 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruthful Meta-Explanations for Local Interpretability of Machine Learning Models
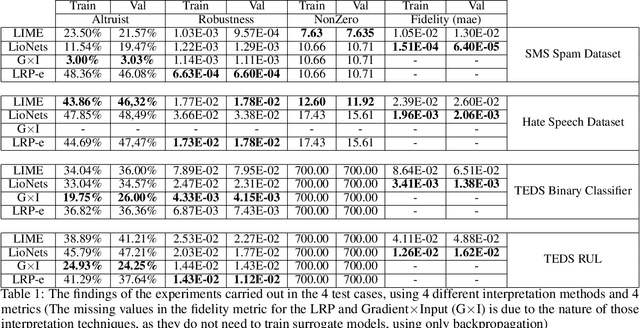
Dec 07, 2022Automated Machine Learning-based systems' integration into a wide range of tasks has expanded as a result of their performance and speed. Although there are numerous advantages to employing ML-based systems, if they are not interpretable, they should not be used in critical, high-risk applications where human lives are at risk. To address this issue, researchers and businesses have been focusing on finding ways to improve the interpretability of complex ML systems, and several such methods have been developed. Indeed, there are so many developed techniques that it is difficult for practitioners to choose the best among them for their applications, even when using evaluation metrics. As a result, the demand for a selection tool, a meta-explanation technique based on a high-quality evaluation metric, is apparent. In this paper, we present a local meta-explanation technique which builds on top of the truthfulness metric, which is a faithfulness-based metric. We demonstrate the effectiveness of both the technique and the metric by concretely defining all the concepts and through experimentation.
Local Multi-Label Explanations for Random Forest
Jul 05, 2022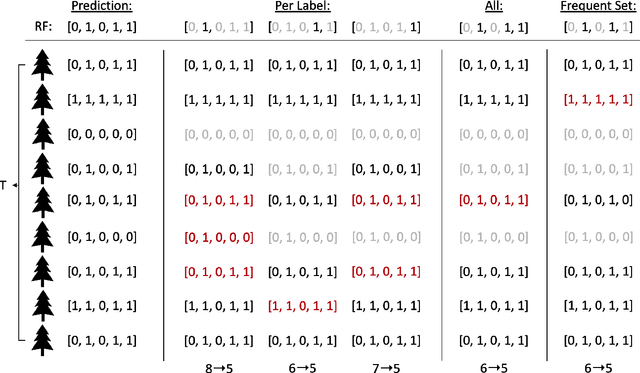

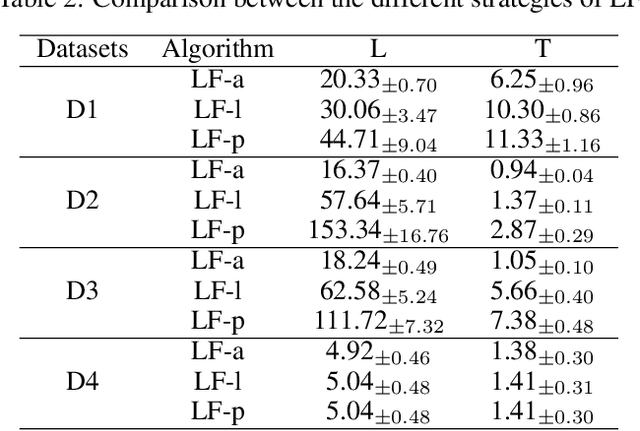

Multi-label classification is a challenging task, particularly in domains where the number of labels to be predicted is large. Deep neural networks are often effective at multi-label classification of images and textual data. When dealing with tabular data, however, conventional machine learning algorithms, such as tree ensembles, appear to outperform competition. Random forest, being a popular ensemble algorithm, has found use in a wide range of real-world problems. Such problems include fraud detection in the financial domain, crime hotspot detection in the legal sector, and in the biomedical field, disease probability prediction when patient records are accessible. Since they have an impact on people's lives, these domains usually require decision-making systems to be explainable. Random Forest falls short on this property, especially when a large number of tree predictors are used. This issue was addressed in a recent research named LionForests, regarding single label classification and regression. In this work, we adapt this technique to multi-label classification problems, by employing three different strategies regarding the labels that the explanation covers. Finally, we provide a set of qualitative and quantitative experiments to assess the efficacy of this approach.
