 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapShift: Explaining Model Prediction Shifts with Subgroup Conditional Shapley Values
Apr 13, 2026Changes in input distribution can induce shifts in the average predictions of machine learning models. Such prediction shifts may impact downstream business outcomes (e.g. a bank's loan approval rate), so understanding their causes can be crucial. We propose \ours{}: a Shapley value method for attributing prediction shifts to changes in the conditional probabilities of interpretable subgroups of data, where these subgroups are defined by the structure of decision trees. We initially apply this method to single decision trees, providing exact explanations based on conditional probability changes at split nodes. Next, we extend it to tree ensembles by selecting the most explanatory tree and accounting for residual effects. Finally, we propose a model-agnostic variant using surrogate trees grown with a novel objective function, allowing application to models like neural networks. While exact computation can be intensive, approximation techniques enable practical application. We show that \ours{} provides simple, faithful, and near-complete explanations of prediction shifts across model classes, aiding model monitoring in dynamic environments.
Regional Explanations: Bridging Local and Global Variable Importance
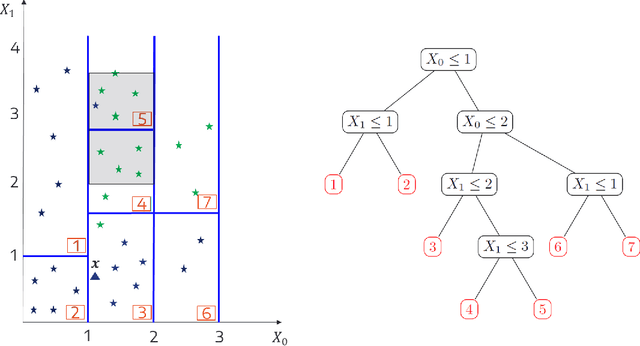
Apr 13, 2026We analyze two widely used local attribution methods, Local Shapley Values and LIME, which aim to quantify the contribution of a feature value $x_i$ to a specific prediction $f(x_1, \dots, x_p)$. Despite their widespread use, we identify fundamental limitations in their ability to reliably detect locally important features, even under ideal conditions with exact computations and independent features. We argue that a sound local attribution method should not assign importance to features that neither influence the model output (e.g., features with zero coefficients in a linear model) nor exhibit statistical dependence with functionality-relevant features. We demonstrate that both Local SV and LIME violate this fundamental principle. To address this, we propose R-LOCO (Regional Leave Out COvariates), which bridges the gap between local and global explanations and provides more accurate attributions. R-LOCO segments the input space into regions with similar feature importance characteristics. It then applies global attribution methods within these regions, deriving an instance's feature contributions from its regional membership. This approach delivers more faithful local attributions while avoiding local explanation instability and preserving instance-specific detail often lost in global methods.
Sequential Harmful Shift Detection Without Labels
Dec 17, 2024



We introduce a novel approach for detecting distribution shifts that negatively impact the performance of machine learning models in continuous production environments, which requires no access to ground truth data labels. It builds upon the work of Podkopaev and Ramdas [2022], who address scenarios where labels are available for tracking model errors over time. Our solution extends this framework to work in the absence of labels, by employing a proxy for the true error. This proxy is derived using the predictions of a trained error estimator. Experiments show that our method has high power and false alarm control under various distribution shifts, including covariate and label shifts and natural shifts over geography and time.
Counterfactual Metarules for Local and Global Recourse
May 29, 2024



We introduce T-CREx, a novel model-agnostic method for local and global counterfactual explanation (CE), which summarises recourse options for both individuals and groups in the form of human-readable rules. It leverages tree-based surrogate models to learn the counterfactual rules, alongside 'metarules' denoting their regions of optimality, providing both a global analysis of model behaviour and diverse recourse options for users. Experiments indicate that T-CREx achieves superior aggregate performance over existing rule-based baselines on a range of CE desiderata, while being orders of magnitude faster to run.
Adaptive Conformal Prediction by Reweighting Nonconformity Score
Mar 22, 2023Despite attractive theoretical guarantees and practical successes, Predictive Interval (PI) given by Conformal Prediction (CP) may not reflect the uncertainty of a given model. This limitation arises from CP methods using a constant correction for all test points, disregarding their individual uncertainties, to ensure coverage properties. To address this issue, we propose using a Quantile Regression Forest (QRF) to learn the distribution of nonconformity scores and utilizing the QRF's weights to assign more importance to samples with residuals similar to the test point. This approach results in PI lengths that are more aligned with the model's uncertainty. In addition, the weights learnt by the QRF provide a partition of the features space, allowing for more efficient computations and improved adaptiveness of the PI through groupwise conformalization. Our approach enjoys an assumption-free finite sample marginal and training-conditional coverage, and under suitable assumptions, it also ensures conditional coverage. Our methods work for any nonconformity score and are available as a Python package. We conduct experiments on simulated and real-world data that demonstrate significant improvements compared to existing methods.
Rethinking Counterfactual Explanations as Local and Regional Counterfactual Policies
Sep 29, 2022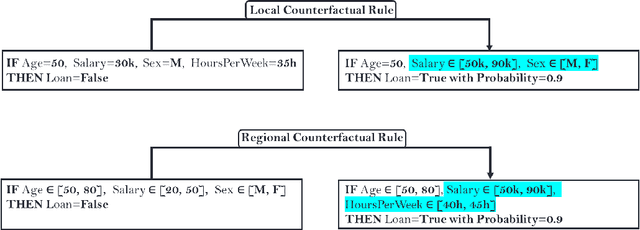

