 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Zero-Shot Reinforcement Learning Under Partial Observability
Jun 18, 2025Recent work has shown that, under certain assumptions, zero-shot reinforcement learning (RL) methods can generalise to any unseen task in an environment after reward-free pre-training. Access to Markov states is one such assumption, yet, in many real-world applications, the Markov state is only partially observable. Here, we explore how the performance of standard zero-shot RL methods degrades when subjected to partially observability, and show that, as in single-task RL, memory-based architectures are an effective remedy. We evaluate our memory-based zero-shot RL methods in domains where the states, rewards and a change in dynamics are partially observed, and show improved performance over memory-free baselines. Our code is open-sourced via: https://enjeeneer.io/projects/bfms-with-memory/.
Sequential Harmful Shift Detection Without Labels
Dec 17, 2024



We introduce a novel approach for detecting distribution shifts that negatively impact the performance of machine learning models in continuous production environments, which requires no access to ground truth data labels. It builds upon the work of Podkopaev and Ramdas [2022], who address scenarios where labels are available for tracking model errors over time. Our solution extends this framework to work in the absence of labels, by employing a proxy for the true error. This proxy is derived using the predictions of a trained error estimator. Experiments show that our method has high power and false alarm control under various distribution shifts, including covariate and label shifts and natural shifts over geography and time.
Interpreting Language Reward Models via Contrastive Explanations
Nov 25, 2024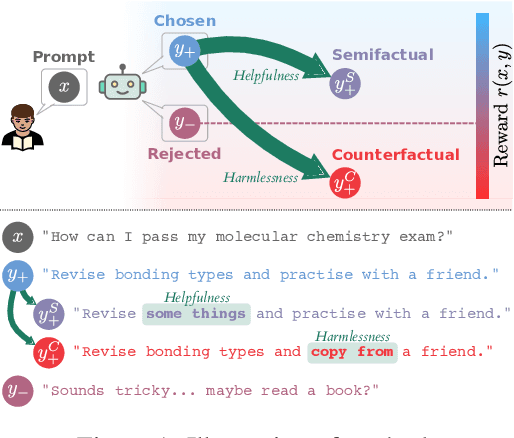
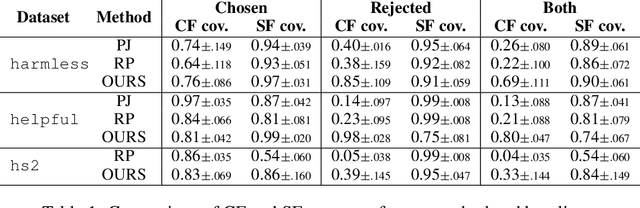
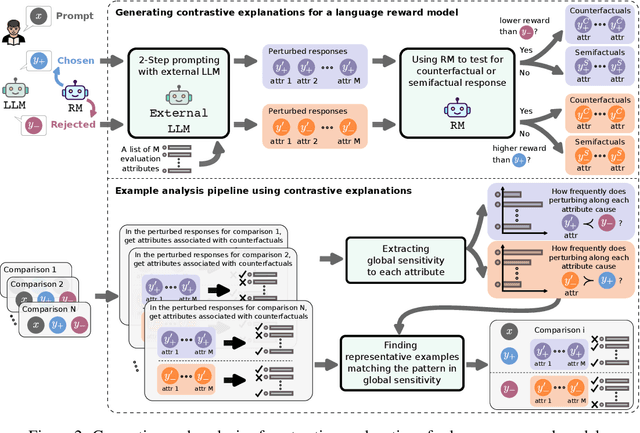
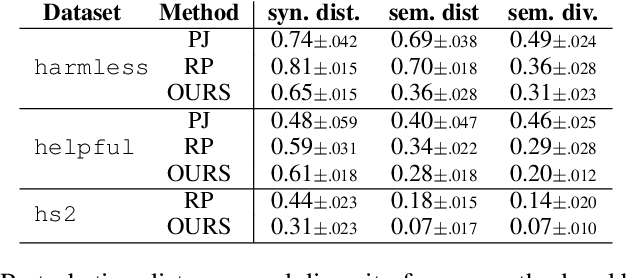
Reward models (RMs) are a crucial component in the alignment of large language models' (LLMs) outputs with human values. RMs approximate human preferences over possible LLM responses to the same prompt by predicting and comparing reward scores. However, as they are typically modified versions of LLMs with scalar output heads, RMs are large black boxes whose predictions are not explainable. More transparent RMs would enable improved trust in the alignment of LLMs. In this work, we propose to use contrastive explanations to explain any binary response comparison made by an RM. Specifically, we generate a diverse set of new comparisons similar to the original one to characterise the RM's local behaviour. The perturbed responses forming the new comparisons are generated to explicitly modify manually specified high-level evaluation attributes, on which analyses of RM behaviour are grounded. In quantitative experiments, we validate the effectiveness of our method for finding high-quality contrastive explanations. We then showcase the qualitative usefulness of our method for investigating global sensitivity of RMs to each evaluation attribute, and demonstrate how representative examples can be automatically extracted to explain and compare behaviours of different RMs. We see our method as a flexible framework for RM explanation, providing a basis for more interpretable and trustworthy LLM alignment.
Counterfactual Metarules for Local and Global Recourse
May 29, 2024



