 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Handling of Dynamic Environments in Decentralised Multi-Robot Patrol
Sep 16, 2025Persistent monitoring using robot teams is of interest in fields such as security, environmental monitoring, and disaster recovery. Performing such monitoring in a fully on-line decentralised fashion has significant potential advantages for robustness, adaptability, and scalability of monitoring solutions, including, in principle, the capacity to effectively adapt in real-time to a changing environment. We examine this through the lens of multi-robot patrol, in which teams of patrol robots must persistently minimise time between visits to points of interest, within environments where traversability of routes is highly dynamic. These dynamics must be observed by patrol agents and accounted for in a fully decentralised on-line manner. In this work, we present a new method of monitoring and adjusting for environment dynamics in a decentralised multi-robot patrol team. We demonstrate that our method significantly outperforms realistic baselines in highly dynamic scenarios, and also investigate dynamic scenarios in which explicitly accounting for environment dynamics may be unnecessary or impractical.
Learning Interpretable Models of Aircraft Handling Behaviour by Reinforcement Learning from Human Feedback
May 26, 2023

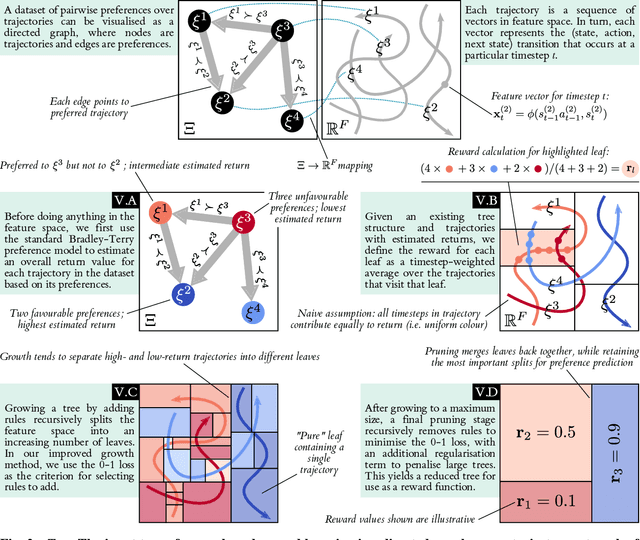

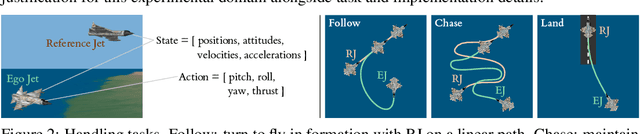
We propose a method to capture the handling abilities of fast jet pilots in a software model via reinforcement learning (RL) from human preference feedback. We use pairwise preferences over simulated flight trajectories to learn an interpretable rule-based model called a reward tree, which enables the automated scoring of trajectories alongside an explanatory rationale. We train an RL agent to execute high-quality handling behaviour by using the reward tree as the objective, and thereby generate data for iterative preference collection and further refinement of both tree and agent. Experiments with synthetic preferences show reward trees to be competitive with uninterpretable neural network reward models on quantitative and qualitative evaluations.
Reward Learning with Trees: Methods and Evaluation
Oct 03, 2022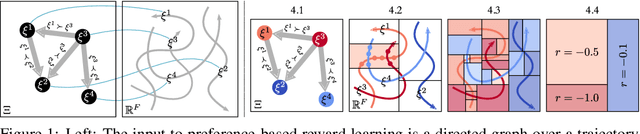
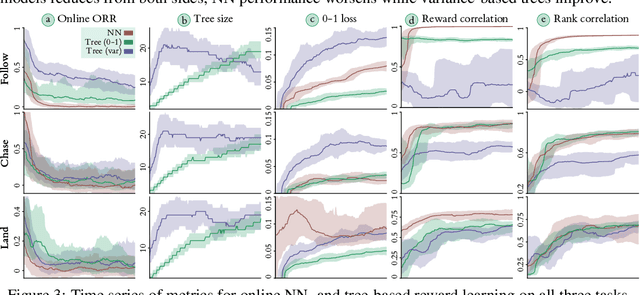
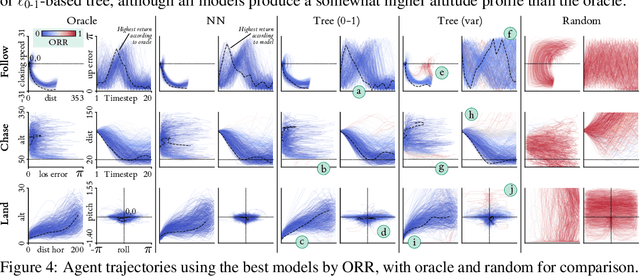
Recent efforts to learn reward functions from human feedback have tended to use deep neural networks, whose lack of transparency hampers our ability to explain agent behaviour or verify alignment. We explore the merits of learning intrinsically interpretable tree models instead. We develop a recently proposed method for learning reward trees from preference labels, and show it to be broadly competitive with neural networks on challenging high-dimensional tasks, with good robustness to limited or corrupted data. Having found that reward tree learning can be done effectively in complex settings, we then consider why it should be used, demonstrating that the interpretable reward structure gives significant scope for traceability, verification and explanation.
