 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperKKL: Enabling Non-Autonomous State Estimation through Dynamic Weight Conditioning
Feb 26, 2026This paper proposes HyperKKL, a novel learning approach for designing Kazantzis-Kravaris/Luenberger (KKL) observers for non-autonomous nonlinear systems. While KKL observers offer a rigorous theoretical framework by immersing nonlinear dynamics into a stable linear latent space, its practical realization relies on solving Partial Differential Equations (PDE) that are analytically intractable. Current existing learning-based approximations of the KKL observer are mostly designed for autonomous systems, failing to generalize to driven dynamics without expensive retraining or online gradient updates. HyperKKL addresses this by employing a hypernetwork architecture that encodes the exogenous input signal to instantaneously generate the parameters of the KKL observer, effectively learning a family of immersion maps parameterized by the external drive. We rigorously evaluate this approach against a curriculum learning strategy that attempts to generalize from autonomous regimes via training heuristics alone. The novel approach is illustrated on four numerical simulations in benchmark examples including the Duffing, Van der Pol, Lorenz, and Rössler systems.
Zero-Shot Off-Policy Learning
Feb 02, 2026Off-policy learning methods seek to derive an optimal policy directly from a fixed dataset of prior interactions. This objective presents significant challenges, primarily due to the inherent distributional shift and value function overestimation bias. These issues become even more noticeable in zero-shot reinforcement learning, where an agent trained on reward-free data must adapt to new tasks at test time without additional training. In this work, we address the off-policy problem in a zero-shot setting by discovering a theoretical connection of successor measures to stationary density ratios. Using this insight, our algorithm can infer optimal importance sampling ratios, effectively performing a stationary distribution correction with an optimal policy for any task on the fly. We benchmark our method in motion tracking tasks on SMPL Humanoid, continuous control on ExoRL, and for the long-horizon OGBench tasks. Our technique seamlessly integrates into forward-backward representation frameworks and enables fast-adaptation to new tasks in a training-free regime. More broadly, this work bridges off-policy learning and zero-shot adaptation, offering benefits to both research areas.
ArabicDialectHub: A Cross-Dialectal Arabic Learning Resource and Platform
Jan 30, 2026We present ArabicDialectHub, a cross-dialectal Arabic learning resource comprising 552 phrases across six varieties (Moroccan Darija, Lebanese, Syrian, Emirati, Saudi, and MSA) and an interactive web platform. Phrases were generated using LLMs and validated by five native speakers, stratified by difficulty, and organized thematically. The open-source platform provides translation exploration, adaptive quizzing with algorithmic distractor generation, cloud-synchronized progress tracking, and cultural context. Both the dataset and complete platform source code are released under MIT license. Platform: https://arabic-dialect-hub.netlify.app.
CORE: Collaborative Reasoning via Cross Teaching
Jan 29, 2026Large language models exhibit complementary reasoning errors: on the same instance, one model may succeed with a particular decomposition while another fails. We propose Collaborative Reasoning (CORE), a training-time collaboration framework that converts peer success into a learning signal via a cross-teaching protocol. Each problem is solved in two stages: a cold round of independent sampling, followed by a contexted rescue round in which models that failed receive hint extracted from a successful peer. CORE optimizes a combined reward that balances (i) correctness, (ii) a lightweight DPP-inspired diversity term to reduce error overlap, and (iii) an explicit rescue bonus for successful recovery. We evaluate CORE across four standard reasoning datasets GSM8K, MATH, AIME, and GPQA. With only 1,000 training examples, a pair of small open source models (3B+4B) reaches Pass@2 of 99.54% on GSM8K and 92.08% on MATH, compared to 82.50% and 74.82% for single-model training. On harder datasets, the 3B+4B pair reaches Pass@2 of 77.34% on GPQA (trained on 348 examples) and 79.65% on AIME (trained on 792 examples), using a training-time budget of at most 1536 context tokens and 3072 generated tokens. Overall, these results show that training-time collaboration can reliably convert model complementarity into large gains without scaling model size.
