 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Off-Policy Deep Reinforcement Learning Doesn't Have to be Slow
Dec 23, 2025



Recurrent off-policy deep reinforcement learning models achieve state-of-the-art performance but are often sidelined due to their high computational demands. In response, we introduce RISE (Recurrent Integration via Simplified Encodings), a novel approach that can leverage recurrent networks in any image-based off-policy RL setting without significant computational overheads via using both learnable and non-learnable encoder layers. When integrating RISE into leading non-recurrent off-policy RL algorithms, we observe a 35.6% human-normalized interquartile mean (IQM) performance improvement across the Atari benchmark. We analyze various implementation strategies to highlight the versatility and potential of our proposed framework.
Beyond The Rainbow: High Performance Deep Reinforcement Learning On A Desktop PC
Nov 06, 2024



Rainbow Deep Q-Network (DQN) demonstrated combining multiple independent enhancements could significantly boost a reinforcement learning (RL) agent's performance. In this paper, we present "Beyond The Rainbow" (BTR), a novel algorithm that integrates six improvements from across the RL literature to Rainbow DQN, establishing a new state-of-the-art for RL using a desktop PC, with a human-normalized interquartile mean (IQM) of 7.4 on atari-60. Beyond Atari, we demonstrate BTR's capability to handle complex 3D games, successfully training agents to play Super Mario Galaxy, Mario Kart, and Mortal Kombat with minimal algorithmic changes. Designing BTR with computational efficiency in mind, agents can be trained using a desktop PC on 200 million Atari frames within 12 hours. Additionally, we conduct detailed ablation studies of each component, analzying the performance and impact using numerous measures.
Scene-to-Patch Earth Observation: Multiple Instance Learning for Land Cover Classification
Nov 15, 2022Land cover classification (LCC), and monitoring how land use changes over time, is an important process in climate change mitigation and adaptation. Existing approaches that use machine learning with Earth observation data for LCC rely on fully-annotated and segmented datasets. Creating these datasets requires a large amount of effort, and a lack of suitable datasets has become an obstacle in scaling the use of LCC. In this study, we propose Scene-to-Patch models: an alternative LCC approach utilising Multiple Instance Learning (MIL) that requires only high-level scene labels. This enables much faster development of new datasets whilst still providing segmentation through patch-level predictions, ultimately increasing the accessibility of using LCC for different scenarios. On the DeepGlobe-LCC dataset, our approach outperforms non-MIL baselines on both scene- and patch-level prediction. This work provides the foundation for expanding the use of LCC in climate change mitigation methods for technology, government, and academia.
Trust in Language Grounding: a new AI challenge for human-robot teams
Sep 05, 2022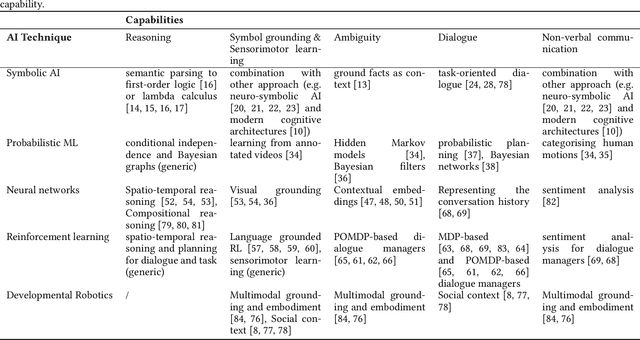
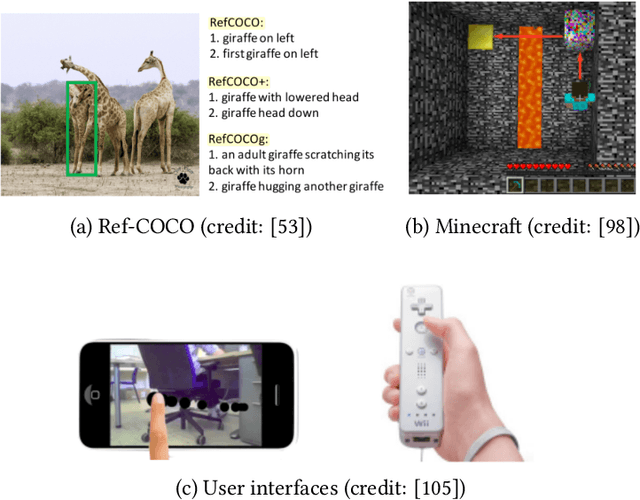


