 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Task Text Classification Pipeline with Natural Language Explanations: A User-Centric Evaluation in Sentiment Analysis and Offensive Language Identification in Greek Tweets
Oct 14, 2024



Interpretability is a topic that has been in the spotlight for the past few years. Most existing interpretability techniques produce interpretations in the form of rules or feature importance. These interpretations, while informative, may be harder to understand for non-expert users and therefore, cannot always be considered as adequate explanations. To that end, explanations in natural language are often preferred, as they are easier to comprehend and also more presentable to end-users. This work introduces an early concept for a novel pipeline that can be used in text classification tasks, offering predictions and explanations in natural language. It comprises of two models: a classifier for labelling the text and an explanation generator which provides the explanation. The proposed pipeline can be adopted by any text classification task, given that ground truth rationales are available to train the explanation generator. Our experiments are centred around the tasks of sentiment analysis and offensive language identification in Greek tweets, using a Greek Large Language Model (LLM) to obtain the necessary explanations that can act as rationales. The experimental evaluation was performed through a user study based on three different metrics and achieved promising results for both datasets.
CoreLM: Coreference-aware Language Model Fine-Tuning
Nov 04, 2021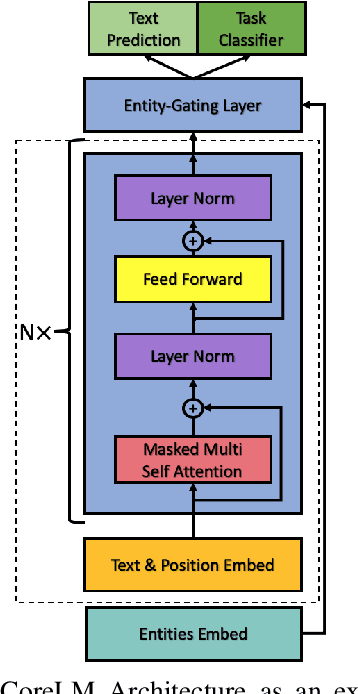
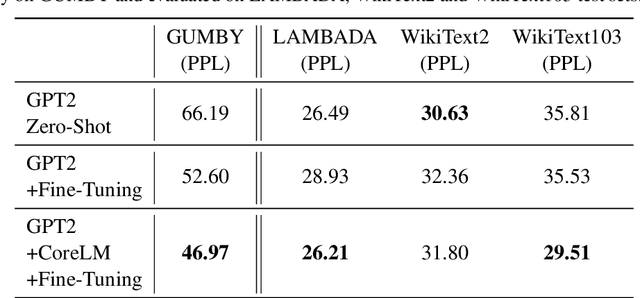
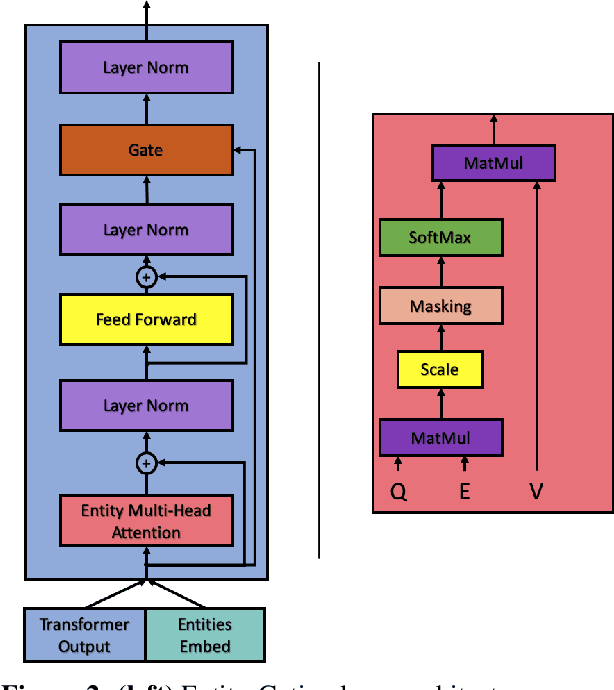
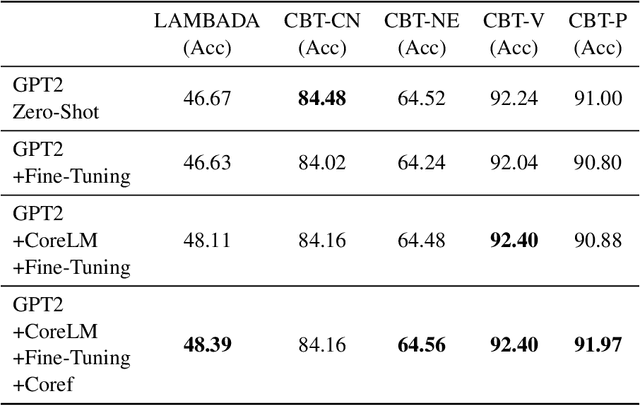
Language Models are the underpin of all modern Natural Language Processing (NLP) tasks. The introduction of the Transformers architecture has contributed significantly into making Language Modeling very effective across many NLP task, leading to significant advancements in the field. However, Transformers come with a big computational cost, which grows quadratically with respect to the input length. This presents a challenge as to understand long texts requires a lot of context. In this paper, we propose a Fine-Tuning framework, named CoreLM, that extends the architecture of current Pretrained Language Models so that they incorporate explicit entity information. By introducing entity representations, we make available information outside the contextual space of the model, which results in a better Language Model for a fraction of the computational cost. We implement our approach using GPT2 and compare the fine-tuned model to the original. Our proposed model achieves a lower Perplexity in GUMBY and LAMBDADA datasets when compared to GPT2 and a fine-tuned version of GPT2 without any changes. We also compare the models' performance in terms of Accuracy in LAMBADA and Children's Book Test, with and without the use of model-created coreference annotations.