SD-E$^2$: Semantic Exploration for Reasoning Under Token Budgets
Jan 25, 2026Small language models (SLMs) struggle with complex reasoning because exploration is expensive under tight compute budgets. We introduce Semantic Diversity-Exploration-Exploitation (SD-E$^2$), a reinforcement learning framework that makes exploration explicit by optimizing semantic diversity in generated reasoning trajectories. Using a frozen sentence-embedding model, SD-E$^2$ assigns a diversity reward that captures (i) the coverage of semantically distinct solution strategies and (ii) their average pairwise dissimilarity in embedding space, rather than surface-form novelty. This diversity reward is combined with outcome correctness and solution efficiency in a z-score-normalized multi-objective objective that stabilizes training. On GSM8K, SD-E$^2$ surpasses the base Qwen2.5-3B-Instruct and strong GRPO baselines (GRPO-CFL and GRPO-CFEE) by +27.4, +5.2, and +1.5 percentage points, respectively, while discovering on average 9.8 semantically distinct strategies per question. We further improve MedMCQA to 49.64% versus 38.37% for the base model and show gains on the harder AIME benchmark (1983-2025), reaching 13.28% versus 6.74% for the base. These results indicate that rewarding semantic novelty yields a more compute-efficient exploration-exploitation signal for training reasoning-capable SLMs. By introducing cognitive adaptation-adjusting the reasoning process structure rather than per-token computation-SD-E$^2$ offers a complementary path to efficiency gains in resource-constrained models.
SVRPBench: A Realistic Benchmark for Stochastic Vehicle Routing Problem
May 29, 2025



Robust routing under uncertainty is central to real-world logistics, yet most benchmarks assume static, idealized settings. We present SVRPBench, the first open benchmark to capture high-fidelity stochastic dynamics in vehicle routing at urban scale. Spanning more than 500 instances with up to 1000 customers, it simulates realistic delivery conditions: time-dependent congestion, log-normal delays, probabilistic accidents, and empirically grounded time windows for residential and commercial clients. Our pipeline generates diverse, constraint-rich scenarios, including multi-depot and multi-vehicle setups. Benchmarking reveals that state-of-the-art RL solvers like POMO and AM degrade by over 20% under distributional shift, while classical and metaheuristic methods remain robust. To enable reproducible research, we release the dataset and evaluation suite. SVRPBench challenges the community to design solvers that generalize beyond synthetic assumptions and adapt to real-world uncertainty.
Semantic Communication meets System 2 ML: How Abstraction, Compositionality and Emergent Languages Shape Intelligence
May 27, 2025The trajectories of 6G and AI are set for a creative collision. However, current visions for 6G remain largely incremental evolutions of 5G, while progress in AI is hampered by brittle, data-hungry models that lack robust reasoning capabilities. This paper argues for a foundational paradigm shift, moving beyond the purely technical level of communication toward systems capable of semantic understanding and effective, goal-oriented interaction. We propose a unified research vision rooted in the principles of System-2 cognition, built upon three pillars: Abstraction, enabling agents to learn meaningful world models from raw sensorimotor data; Compositionality, providing the algebraic tools to combine learned concepts and subsystems; and Emergent Communication, allowing intelligent agents to create their own adaptive and grounded languages. By integrating these principles, we lay the groundwork for truly intelligent systems that can reason, adapt, and collaborate, unifying advances in wireless communications, machine learning, and robotics under a single coherent framework.
