 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Metrics for Human-Subjects Evaluation in Explainable Reinforcement Learning
Jan 31, 2025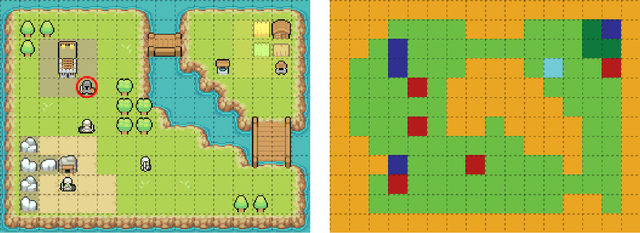


Explanation is a fundamentally human process. Understanding the goal and audience of the explanation is vital, yet existing work on explainable reinforcement learning (XRL) routinely does not consult humans in their evaluations. Even when they do, they routinely resort to subjective metrics, such as confidence or understanding, that can only inform researchers of users' opinions, not their practical effectiveness for a given problem. This paper calls on researchers to use objective human metrics for explanation evaluations based on observable and actionable behaviour to build more reproducible, comparable, and epistemically grounded research. To this end, we curate, describe, and compare several objective evaluation methodologies for applying explanations to debugging agent behaviour and supporting human-agent teaming, illustrating our proposed methods using a novel grid-based environment. We discuss how subjective and objective metrics complement each other to provide holistic validation and how future work needs to utilise standardised benchmarks for testing to enable greater comparisons between research.
Beyond The Rainbow: High Performance Deep Reinforcement Learning On A Desktop PC
Nov 06, 2024



Rainbow Deep Q-Network (DQN) demonstrated combining multiple independent enhancements could significantly boost a reinforcement learning (RL) agent's performance. In this paper, we present "Beyond The Rainbow" (BTR), a novel algorithm that integrates six improvements from across the RL literature to Rainbow DQN, establishing a new state-of-the-art for RL using a desktop PC, with a human-normalized interquartile mean (IQM) of 7.4 on atari-60. Beyond Atari, we demonstrate BTR's capability to handle complex 3D games, successfully training agents to play Super Mario Galaxy, Mario Kart, and Mortal Kombat with minimal algorithmic changes. Designing BTR with computational efficiency in mind, agents can be trained using a desktop PC on 200 million Atari frames within 12 hours. Additionally, we conduct detailed ablation studies of each component, analzying the performance and impact using numerous measures.
Explaining an Agent's Future Beliefs through Temporally Decomposing Future Reward Estimators
Aug 15, 2024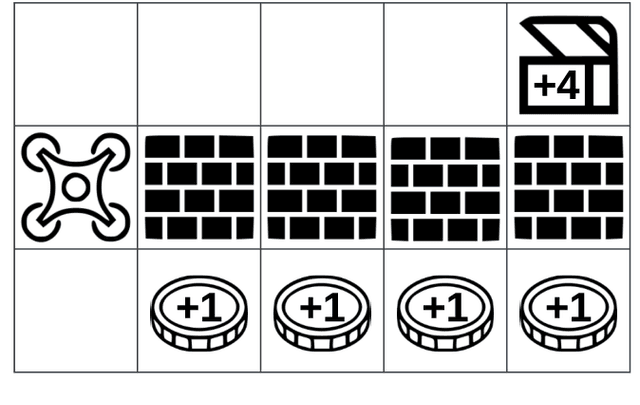
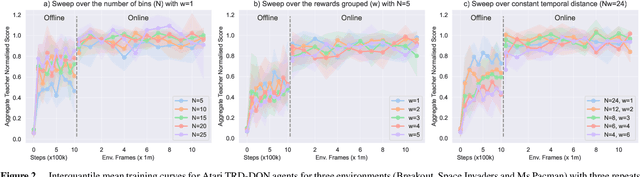
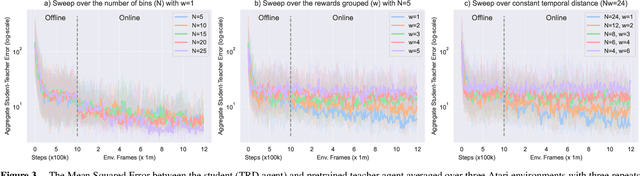
Future reward estimation is a core component of reinforcement learning agents; i.e., Q-value and state-value functions, predicting an agent's sum of future rewards. Their scalar output, however, obfuscates when or what individual future rewards an agent may expect to receive. We address this by modifying an agent's future reward estimator to predict their next N expected rewards, referred to as Temporal Reward Decomposition (TRD). This unlocks novel explanations of agent behaviour. Through TRD we can: estimate when an agent may expect to receive a reward, the value of the reward and the agent's confidence in receiving it; measure an input feature's temporal importance to the agent's action decisions; and predict the influence of different actions on future rewards. Furthermore, we show that DQN agents trained on Atari environments can be efficiently retrained to incorporate TRD with minimal impact on performance.
* 7 pages + 3 pages of supplementary material. Published at ECAI 2024
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Jul 24, 2024
Gymnasium is an open-source library providing an API for reinforcement learning environments. Its main contribution is a central abstraction for wide interoperability between benchmark environments and training algorithms. Gymnasium comes with various built-in environments and utilities to simplify researchers' work along with being supported by most training libraries. This paper outlines the main design decisions for Gymnasium, its key features, and the differences to alternative APIs.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks
Jun 24, 2023


We present the Minigrid and Miniworld libraries which provide a suite of goal-oriented 2D and 3D environments. The libraries were explicitly created with a minimalistic design paradigm to allow users to rapidly develop new environments for a wide range of research-specific needs. As a result, both have received widescale adoption by the RL community, facilitating research in a wide range of areas. In this paper, we outline the design philosophy, environment details, and their world generation API. We also showcase the additional capabilities brought by the unified API between Minigrid and Miniworld through case studies on transfer learning (for both RL agents and humans) between the different observation spaces. The source code of Minigrid and Miniworld can be found at https://github.com/Farama-Foundation/{Minigrid, Miniworld} along with their documentation at https://{minigrid, miniworld}.farama.org/.