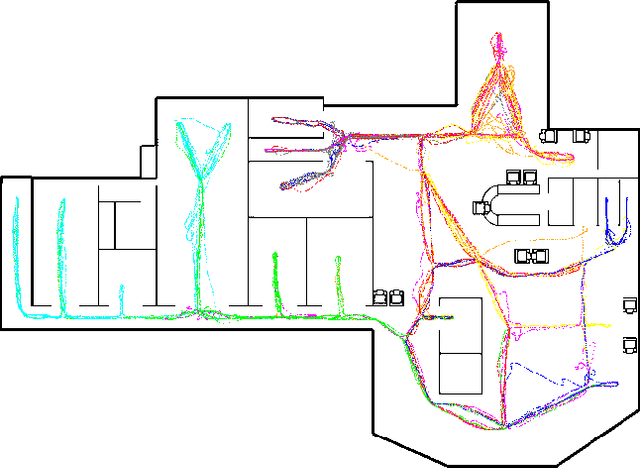
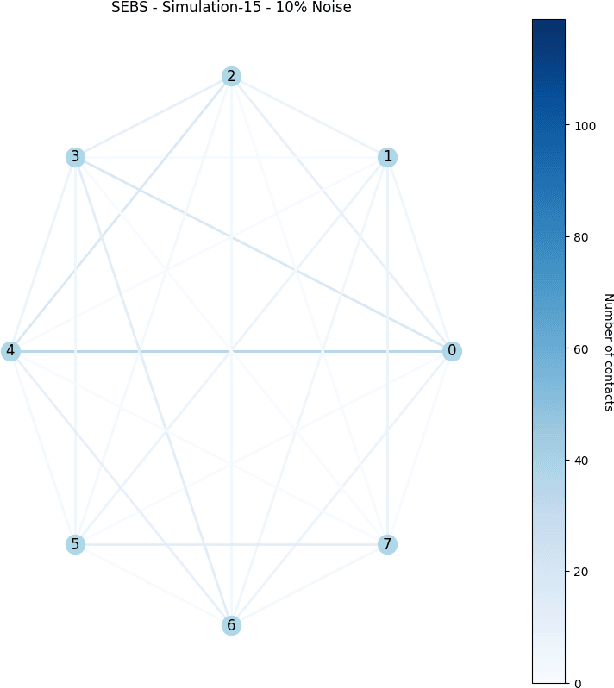
An important real-world application of multi-robot systems is multi-robot patrolling (MRP), where robots must carry out the activity of going through an area at regular intervals. Motivations for MRP include the detection of anomalies that may represent security threats. While MRP algorithms show some maturity in development, a key potential advantage has been unexamined: the ability to exploit collective perception of detected anomalies to prioritize the location ordering of security checks. This is because noisy individual-level detection of an anomaly may be compensated for by group-level consensus formation regarding whether an anomaly is likely to be truly present. Here, we examine the performance of unmodified idleness-based patrolling algorithms when given the additional objective of reaching an environmental perception consensus via local pairwise communication and a quorum threshold. We find that generally, MRP algorithms that promote physical mixing of robots, as measured by a higher connectivity of their emergent communication network, reach consensus more quickly. However, when there is noise present in anomaly detection, a more moderate (constrained) level of connectivity is preferable because it reduces the spread of false positive detections, as measured by a group-level F-score. These findings can inform user choice of MRP algorithm and future algorithm development.
Learning Interpretable Models of Aircraft Handling Behaviour by Reinforcement Learning from Human Feedback
May 26, 2023

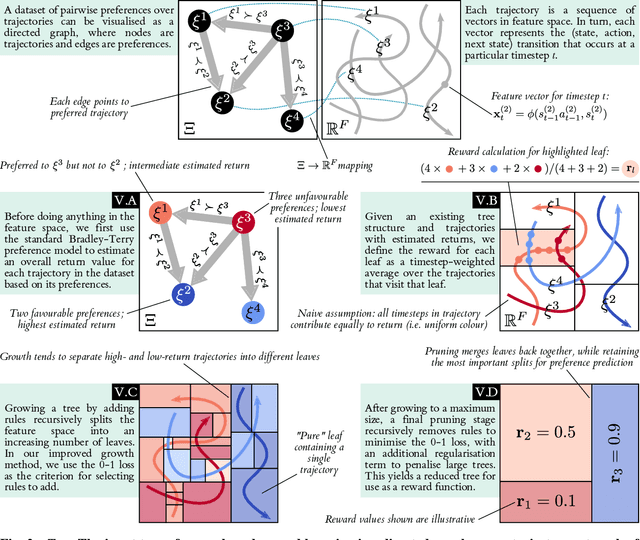

We propose a method to capture the handling abilities of fast jet pilots in a software model via reinforcement learning (RL) from human preference feedback. We use pairwise preferences over simulated flight trajectories to learn an interpretable rule-based model called a reward tree, which enables the automated scoring of trajectories alongside an explanatory rationale. We train an RL agent to execute high-quality handling behaviour by using the reward tree as the objective, and thereby generate data for iterative preference collection and further refinement of both tree and agent. Experiments with synthetic preferences show reward trees to be competitive with uninterpretable neural network reward models on quantitative and qualitative evaluations.