Local Explanation of Dimensionality Reduction
Apr 29, 2022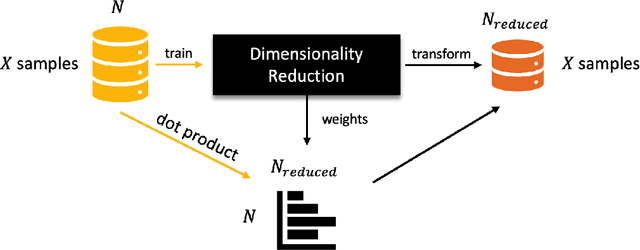
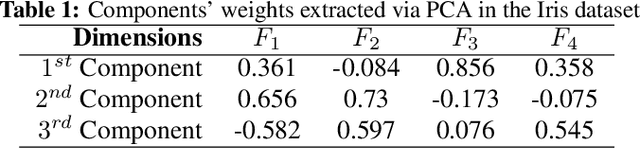
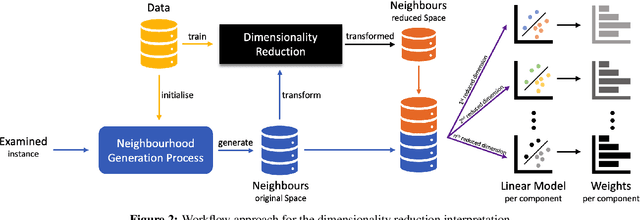

Dimensionality reduction (DR) is a popular method for preparing and analyzing high-dimensional data. Reduced data representations are less computationally intensive and easier to manage and visualize, while retaining a significant percentage of their original information. Aside from these advantages, these reduced representations can be difficult or impossible to interpret in most circumstances, especially when the DR approach does not provide further information about which features of the original space led to their construction. This problem is addressed by Interpretable Machine Learning, a subfield of Explainable Artificial Intelligence that addresses the opacity of machine learning models. However, current research on Interpretable Machine Learning has been focused on supervised tasks, leaving unsupervised tasks like Dimensionality Reduction unexplored. In this paper, we introduce LXDR, a technique capable of providing local interpretations of the output of DR techniques. Experiment results and two LXDR use case examples are presented to evaluate its usefulness.
VisioRed: A Visualisation Tool for Interpretable Predictive Maintenance
Apr 14, 2021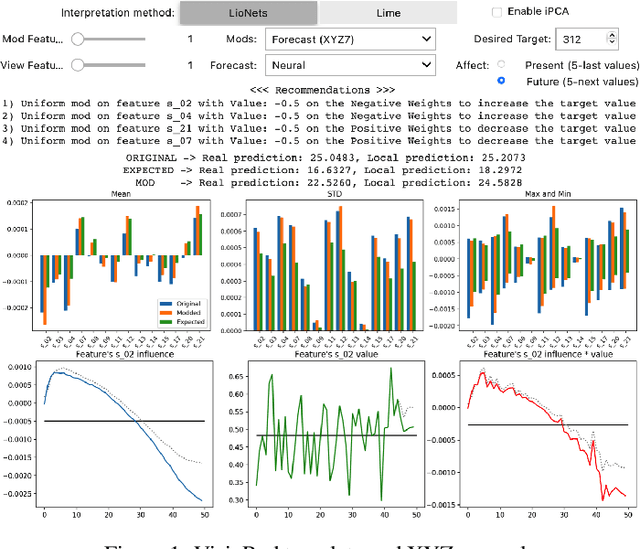
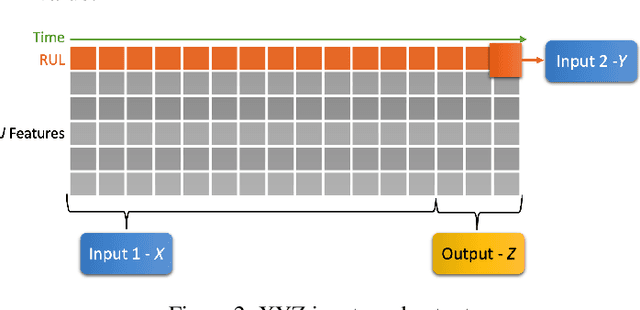
The use of machine learning rapidly increases in high-risk scenarios where decisions are required, for example in healthcare or industrial monitoring equipment. In crucial situations, a model that can offer meaningful explanations of its decision-making is essential. In industrial facilities, the equipment's well-timed maintenance is vital to ensure continuous operation to prevent money loss. Using machine learning, predictive and prescriptive maintenance attempt to anticipate and prevent eventual system failures. This paper introduces a visualisation tool incorporating interpretations to display information derived from predictive maintenance models, trained on time-series data.
