 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlining the design space of eXplainable swarm (xSwarm): experts perspective
Sep 03, 2023


In swarm robotics, agents interact through local roles to solve complex tasks beyond an individual's ability. Even though swarms are capable of carrying out some operations without the need for human intervention, many safety-critical applications still call for human operators to control and monitor the swarm. There are novel challenges to effective Human-Swarm Interaction (HSI) that are only beginning to be addressed. Explainability is one factor that can facilitate effective and trustworthy HSI and improve the overall performance of Human-Swarm team. Explainability was studied across various Human-AI domains, such as Human-Robot Interaction and Human-Centered ML. However, it is still ambiguous whether explanations studied in Human-AI literature would be beneficial in Human-Swarm research and development. Furthermore, the literature lacks foundational research on the prerequisites for explainability requirements in swarm robotics, i.e., what kind of questions an explainable swarm is expected to answer, and what types of explanations a swarm is expected to generate. By surveying 26 swarm experts, we seek to answer these questions and identify challenges experts faced to generate explanations in Human-Swarm environments. Our work contributes insights into defining a new area of research of eXplainable Swarm (xSwarm) which looks at how explainability can be implemented and developed in swarm systems. This paper opens the discussion on xSwarm and paves the way for more research in the field.
Scene-to-Patch Earth Observation: Multiple Instance Learning for Land Cover Classification
Nov 15, 2022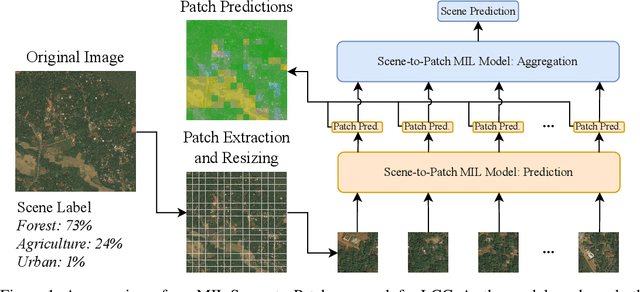
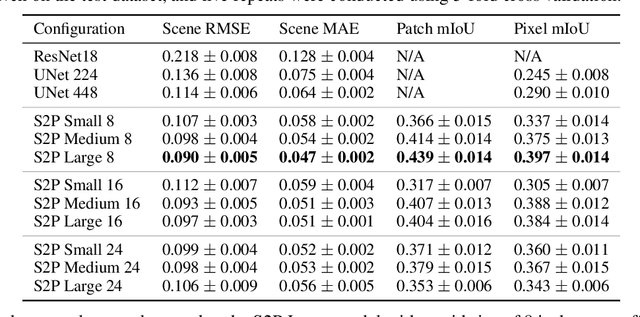

Land cover classification (LCC), and monitoring how land use changes over time, is an important process in climate change mitigation and adaptation. Existing approaches that use machine learning with Earth observation data for LCC rely on fully-annotated and segmented datasets. Creating these datasets requires a large amount of effort, and a lack of suitable datasets has become an obstacle in scaling the use of LCC. In this study, we propose Scene-to-Patch models: an alternative LCC approach utilising Multiple Instance Learning (MIL) that requires only high-level scene labels. This enables much faster development of new datasets whilst still providing segmentation through patch-level predictions, ultimately increasing the accessibility of using LCC for different scenarios. On the DeepGlobe-LCC dataset, our approach outperforms non-MIL baselines on both scene- and patch-level prediction. This work provides the foundation for expanding the use of LCC in climate change mitigation methods for technology, government, and academia.
Non-Markovian Reward Modelling from Trajectory Labels via Interpretable Multiple Instance Learning
May 30, 2022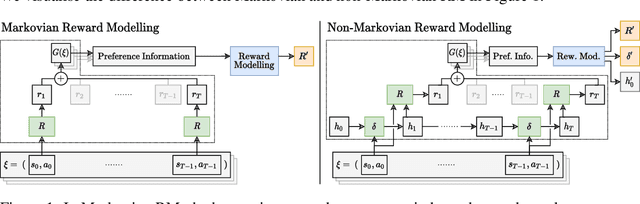

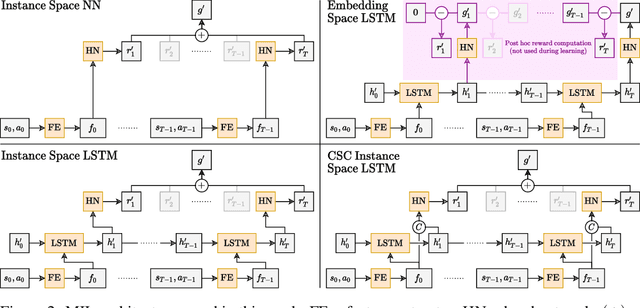

We generalise the problem of reward modelling (RM) for reinforcement learning (RL) to handle non-Markovian rewards. Existing work assumes that human evaluators observe each step in a trajectory independently when providing feedback on agent behaviour. In this work, we remove this assumption, extending RM to include hidden state information that captures temporal dependencies in human assessment of trajectories. We then show how RM can be approached as a multiple instance learning (MIL) problem, and develop new MIL models that are able to capture the time dependencies in labelled trajectories. We demonstrate on a range of RL tasks that our novel MIL models can reconstruct reward functions to a high level of accuracy, and that they provide interpretable learnt hidden information that can be used to train high-performing agent policies.