Two-step counterfactual generation for OOD examples
Feb 10, 2023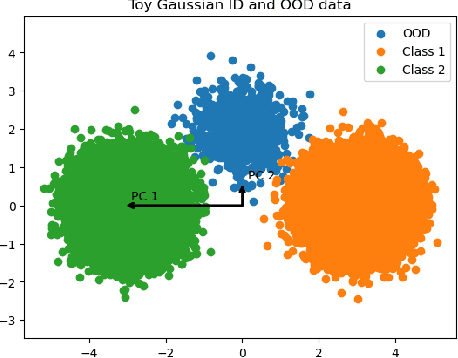
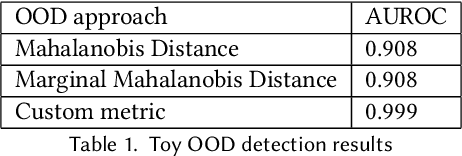
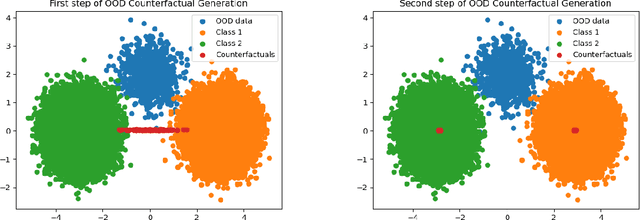
Two fundamental requirements for the deployment of machine learning models in safety-critical systems are to be able to detect out-of-distribution (OOD) data correctly and to be able to explain the prediction of the model. Although significant effort has gone into both OOD detection and explainable AI, there has been little work on explaining why a model predicts a certain data point is OOD. In this paper, we address this question by introducing the concept of an OOD counterfactual, which is a perturbed data point that iteratively moves between different OOD categories. We propose a method for generating such counterfactuals, investigate its application on synthetic and benchmark data, and compare it to several benchmark methods using a range of metrics.
Understanding the properties and limitations of contrastive learning for Out-of-Distribution detection
Nov 06, 2022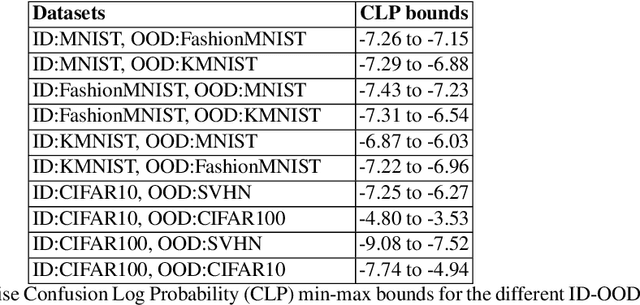
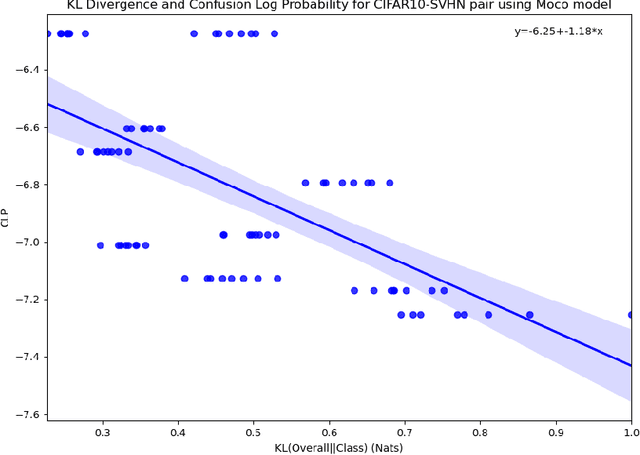
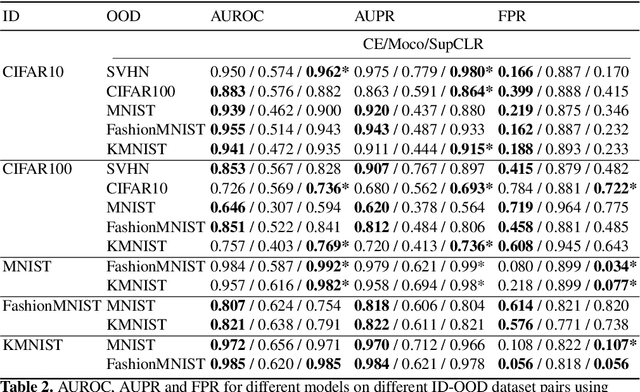
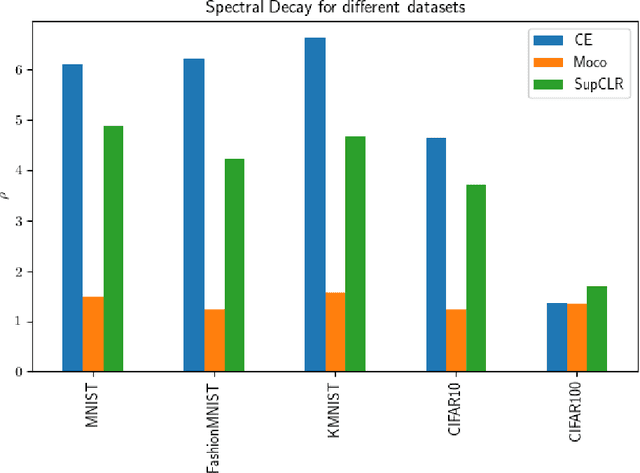
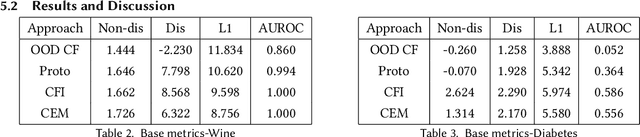
A recent popular approach to out-of-distribution (OOD) detection is based on a self-supervised learning technique referred to as contrastive learning. There are two main variants of contrastive learning, namely instance and class discrimination, targeting features that can discriminate between different instances for the former, and different classes for the latter. In this paper, we aim to understand the effectiveness and limitation of existing contrastive learning methods for OOD detection. We approach this in 3 ways. First, we systematically study the performance difference between the instance discrimination and supervised contrastive learning variants in different OOD detection settings. Second, we study which in-distribution (ID) classes OOD data tend to be classified into. Finally, we study the spectral decay property of the different contrastive learning approaches and examine how it correlates with OOD detection performance. In scenarios where the ID and OOD datasets are sufficiently different from one another, we see that instance discrimination, in the absence of fine-tuning, is competitive with supervised approaches in OOD detection. We see that OOD samples tend to be classified into classes that have a distribution similar to the distribution of the entire dataset. Furthermore, we show that contrastive learning learns a feature space that contains singular vectors containing several directions with a high variance which can be detrimental or beneficial to OOD detection depending on the inference approach used.