LioNets: A Neural-Specific Local Interpretation Technique Exploiting Penultimate Layer Information
Apr 13, 2021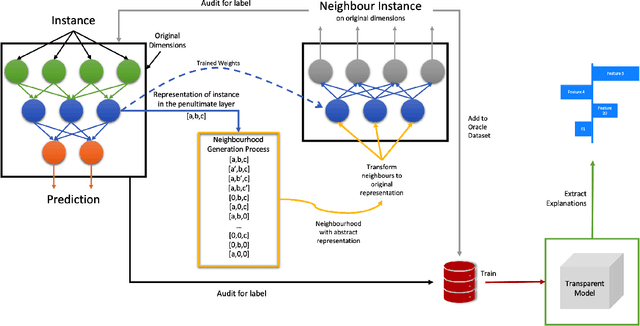
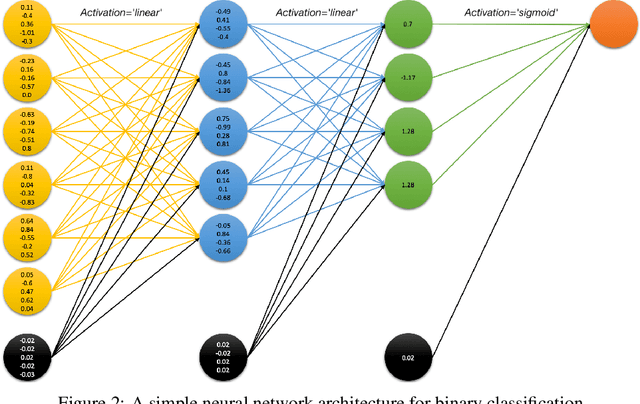

Artificial Intelligence (AI) has a tremendous impact on the unexpected growth of technology in almost every aspect. AI-powered systems are monitoring and deciding about sensitive economic and societal issues. The future is towards automation, and it must not be prevented. However, this is a conflicting viewpoint for a lot of people, due to the fear of uncontrollable AI systems. This concern could be reasonable if it was originating from considerations associated with social issues, like gender-biased, or obscure decision-making systems. Explainable AI (XAI) is recently treated as a huge step towards reliable systems, enhancing the trust of people to AI. Interpretable machine learning (IML), a subfield of XAI, is also an urgent topic of research. This paper presents a small but significant contribution to the IML community, focusing on a local-based, neural-specific interpretation process applied to textual and time-series data. The proposed methodology introduces new approaches to the presentation of feature importance based interpretations, as well as the production of counterfactual words on textual datasets. Eventually, an improved evaluation metric is introduced for the assessment of interpretation techniques, which supports an extensive set of qualitative and quantitative experiments.