Resilient robot teams: a review integrating decentralised control, change-detection, and learning
Apr 21, 2022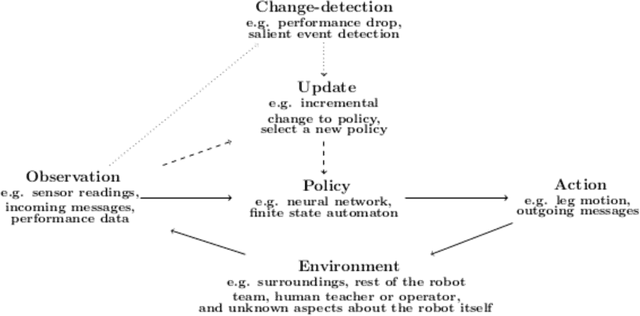
Purpose of review: This paper reviews opportunities and challenges for decentralised control, change-detection, and learning in the context of resilient robot teams. Recent findings: Exogenous fault detection methods can provide a generic detection or a specific diagnosis with a recovery solution. Robot teams can perform active and distributed sensing for detecting changes in the environment, including identifying and tracking dynamic anomalies, as well as collaboratively mapping dynamic environments. Resilient methods for decentralised control have been developed in learning perception-action-communication loops, multi-agent reinforcement learning, embodied evolution, offline evolution with online adaptation, explicit task allocation, and stigmergy in swarm robotics. Summary: Remaining challenges for resilient robot teams are integrating change-detection and trial-and-error learning methods, obtaining reliable performance evaluations under constrained evaluation time, improving the safety of resilient robot teams, theoretical results demonstrating rapid adaptation to given environmental perturbations, and designing realistic and compelling case studies.
Learning from the Pros: Extracting Professional Goalkeeper Technique from Broadcast Footage
Feb 22, 2022
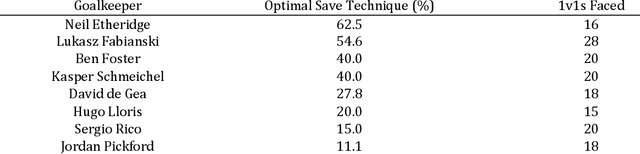


As an amateur goalkeeper playing grassroots soccer, who better to learn from than top professional goalkeepers? In this paper, we harness computer vision and machine learning models to appraise the save technique of professionals in a way those at lower levels can learn from. We train an unsupervised machine learning model using 3D body pose data extracted from broadcast footage to learn professional goalkeeper technique. Then, an "expected saves" model is developed, from which we can identify the optimal goalkeeper technique in different match contexts.
Model Agnostic Interpretability for Multiple Instance Learning
Jan 28, 2022
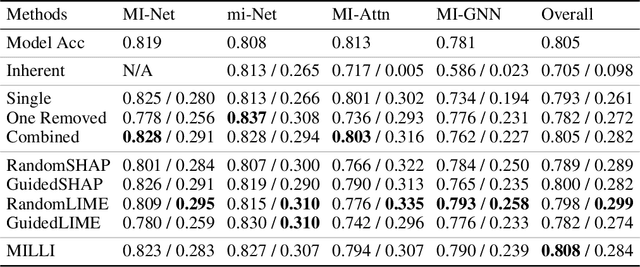
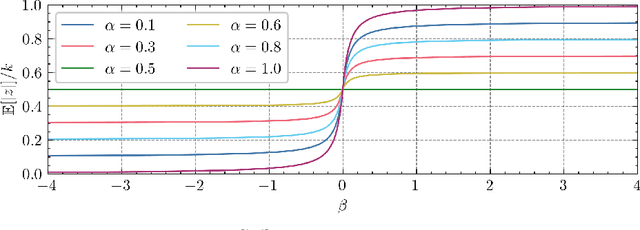
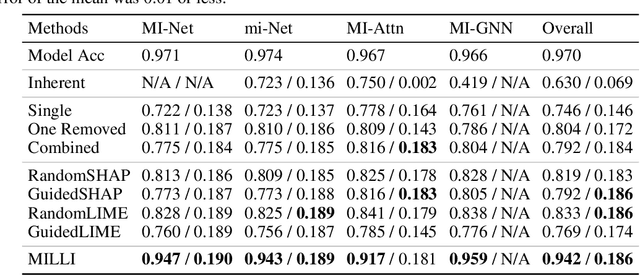
In Multiple Instance Learning (MIL), models are trained using bags of instances, where only a single label is provided for each bag. A bag label is often only determined by a handful of key instances within a bag, making it difficult to interpret what information a classifier is using to make decisions. In this work, we establish the key requirements for interpreting MIL models. We then go on to develop several model-agnostic approaches that meet these requirements. Our methods are compared against existing inherently interpretable MIL models on several datasets, and achieve an increase in interpretability accuracy of up to 30%. We also examine the ability of the methods to identify interactions between instances and scale to larger datasets, improving their applicability to real-world problems.