Reward Learning with Trees: Methods and Evaluation
Oct 03, 2022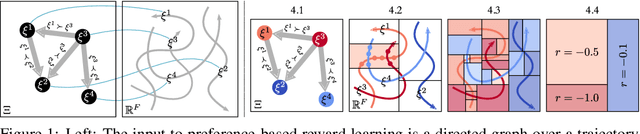
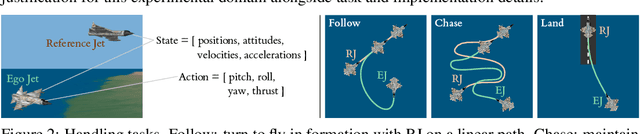
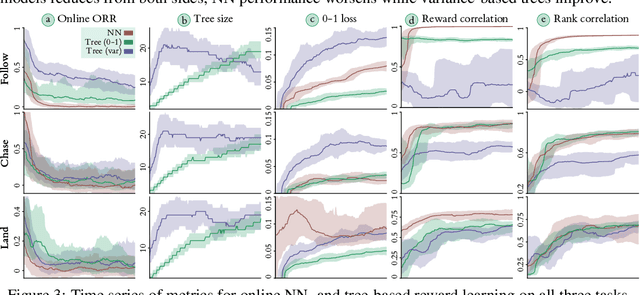
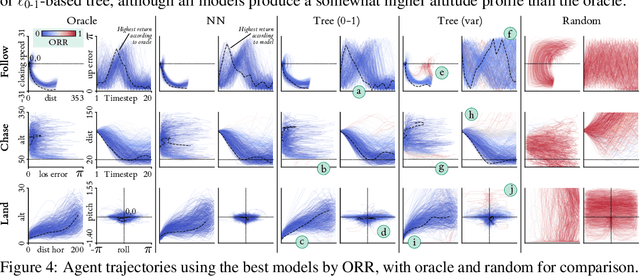
Recent efforts to learn reward functions from human feedback have tended to use deep neural networks, whose lack of transparency hampers our ability to explain agent behaviour or verify alignment. We explore the merits of learning intrinsically interpretable tree models instead. We develop a recently proposed method for learning reward trees from preference labels, and show it to be broadly competitive with neural networks on challenging high-dimensional tasks, with good robustness to limited or corrupted data. Having found that reward tree learning can be done effectively in complex settings, we then consider why it should be used, demonstrating that the interpretable reward structure gives significant scope for traceability, verification and explanation.
Summarising and Comparing Agent Dynamics with Contrastive Spatiotemporal Abstraction
Jan 17, 2022
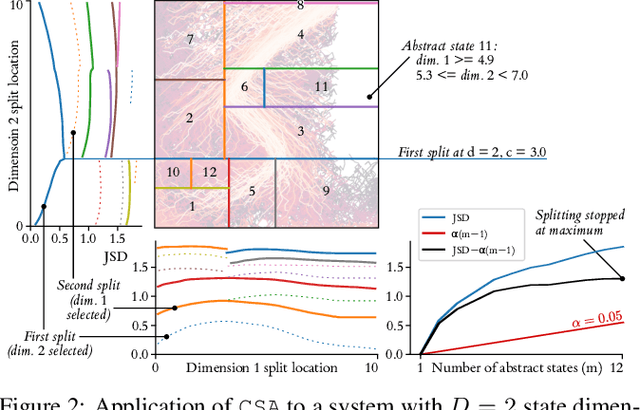
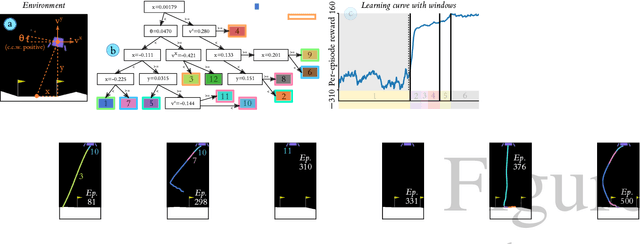
We introduce a data-driven, model-agnostic technique for generating a human-interpretable summary of the salient points of contrast within an evolving dynamical system, such as the learning process of a control agent. It involves the aggregation of transition data along both spatial and temporal dimensions according to an information-theoretic divergence measure. A practical algorithm is outlined for continuous state spaces, and deployed to summarise the learning histories of deep reinforcement learning agents with the aid of graphical and textual communication methods. We expect our method to be complementary to existing techniques in the realm of agent interpretability.