The challenge of language grounding is to fully understand natural language by grounding language in real-world referents. While AI techniques are available, the widespread adoption and effectiveness of such technologies for human-robot teams relies critically on user trust. This survey provides three contributions relating to the newly emerging field of trust in language grounding, including a) an overview of language grounding research in terms of AI technologies, data sets, and user interfaces; b) six hypothesised trust factors relevant to language grounding, which are tested empirically on a human-robot cleaning team; and c) future research directions for trust in language grounding.
Non-Markovian Reward Modelling from Trajectory Labels via Interpretable Multiple Instance Learning
May 30, 2022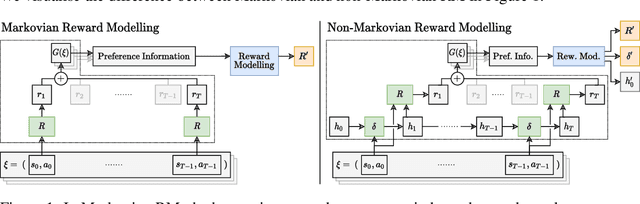

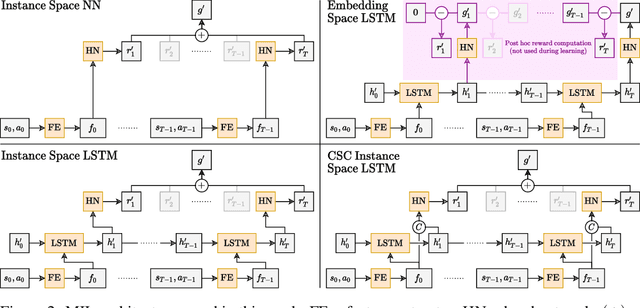

We generalise the problem of reward modelling (RM) for reinforcement learning (RL) to handle non-Markovian rewards. Existing work assumes that human evaluators observe each step in a trajectory independently when providing feedback on agent behaviour. In this work, we remove this assumption, extending RM to include hidden state information that captures temporal dependencies in human assessment of trajectories. We then show how RM can be approached as a multiple instance learning (MIL) problem, and develop new MIL models that are able to capture the time dependencies in labelled trajectories. We demonstrate on a range of RL tasks that our novel MIL models can reconstruct reward functions to a high level of accuracy, and that they provide interpretable learnt hidden information that can be used to train high-performing agent policies.
Model Agnostic Interpretability for Multiple Instance Learning
Jan 28, 2022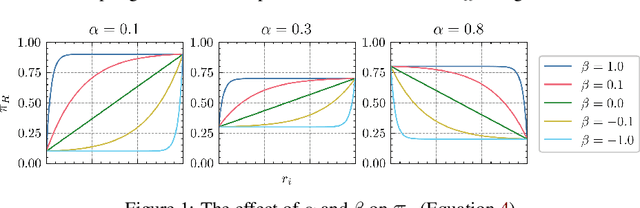
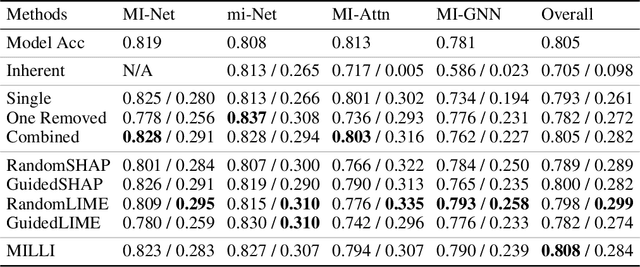
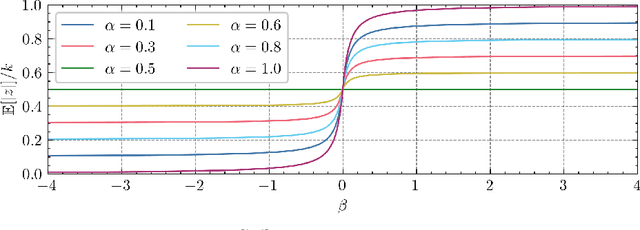
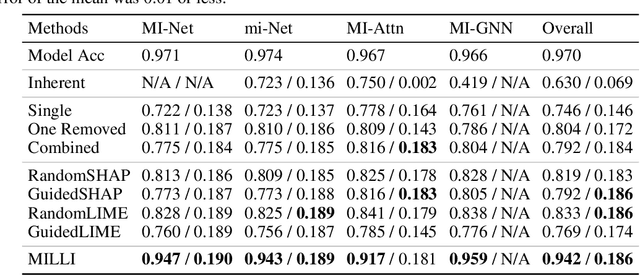
In Multiple Instance Learning (MIL), models are trained using bags of instances, where only a single label is provided for each bag. A bag label is often only determined by a handful of key instances within a bag, making it difficult to interpret what information a classifier is using to make decisions. In this work, we establish the key requirements for interpreting MIL models. We then go on to develop several model-agnostic approaches that meet these requirements. Our methods are compared against existing inherently interpretable MIL models on several datasets, and achieve an increase in interpretability accuracy of up to 30%. We also examine the ability of the methods to identify interactions between instances and scale to larger datasets, improving their applicability to real-world problems.