Summarising and Comparing Agent Dynamics with Contrastive Spatiotemporal Abstraction
Jan 17, 2022
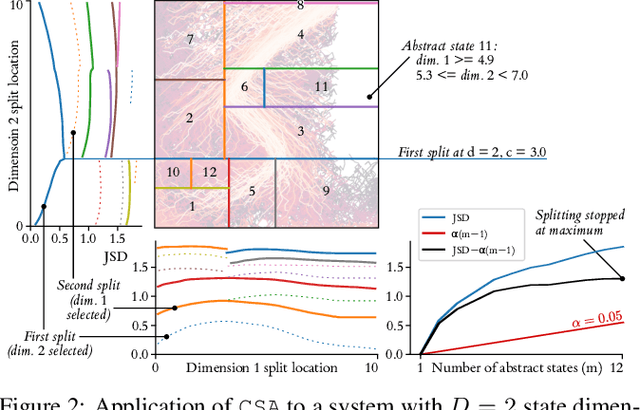
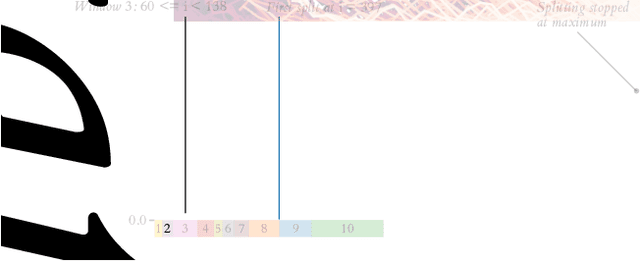
We introduce a data-driven, model-agnostic technique for generating a human-interpretable summary of the salient points of contrast within an evolving dynamical system, such as the learning process of a control agent. It involves the aggregation of transition data along both spatial and temporal dimensions according to an information-theoretic divergence measure. A practical algorithm is outlined for continuous state spaces, and deployed to summarise the learning histories of deep reinforcement learning agents with the aid of graphical and textual communication methods. We expect our method to be complementary to existing techniques in the realm of agent interpretability.
Modelling Agent Policies with Interpretable Imitation Learning
Jun 19, 2020
As we deploy autonomous agents in safety-critical domains, it becomes important to develop an understanding of their internal mechanisms and representations. We outline an approach to imitation learning for reverse-engineering black box agent policies in MDP environments, yielding simplified, interpretable models in the form of decision trees. As part of this process, we explicitly model and learn agents' latent state representations by selecting from a large space of candidate features constructed from the Markov state. We present initial promising results from an implementation in a multi-agent traffic environment.
Formal Specification and Analysis of Autonomous Systems under Partial Compliance
Jul 22, 2016
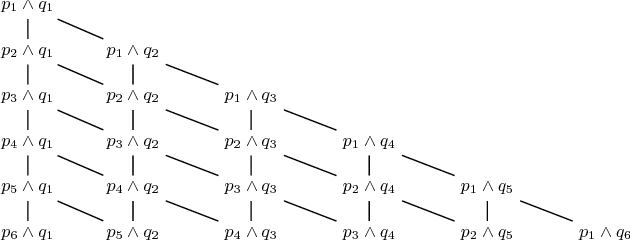
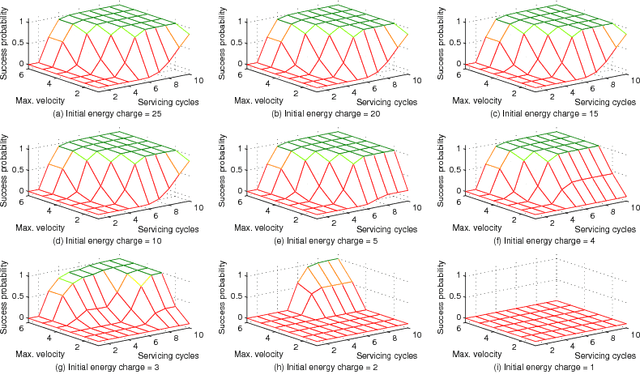
The widespread adoption of autonomous systems depends on providing guarantees of safety and functional correctness, at both design time and runtime. Information about the extent to which functional requirements can be met in combination with non-functional requirements (NFRs) -- i.e. requirements that can be partially complied with -- , under dynamic and uncertain environments, provides opportunities to enhance the safety and functional correctness of systems at design time. We present a technique to formally define system attributes that can change or be changed to deal with dynamic and uncertain environments (denominated weakened specifications) as a partially ordered lattice, and to automatically explore the system under different specifications, using probabilistic model checking, to find the likelihood of satisfying a requirement. The resulting probabilities form boundaries of "optimal specifications", analogous to Pareto frontiers in multi-objective optimization, informing the designer about the system's capabilities, such as resilience or robustness, when changing its attributes to deal with dynamic and uncertain environments. We illustrate the proposed technique through a domestic robotic assistant example.