The Impact of Network Connectivity on Collective Learning
Jun 18, 2021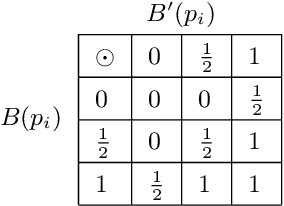
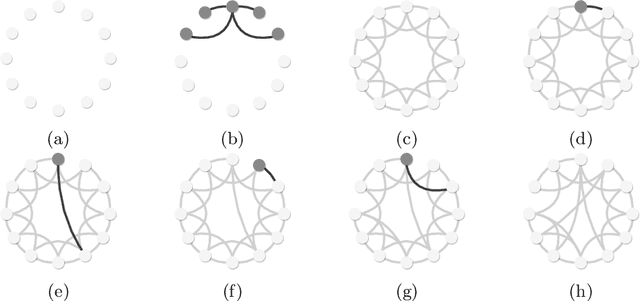
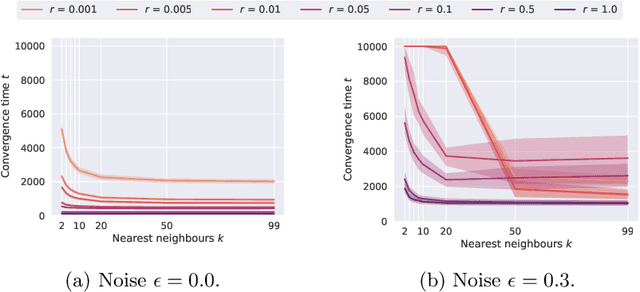
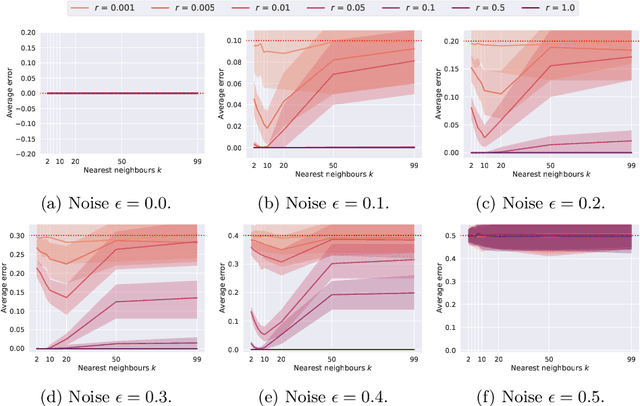
In decentralised autonomous systems it is the interactions between individual agents which govern the collective behaviours of the system. These local-level interactions are themselves often governed by an underlying network structure. These networks are particularly important for collective learning and decision-making whereby agents must gather evidence from their environment and propagate this information to other agents in the system. Models for collective behaviours may often rely upon the assumption of total connectivity between agents to provide effective information sharing within the system, but this assumption may be ill-advised. In this paper we investigate the impact that the underlying network has on performance in the context of collective learning. Through simulations we study small-world networks with varying levels of connectivity and randomness and conclude that totally-connected networks result in higher average error when compared to networks with less connectivity. Furthermore, we show that networks of high regularity outperform networks with increasing levels of random connectivity.
TripleTree: A Versatile Interpretable Representation of Black Box Agents and their Environments
Sep 21, 2020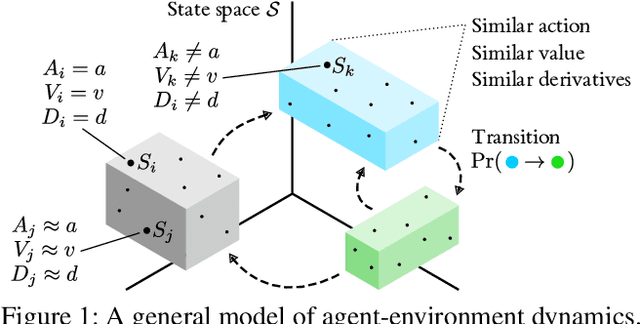
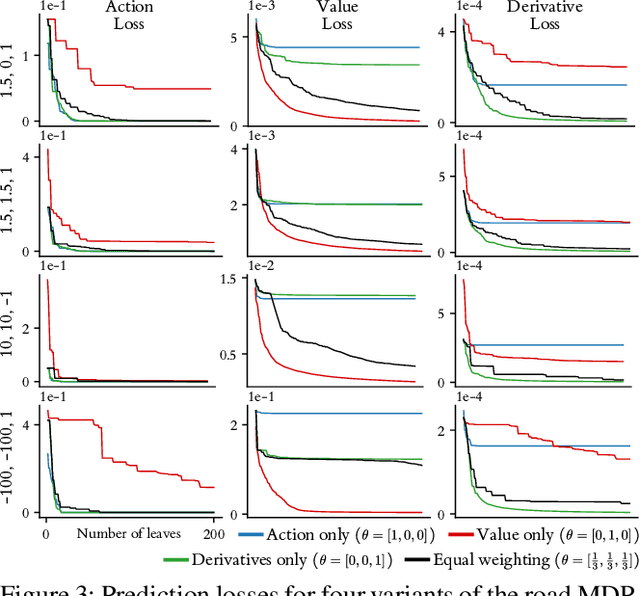
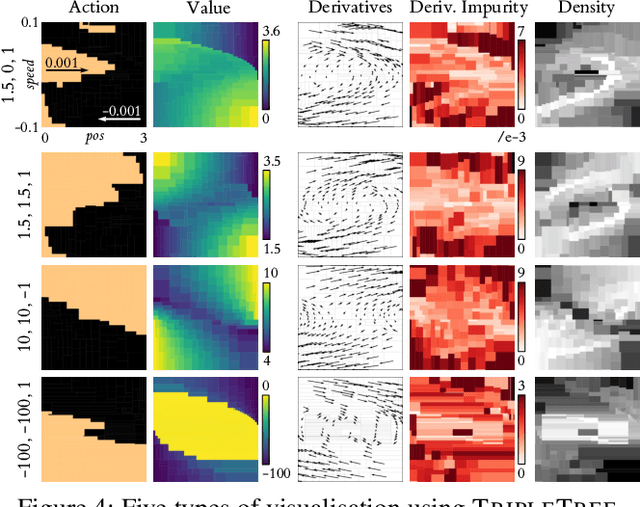
