 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Task Text Classification Pipeline with Natural Language Explanations: A User-Centric Evaluation in Sentiment Analysis and Offensive Language Identification in Greek Tweets
Oct 14, 2024



Interpretability is a topic that has been in the spotlight for the past few years. Most existing interpretability techniques produce interpretations in the form of rules or feature importance. These interpretations, while informative, may be harder to understand for non-expert users and therefore, cannot always be considered as adequate explanations. To that end, explanations in natural language are often preferred, as they are easier to comprehend and also more presentable to end-users. This work introduces an early concept for a novel pipeline that can be used in text classification tasks, offering predictions and explanations in natural language. It comprises of two models: a classifier for labelling the text and an explanation generator which provides the explanation. The proposed pipeline can be adopted by any text classification task, given that ground truth rationales are available to train the explanation generator. Our experiments are centred around the tasks of sentiment analysis and offensive language identification in Greek tweets, using a Greek Large Language Model (LLM) to obtain the necessary explanations that can act as rationales. The experimental evaluation was performed through a user study based on three different metrics and achieved promising results for both datasets.
Local Interpretability of Random Forests for Multi-Target Regression
Mar 29, 2023Multi-target regression is useful in a plethora of applications. Although random forest models perform well in these tasks, they are often difficult to interpret. Interpretability is crucial in machine learning, especially when it can directly impact human well-being. Although model-agnostic techniques exist for multi-target regression, specific techniques tailored to random forest models are not available. To address this issue, we propose a technique that provides rule-based interpretations for instances made by a random forest model for multi-target regression, influenced by a recent model-specific technique for random forest interpretability. The proposed technique was evaluated through extensive experiments and shown to offer competitive interpretations compared to state-of-the-art techniques.
Improving Attention-Based Interpretability of Text Classification Transformers
Sep 22, 2022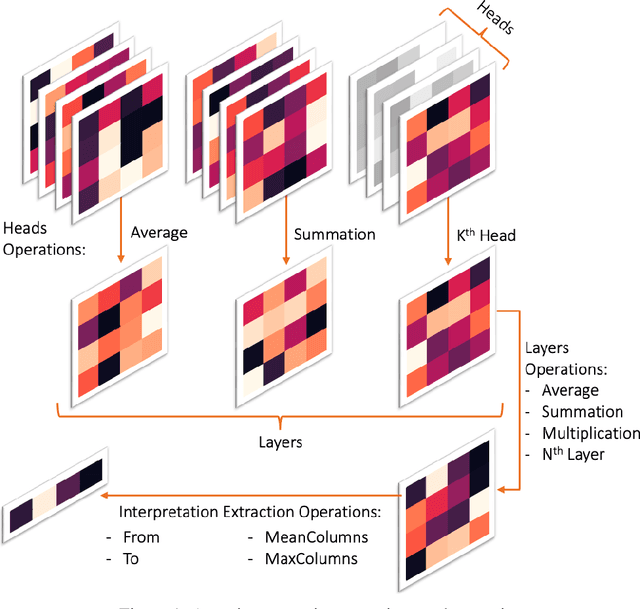
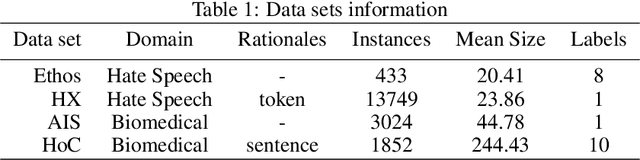
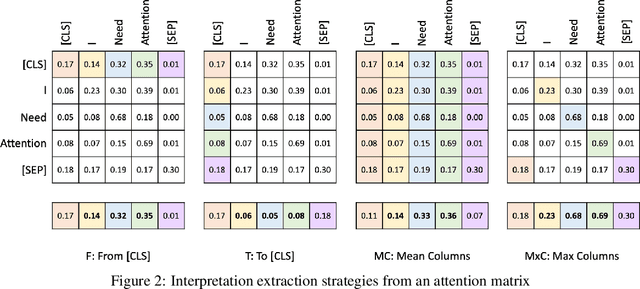
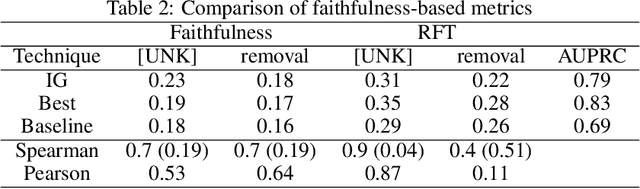
Transformers are widely used in NLP, where they consistently achieve state-of-the-art performance. This is due to their attention-based architecture, which allows them to model rich linguistic relations between words. However, transformers are difficult to interpret. Being able to provide reasoning for its decisions is an important property for a model in domains where human lives are affected, such as hate speech detection and biomedicine. With transformers finding wide use in these fields, the need for interpretability techniques tailored to them arises. The effectiveness of attention-based interpretability techniques for transformers in text classification is studied in this work. Despite concerns about attention-based interpretations in the literature, we show that, with proper setup, attention may be used in such tasks with results comparable to state-of-the-art techniques, while also being faster and friendlier to the environment. We validate our claims with a series of experiments that employ a new feature importance metric.
Local Multi-Label Explanations for Random Forest
Jul 05, 2022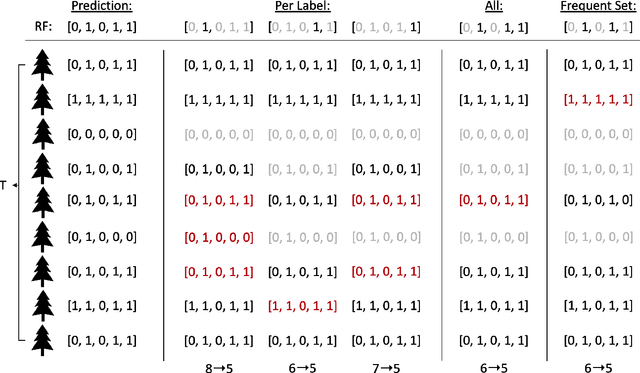