Conclusive Local Interpretation Rules for Random Forests
Apr 13, 2021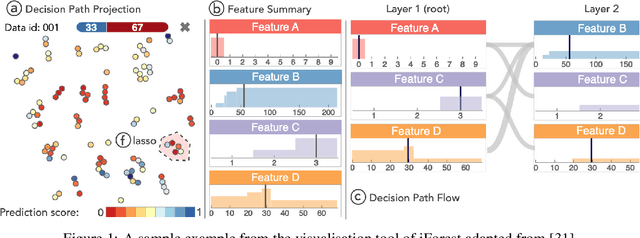


In critical situations involving discrimination, gender inequality, economic damage, and even the possibility of casualties, machine learning models must be able to provide clear interpretations for their decisions. Otherwise, their obscure decision-making processes can lead to socioethical issues as they interfere with people's lives. In the aforementioned sectors, random forest algorithms strive, thus their ability to explain themselves is an obvious requirement. In this paper, we present LionForests, which relies on a preliminary work of ours. LionForests is a random forest-specific interpretation technique, which provides rules as explanations. It is applicable from binary classification tasks to multi-class classification and regression tasks, and it is supported by a stable theoretical background. Experimentation, including sensitivity analysis and comparison with state-of-the-art techniques, is also performed to demonstrate the efficacy of our contribution. Finally, we highlight a unique property of LionForests, called conclusiveness, that provides interpretation validity and distinguishes it from previous techniques.
Altruist: Argumentative Explanations through Local Interpretations of Predictive Models
Oct 15, 2020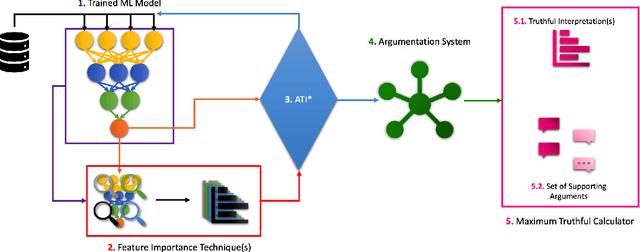
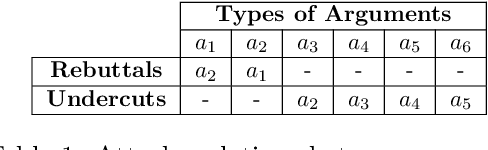
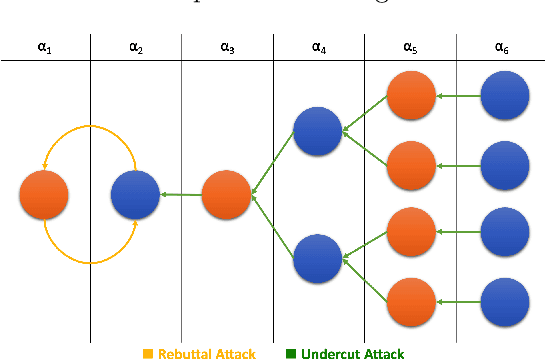
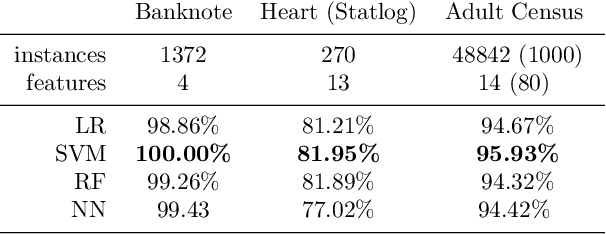
Interpretable machine learning is an emerging field providing solutions on acquiring insights into machine learning models' rationale. It has been put in the map of machine learning by suggesting ways to tackle key ethical and societal issues. However, existing techniques of interpretable machine learning are far from being comprehensible and explainable to the end user. Another key issue in this field is the lack of evaluation and selection criteria, making it difficult for the end user to choose the most appropriate interpretation technique for its use. In this study, we introduce a meta-explanation methodology that will provide truthful interpretations, in terms of feature importance, to the end user through argumentation. At the same time, this methodology can be used as an evaluation or selection tool for multiple interpretation techniques based on feature importance.