Loss-Guided Auxiliary Agents for Overcoming Mode Collapse in GFlowNets
May 21, 2025

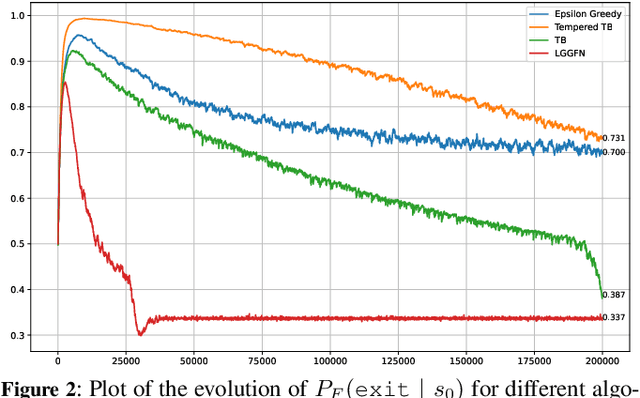
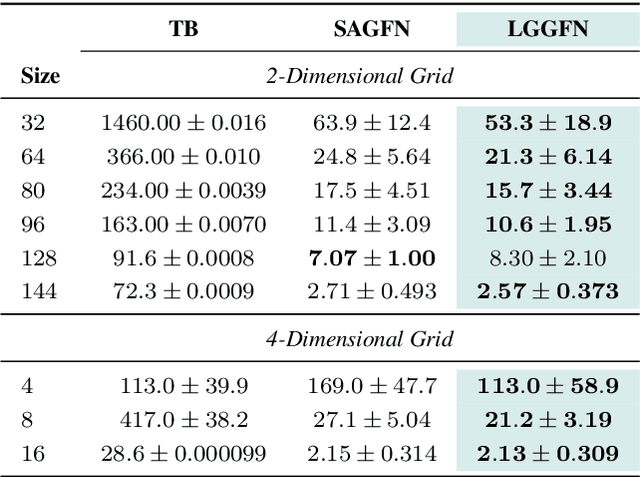
Although Generative Flow Networks (GFlowNets) are designed to capture multiple modes of a reward function, they often suffer from mode collapse in practice, getting trapped in early discovered modes and requiring prolonged training to find diverse solutions. Existing exploration techniques may rely on heuristic novelty signals. We propose Loss-Guided GFlowNets (LGGFN), a novel approach where an auxiliary GFlowNet's exploration is directly driven by the main GFlowNet's training loss. By prioritizing trajectories where the main model exhibits high loss, LGGFN focuses sampling on poorly understood regions of the state space. This targeted exploration significantly accelerates the discovery of diverse, high-reward samples. Empirically, across various benchmarks including grid environments, structured sequence generation, and Bayesian structure learning, LGGFN consistently enhances exploration efficiency and sample diversity compared to baselines. For instance, on a challenging sequence generation task, it discovered over 40 times more unique valid modes while simultaneously reducing the exploration error metric by approximately 99\%.
LLM-BABYBENCH: Understanding and Evaluating Grounded Planning and Reasoning in LLMs
May 17, 2025



Assessing the capacity of Large Language Models (LLMs) to plan and reason within the constraints of interactive environments is crucial for developing capable AI agents. We introduce $\textbf{LLM-BabyBench}$, a new benchmark suite designed specifically for this purpose. Built upon a textual adaptation of the procedurally generated BabyAI grid world, this suite evaluates LLMs on three fundamental aspects of grounded intelligence: (1) predicting the consequences of actions on the environment state ($\textbf{Predict}$ task), (2) generating sequences of low-level actions to achieve specified objectives ($\textbf{Plan}$ task), and (3) decomposing high-level instructions into coherent subgoal sequences ($\textbf{Decompose}$ task). We detail the methodology for generating the three corresponding datasets ($\texttt{LLM-BabyBench-Predict}$, $\texttt{-Plan}$, $\texttt{-Decompose}$) by extracting structured information from an expert agent operating within the text-based environment. Furthermore, we provide a standardized evaluation harness and metrics, including environment interaction for validating generated plans, to facilitate reproducible assessment of diverse LLMs. Initial baseline results highlight the challenges posed by these grounded reasoning tasks. The benchmark suite, datasets, data generation code, and evaluation code are made publicly available ($\href{https://github.com/choukrani/llm-babybench}{\text{GitHub}}$, $\href{https://huggingface.co/datasets/salem-mbzuai/LLM-BabyBench}{\text{HuggingFace}}$).
Mitigating Societal Cognitive Overload in the Age of AI: Challenges and Directions
Apr 28, 2025Societal cognitive overload, driven by the deluge of information and complexity in the AI age, poses a critical challenge to human well-being and societal resilience. This paper argues that mitigating cognitive overload is not only essential for improving present-day life but also a crucial prerequisite for navigating the potential risks of advanced AI, including existential threats. We examine how AI exacerbates cognitive overload through various mechanisms, including information proliferation, algorithmic manipulation, automation anxieties, deregulation, and the erosion of meaning. The paper reframes the AI safety debate to center on cognitive overload, highlighting its role as a bridge between near-term harms and long-term risks. It concludes by discussing potential institutional adaptations, research directions, and policy considerations that arise from adopting an overload-resilient perspective on human-AI alignment, suggesting pathways for future exploration rather than prescribing definitive solutions.