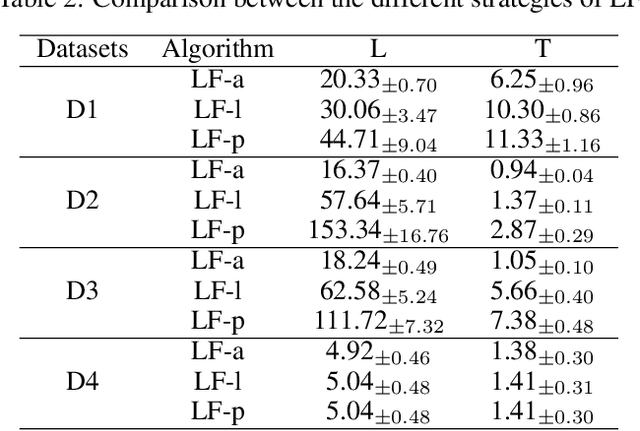

Multi-label classification is a challenging task, particularly in domains where the number of labels to be predicted is large. Deep neural networks are often effective at multi-label classification of images and textual data. When dealing with tabular data, however, conventional machine learning algorithms, such as tree ensembles, appear to outperform competition. Random forest, being a popular ensemble algorithm, has found use in a wide range of real-world problems. Such problems include fraud detection in the financial domain, crime hotspot detection in the legal sector, and in the biomedical field, disease probability prediction when patient records are accessible. Since they have an impact on people's lives, these domains usually require decision-making systems to be explainable. Random Forest falls short on this property, especially when a large number of tree predictors are used. This issue was addressed in a recent research named LionForests, regarding single label classification and regression. In this work, we adapt this technique to multi-label classification problems, by employing three different strategies regarding the labels that the explanation covers. Finally, we provide a set of qualitative and quantitative experiments to assess the efficacy of this approach.