Mechanism Design for Efficient Online and Offline Allocation of Electric Vehicles to Charging Stations
Jul 19, 2020

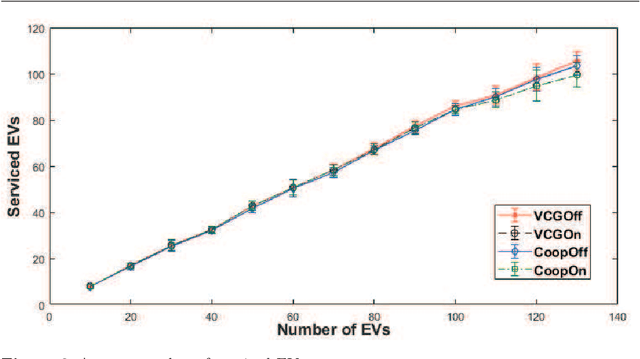
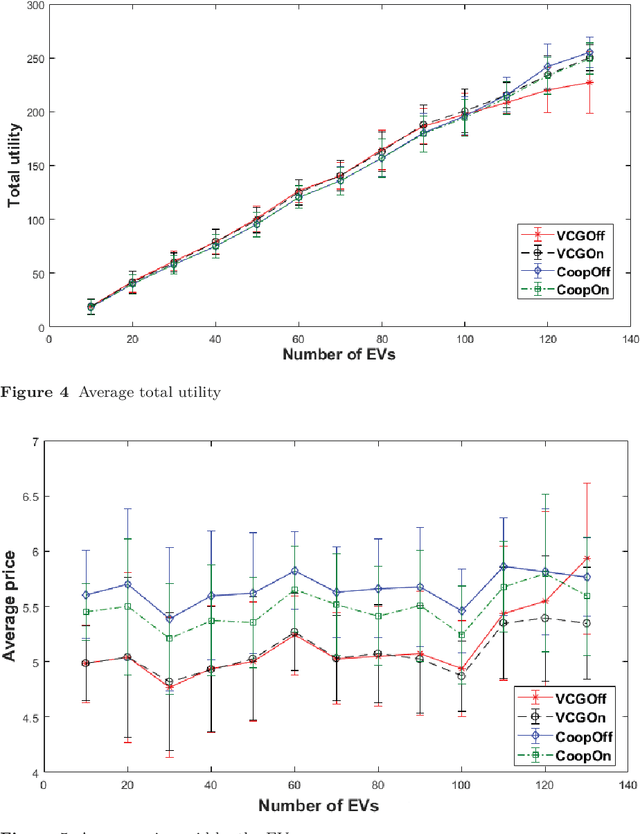
We study the problem of allocating Electric Vehicles (EVs) to charging stations and scheduling their charging. We develop offline and online solutions that treat EV users as self-interested agents that aim to maximise their profit and minimise the impact on their schedule. We formulate the problem of the optimal EV to charging station allocation as a Mixed Integer Programming (MIP) one and we propose two pricing mechanisms: A fixed-price one, and another that is based on the well known Vickrey-Clark-Groves (VCG) mechanism. Later, we develop online solutions that incrementally call the MIP-based algorithm. We empirically evaluate our mechanisms and we observe that both scale well. Moreover, the VCG mechanism services on average $1.5\%$ more EVs than the fixed-price one. In addition, when the stations get congested, VCG leads to higher prices for the EVs and higher profit for the stations, but lower utility for the EVs. However, we theoretically prove that the VCG mechanism guarantees truthful reporting of the EVs' preferences. In contrast, the fixed-price one is vulnerable to agents' strategic behaviour as non-truthful EVs can charge in place of truthful ones. Finally, we observe that the online algorithms are on average at $98\%$ of the optimal in EV satisfaction.