In explainable artificial intelligence, there is increasing interest in understanding the behaviour of autonomous agents to build trust and validate performance. Modern agent architectures, such as those trained by deep reinforcement learning, are currently so lacking in interpretable structure as to effectively be black boxes, but insights may still be gained from an external, behaviourist perspective. Inspired by conceptual spaces theory, we suggest that a versatile first step towards general understanding is to discretise the state space into convex regions, jointly capturing similarities over the agent's action, value function and temporal dynamics within a dataset of observations. We create such a representation using a novel variant of the CART decision tree algorithm, and demonstrate how it facilitates practical understanding of black box agents through prediction, visualisation and rule-based explanation.
Modelling Agent Policies with Interpretable Imitation Learning
Jun 19, 2020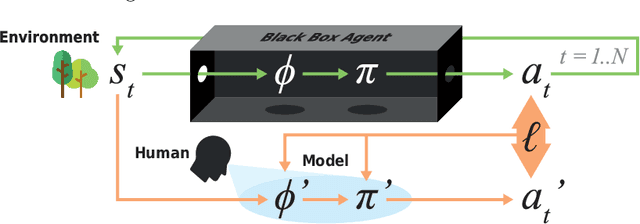
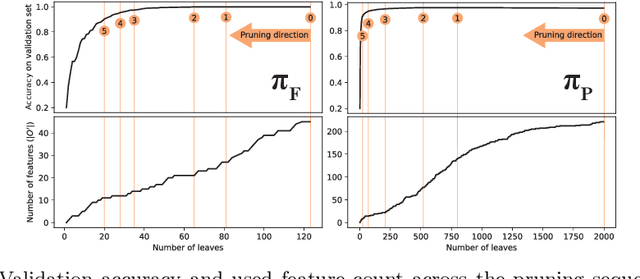
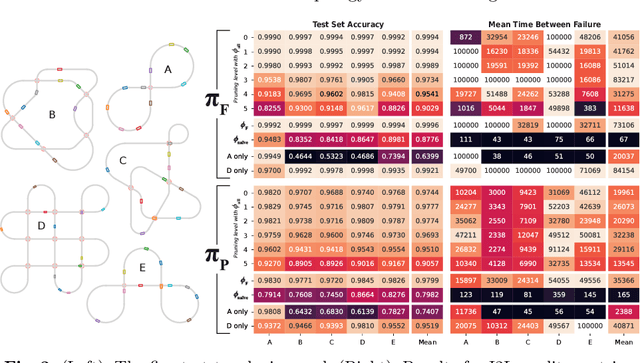
As we deploy autonomous agents in safety-critical domains, it becomes important to develop an understanding of their internal mechanisms and representations. We outline an approach to imitation learning for reverse-engineering black box agent policies in MDP environments, yielding simplified, interpretable models in the form of decision trees. As part of this process, we explicitly model and learn agents' latent state representations by selecting from a large space of candidate features constructed from the Markov state. We present initial promising results from an implementation in a multi-agent traffic environment.