What Happened Next? Using Deep Learning to Value Defensive Actions in Football Event-Data
Jun 03, 2021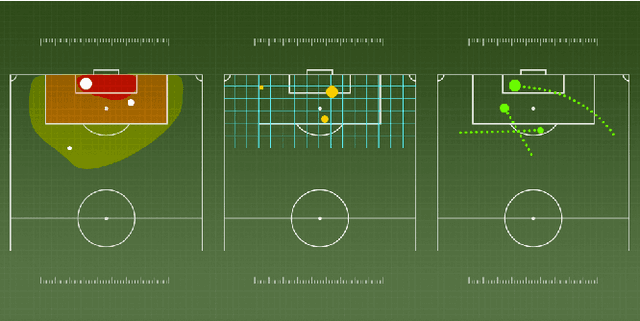
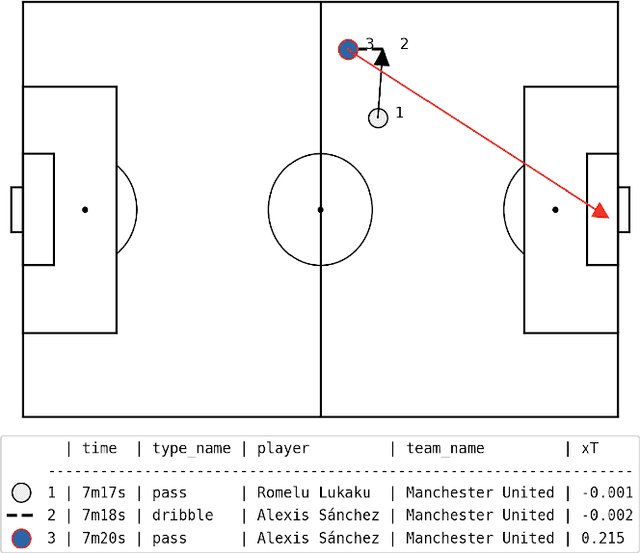
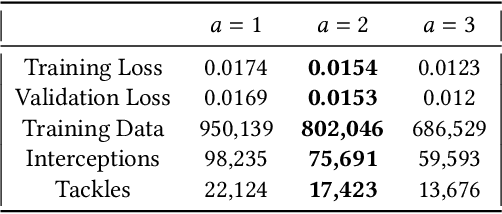
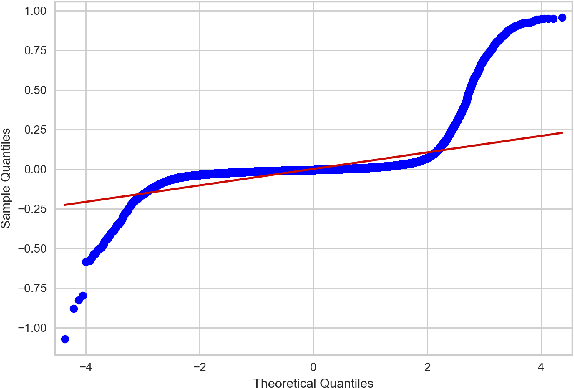
Objectively quantifying the value of player actions in football (soccer) is a challenging problem. To date, studies in football analytics have mainly focused on the attacking side of the game, while there has been less work on event-driven metrics for valuing defensive actions (e.g., tackles and interceptions). Therefore in this paper, we use deep learning techniques to define a novel metric that values such defensive actions by studying the threat of passages of play that preceded them. By doing so, we are able to value defensive actions based on what they prevented from happening in the game. Our Defensive Action Expected Threat (DAxT) model has been validated using real-world event-data from the 2017/2018 and 2018/2019 English Premier League seasons, and we combine our model outputs with additional features to derive an overall rating of defensive ability for players. Overall, we find that our model is able to predict the impact of defensive actions allowing us to better value defenders using event-data.