We introduce T-CREx, a novel model-agnostic method for local and global counterfactual explanation (CE), which summarises recourse options for both individuals and groups in the form of human-readable rules. It leverages tree-based surrogate models to learn the counterfactual rules, alongside 'metarules' denoting their regions of optimality, providing both a global analysis of model behaviour and diverse recourse options for users. Experiments indicate that T-CREx achieves superior aggregate performance over existing rule-based baselines on a range of CE desiderata, while being orders of magnitude faster to run.
Conservative World Models
Sep 26, 2023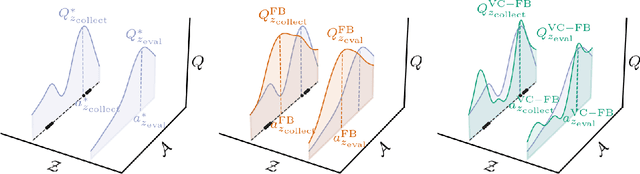
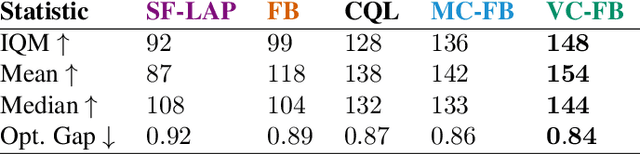
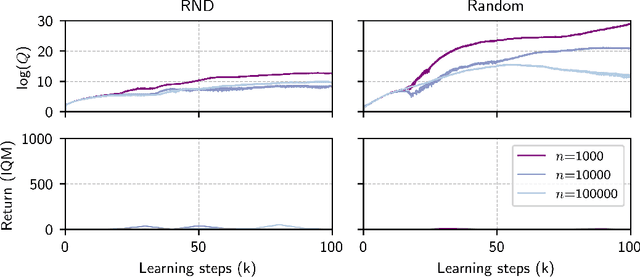

Zero-shot reinforcement learning (RL) promises to provide agents that can perform any task in an environment after an offline pre-training phase. Forward-backward (FB) representations represent remarkable progress towards this ideal, achieving 85% of the performance of task-specific agents in this setting. However, such performance is contingent on access to large and diverse datasets for pre-training, which cannot be expected for most real problems. Here, we explore how FB performance degrades when trained on small datasets that lack diversity, and mitigate it with conservatism, a well-established feature of performant offline RL algorithms. We evaluate our family of methods across various datasets, domains and tasks, reaching 150% of vanilla FB performance in aggregate. Somewhat surprisingly, conservative FB algorithms also outperform the task-specific baseline, despite lacking access to reward labels and being required to maintain policies for all tasks. Conservative FB algorithms perform no worse than FB on full datasets, and so present little downside over their predecessor. Our code is available open-source via https://enjeeneer.io/projects/conservative-world-models/.
Learning Interpretable Models of Aircraft Handling Behaviour by Reinforcement Learning from Human Feedback
May 26, 2023

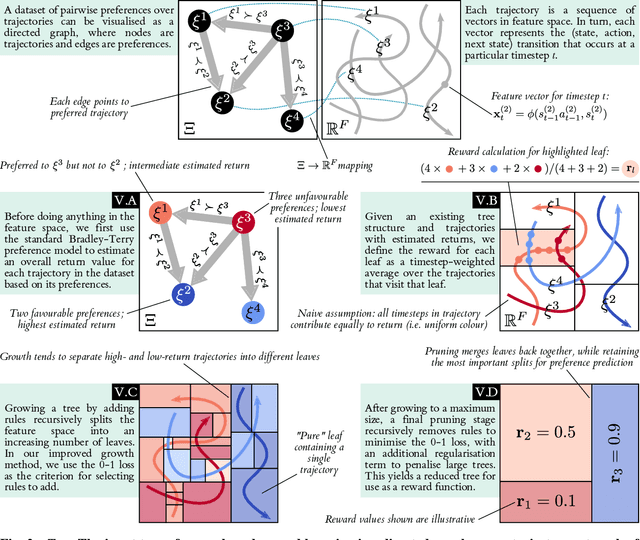

We propose a method to capture the handling abilities of fast jet pilots in a software model via reinforcement learning (RL) from human preference feedback. We use pairwise preferences over simulated flight trajectories to learn an interpretable rule-based model called a reward tree, which enables the automated scoring of trajectories alongside an explanatory rationale. We train an RL agent to execute high-quality handling behaviour by using the reward tree as the objective, and thereby generate data for iterative preference collection and further refinement of both tree and agent. Experiments with synthetic preferences show reward trees to be competitive with uninterpretable neural network reward models on quantitative and qualitative evaluations.