Among the challenges not yet resolved for Counterfactual Explanations (CE), there are stability, synthesis of the various CE and the lack of plausibility/sparsity guarantees. From a more practical point of view, recent studies show that the prescribed counterfactual recourses are often not implemented exactly by the individuals and demonstrate that most state-of-the-art CE algorithms are very likely to fail in this noisy environment. To address these issues, we propose a probabilistic framework that gives a sparse local counterfactual rule for each observation: we provide rules that give a range of values that can change the decision with a given high probability instead of giving diverse CE. In addition, the recourses derived from these rules are robust by construction. These local rules are aggregated into a regional counterfactual rule to ensure the stability of the counterfactual explanations across observations. Our local and regional rules guarantee that the recourses are faithful to the data distribution because our rules use a consistent estimator of the probabilities of changing the decision based on a Random Forest. In addition, these probabilities give interpretable and sparse rules as we select the smallest set of variables having a given probability of changing the decision. Codes for computing our counterfactual rules are available, and we compare their relevancy with standard CE and recent similar attempts.
Consistent Sufficient Explanations and Minimal Local Rules for explaining regression and classification models
Nov 08, 2021


To explain the decision of any model, we extend the notion of probabilistic Sufficient Explanations (P-SE). For each instance, this approach selects the minimal subset of features that is sufficient to yield the same prediction with high probability, while removing other features. The crux of P-SE is to compute the conditional probability of maintaining the same prediction. Therefore, we introduce an accurate and fast estimator of this probability via random Forests for any data $(\boldsymbol{X}, Y)$ and show its efficiency through a theoretical analysis of its consistency. As a consequence, we extend the P-SE to regression problems. In addition, we deal with non-binary features, without learning the distribution of $X$ nor having the model for making predictions. Finally, we introduce local rule-based explanations for regression/classification based on the P-SE and compare our approaches w.r.t other explainable AI methods. These methods are publicly available as a Python package at \url{www.github.com/salimamoukou/acv00}.
Accurate and robust Shapley Values for explaining predictions and focusing on local important variables
Jun 07, 2021



Although Shapley Values (SV) are widely used in explainable AI, they can be poorly understood and estimated, which implies that their analysis may lead to spurious inferences and explanations. As a starting point, we remind an invariance principle for SV and derive the correct approach for computing the SV of categorical variables that are particularly sensitive to the encoding used. In the case of tree-based models, we introduce two estimators of Shapley Values that exploit efficiently the tree structure and are more accurate than state-of-the-art methods. For interpreting additive explanations, we recommend to filter the non-influential variables and to compute the Shapley Values only for groups of influential variables. For this purpose, we use the concept of "Same Decision Probability" (SDP) that evaluates the robustness of a prediction when some variables are missing. This prior selection procedure produces sparse additive explanations easier to visualize and analyse. Simulations and comparisons are performed with state-of-the-art algorithm, and show the practical gain of our approach.
The Shapley Value of coalition of variables provides better explanations
Mar 25, 2021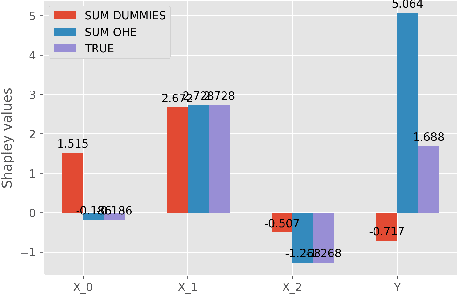
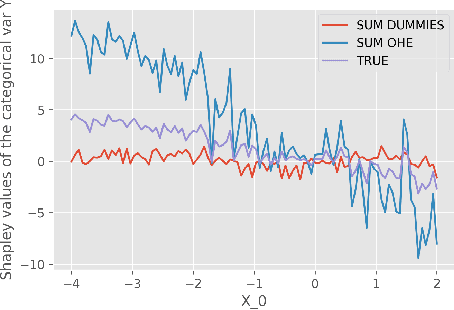
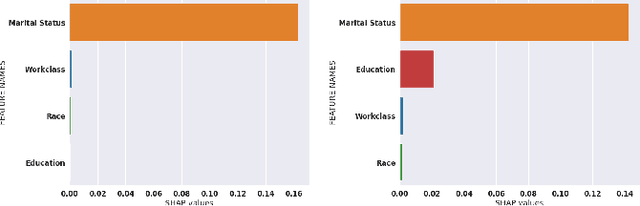
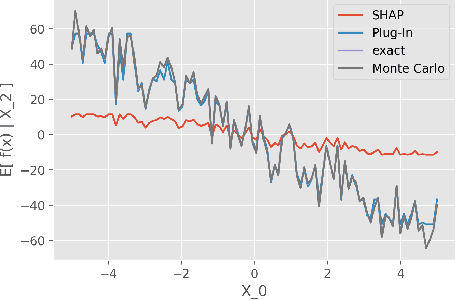
While Shapley Values (SV) are one of the gold standard for interpreting machine learning models, we show that they are still poorly understood, in particular in the presence of categorical variables or of variables of low importance. For instance, we show that the popular practice that consists in summing the SV of dummy variables is false as it provides wrong estimates of all the SV in the model and implies spurious interpretations. Based on the identification of null and active coalitions, and a coalitional version of the SV, we provide a correct computation and inference of important variables. Moreover, a Python library (All the experiments and simulations can be reproduced with the publicly available library Active Coalition of Variables, https://www.github.com/salimamoukou/acv00) that computes reliably conditional expectations and SV for tree-based models, is implemented and compared with state-of-the-art algorithms on toy models and real data sets.