A Review on Intelligent Object Perception Methods Combining Knowledge-based Reasoning and Machine Learning
Dec 26, 2019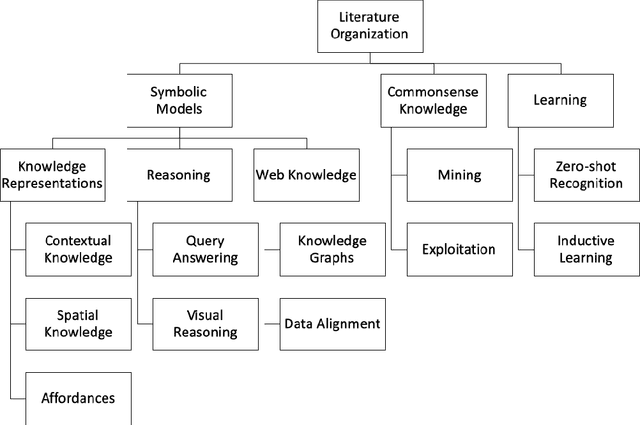
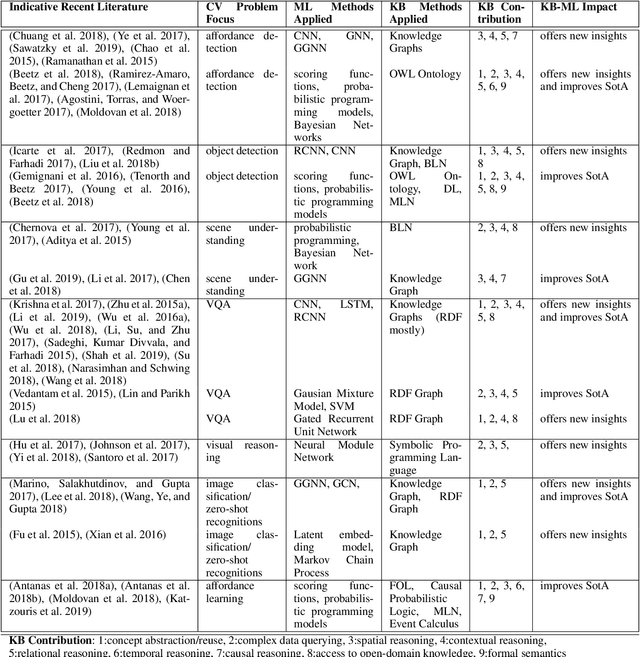
Object perception is a fundamental sub-field of Computer Vision, covering a multitude of individual areas and having contributed high-impact results. While Machine Learning has been traditionally applied to address related problems, recent works also seek ways to integrate knowledge engineering in order to expand the level of intelligence of the visual interpretation of objects, their properties and their relations with their environment. In this paper, we attempt a systematic investigation of how knowledge-based methods contribute to diverse object perception tasks. We review the latest achievements and identify prominent research directions.
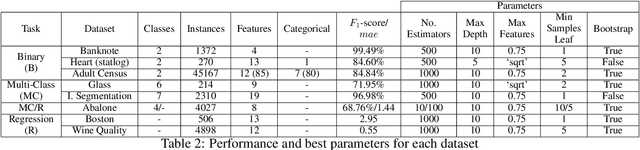
LionForests: Local Interpretation of Random Forests through Path Selection
Nov 20, 2019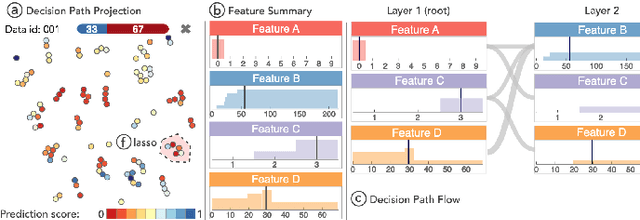

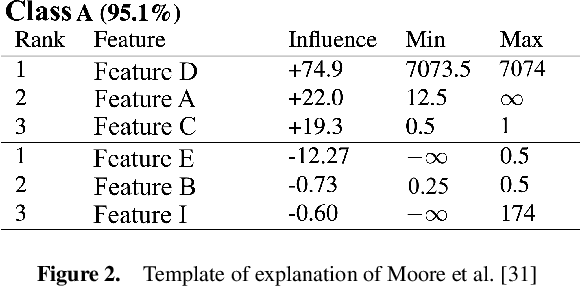

Towards a future where machine learning systems will integrate into every aspect of people's lives, researching methods to interpret such systems is necessary, instead of focusing exclusively on enhancing their performance. Enriching the trust between these systems and people will accelerate this integration process. Many medical and retail banking/finance applications use state-of-the-art machine learning techniques to predict certain aspects of new instances. Tree ensembles, like random forests, are widely acceptable solutions on these tasks, while at the same time they are avoided due to their black-box uninterpretable nature, creating an unreasonable paradox. In this paper, we provide a sequence of actions for shedding light on the predictions of the misjudged family of tree ensemble algorithms. Using classic unsupervised learning techniques and an enhanced similarity metric, to wander among transparent trees inside a forest following breadcrumbs, the interpretable essence of tree ensembles arises. An explanation provided by these systems using our approach, which we call "LionForests", can be a simple, comprehensive rule.