 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Learning with Trees: Methods and Evaluation
Paper and Code
Oct 03, 2022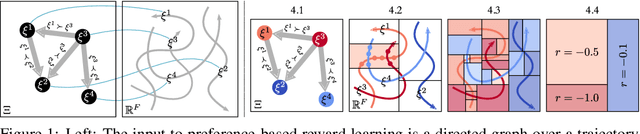
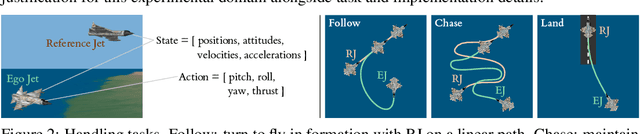
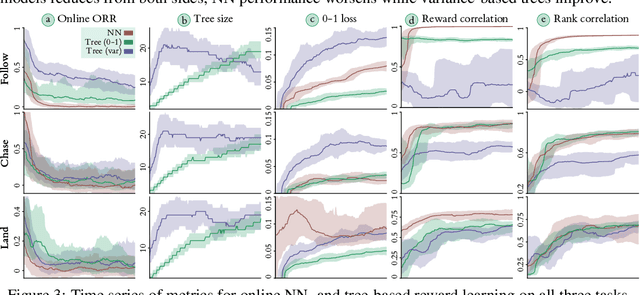
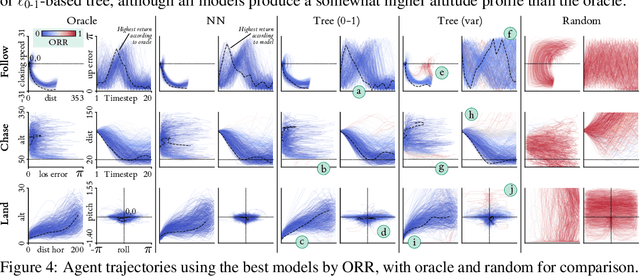
Recent efforts to learn reward functions from human feedback have tended to use deep neural networks, whose lack of transparency hampers our ability to explain agent behaviour or verify alignment. We explore the merits of learning intrinsically interpretable tree models instead. We develop a recently proposed method for learning reward trees from preference labels, and show it to be broadly competitive with neural networks on challenging high-dimensional tasks, with good robustness to limited or corrupted data. Having found that reward tree learning can be done effectively in complex settings, we then consider why it should be used, demonstrating that the interpretable reward structure gives significant scope for traceability, verification and explanation.