Mechanism Design for Efficient Online and Offline Allocation of Electric Vehicles to Charging Stations
Jul 19, 2020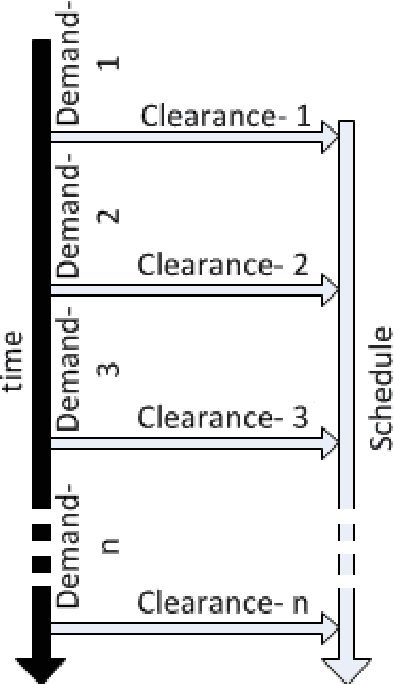

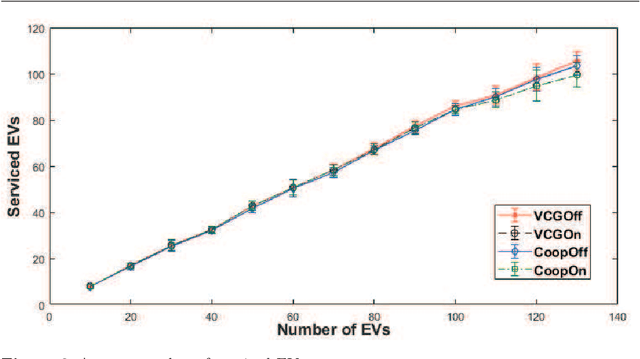
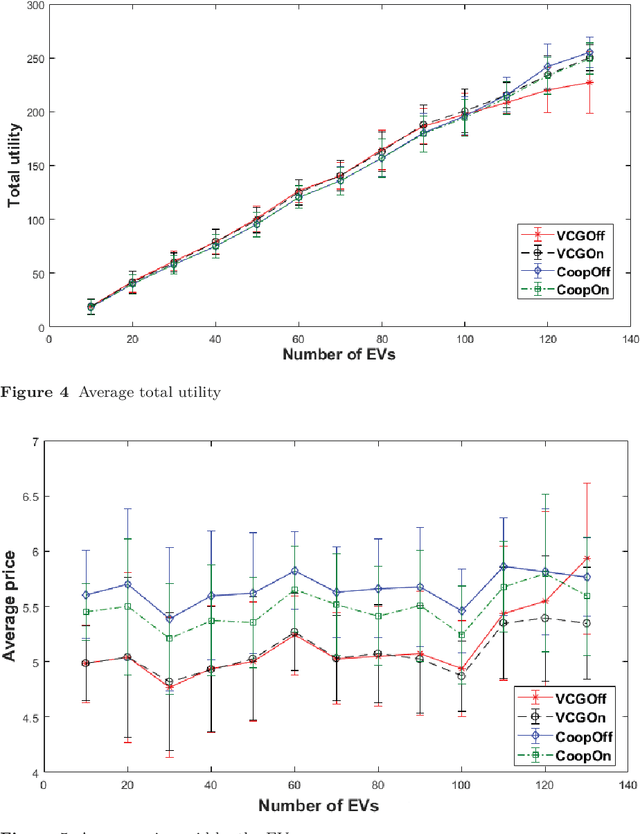
We study the problem of allocating Electric Vehicles (EVs) to charging stations and scheduling their charging. We develop offline and online solutions that treat EV users as self-interested agents that aim to maximise their profit and minimise the impact on their schedule. We formulate the problem of the optimal EV to charging station allocation as a Mixed Integer Programming (MIP) one and we propose two pricing mechanisms: A fixed-price one, and another that is based on the well known Vickrey-Clark-Groves (VCG) mechanism. Later, we develop online solutions that incrementally call the MIP-based algorithm. We empirically evaluate our mechanisms and we observe that both scale well. Moreover, the VCG mechanism services on average $1.5\%$ more EVs than the fixed-price one. In addition, when the stations get congested, VCG leads to higher prices for the EVs and higher profit for the stations, but lower utility for the EVs. However, we theoretically prove that the VCG mechanism guarantees truthful reporting of the EVs' preferences. In contrast, the fixed-price one is vulnerable to agents' strategic behaviour as non-truthful EVs can charge in place of truthful ones. Finally, we observe that the online algorithms are on average at $98\%$ of the optimal in EV satisfaction.