 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Reinforcement Learning Under Partial Observability
Jun 18, 2025Recent work has shown that, under certain assumptions, zero-shot reinforcement learning (RL) methods can generalise to any unseen task in an environment after reward-free pre-training. Access to Markov states is one such assumption, yet, in many real-world applications, the Markov state is only partially observable. Here, we explore how the performance of standard zero-shot RL methods degrades when subjected to partially observability, and show that, as in single-task RL, memory-based architectures are an effective remedy. We evaluate our memory-based zero-shot RL methods in domains where the states, rewards and a change in dynamics are partially observed, and show improved performance over memory-free baselines. Our code is open-sourced via: https://enjeeneer.io/projects/bfms-with-memory/.
Conservative World Models
Sep 26, 2023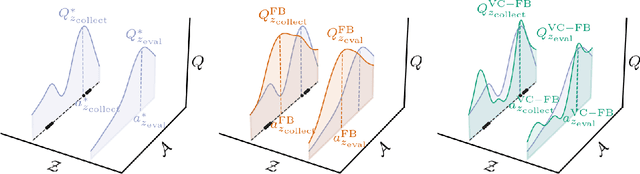
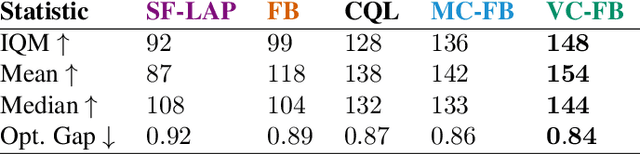
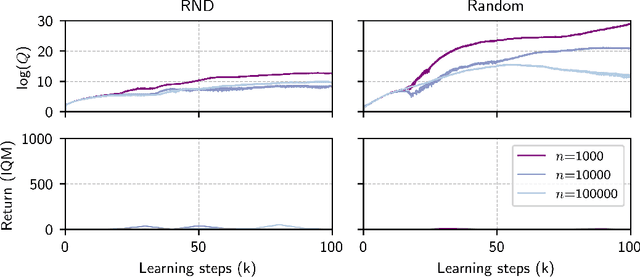

Zero-shot reinforcement learning (RL) promises to provide agents that can perform any task in an environment after an offline pre-training phase. Forward-backward (FB) representations represent remarkable progress towards this ideal, achieving 85% of the performance of task-specific agents in this setting. However, such performance is contingent on access to large and diverse datasets for pre-training, which cannot be expected for most real problems. Here, we explore how FB performance degrades when trained on small datasets that lack diversity, and mitigate it with conservatism, a well-established feature of performant offline RL algorithms. We evaluate our family of methods across various datasets, domains and tasks, reaching 150% of vanilla FB performance in aggregate. Somewhat surprisingly, conservative FB algorithms also outperform the task-specific baseline, despite lacking access to reward labels and being required to maintain policies for all tasks. Conservative FB algorithms perform no worse than FB on full datasets, and so present little downside over their predecessor. Our code is available open-source via https://enjeeneer.io/projects/conservative-world-models/.
Low Emission Building Control with Zero-Shot Reinforcement Learning
Aug 15, 2022



Heating and cooling systems in buildings account for 31\% of global energy use, much of which are regulated by Rule Based Controllers (RBCs) that neither maximise energy efficiency nor minimise emissions by interacting optimally with the grid. Control via Reinforcement Learning (RL) has been shown to significantly improve building energy efficiency, but existing solutions require access to building-specific simulators or data that cannot be expected for every building in the world. In response, we show it is possible to obtain emission-reducing policies without such knowledge a priori--a paradigm we call zero-shot building control. We combine ideas from system identification and model-based RL to create PEARL (Probabilistic Emission-Abating Reinforcement Learning) and show that a short period of active exploration is all that is required to build a performant model. In experiments across three varied building energy simulations, we show PEARL outperforms an existing RBC once, and popular RL baselines in all cases, reducing building emissions by as much as 31\% whilst maintaining thermal comfort. Our source code is available online via https://enjeeneer.io/projects/pearl .
Zero-Shot Building Control
Jun 28, 2022



Heating and cooling systems in buildings account for 31% of global energy use, much of which are regulated by Rule Based Controllers (RBCs) that neither maximise energy efficiency nor minimise emissions by interacting optimally with the grid. Control via Reinforcement Learning (RL) has been shown to significantly improve building energy efficiency, but existing solutions require pre-training in simulators that are prohibitively expensive to obtain for every building in the world. In response, we show it is possible to perform safe, zero-shot control of buildings by combining ideas from system identification and model-based RL. We call this combination PEARL (Probabilistic Emission-Abating Reinforcement Learning) and show it reduces emissions without pre-training, needing only a three hour commissioning period. In experiments across three varied building energy simulations, we show PEARL outperforms an existing RBC once, and popular RL baselines in all cases, reducing building emissions by as much as 31% whilst maintaining thermal comfort.