E.T.: Entity-Transformers. Coreference augmented Neural Language Model for richer mention representations via Entity-Transformer blocks
Nov 10, 2020


In the last decade, the field of Neural Language Modelling has witnessed enormous changes, with the development of novel models through the use of Transformer architectures. However, even these models struggle to model long sequences due to memory constraints and increasing computational complexity. Coreference annotations over the training data can provide context far beyond the modelling limitations of such language models. In this paper we present an extension over the Transformer-block architecture used in neural language models, specifically in GPT2, in order to incorporate entity annotations during training. Our model, GPT2E, extends the Transformer layers architecture of GPT2 to Entity-Transformers, an architecture designed to handle coreference information when present. To that end, we achieve richer representations for entity mentions, with insignificant training cost. We show the comparative model performance between GPT2 and GPT2E in terms of Perplexity on the CoNLL 2012 and LAMBADA datasets as well as the key differences in the entity representations and their effects in downstream tasks such as Named Entity Recognition. Furthermore, our approach can be adopted by the majority of Transformer-based language models.
A Neural Entity Coreference Resolution Review
Oct 21, 2019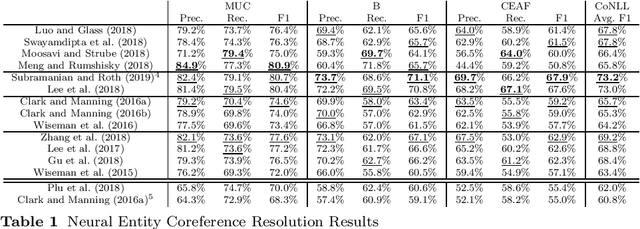
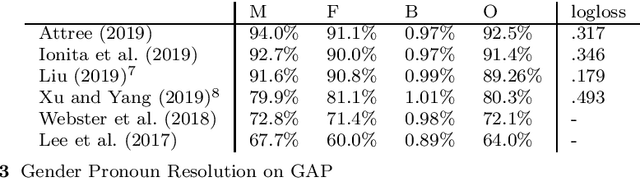
Entity Coreference Resolution is the task of resolving all the mentions in a document that refer to the same real world entity and is considered as one of the most difficult tasks in natural language understanding. While in it is not an end task, it has been proved to improve downstream natural language processing tasks such as entity linking, machine translation, summarization and chatbots. We conducted a systematic a review of neural-based approached and provide a detailed appraisal of the datasets and evaluation metrics in the field. Emphasis is given on Pronoun Resolution, a subtask of Coreference Resolution, which has seen various improvements in the recent years. We conclude the study by highlight the lack of agreed upon standards and propose a way to expand the task even further.