 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Task Text Classification Pipeline with Natural Language Explanations: A User-Centric Evaluation in Sentiment Analysis and Offensive Language Identification in Greek Tweets
Oct 14, 2024



Interpretability is a topic that has been in the spotlight for the past few years. Most existing interpretability techniques produce interpretations in the form of rules or feature importance. These interpretations, while informative, may be harder to understand for non-expert users and therefore, cannot always be considered as adequate explanations. To that end, explanations in natural language are often preferred, as they are easier to comprehend and also more presentable to end-users. This work introduces an early concept for a novel pipeline that can be used in text classification tasks, offering predictions and explanations in natural language. It comprises of two models: a classifier for labelling the text and an explanation generator which provides the explanation. The proposed pipeline can be adopted by any text classification task, given that ground truth rationales are available to train the explanation generator. Our experiments are centred around the tasks of sentiment analysis and offensive language identification in Greek tweets, using a Greek Large Language Model (LLM) to obtain the necessary explanations that can act as rationales. The experimental evaluation was performed through a user study based on three different metrics and achieved promising results for both datasets.
User Identity Linkage in Social Media Using Linguistic and Social Interaction Features
Aug 22, 2023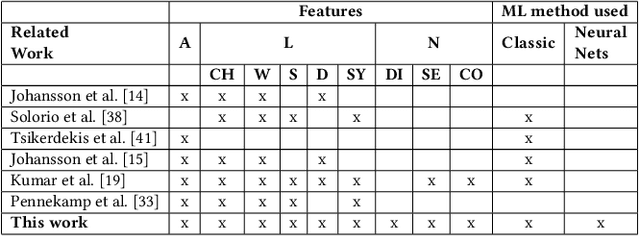
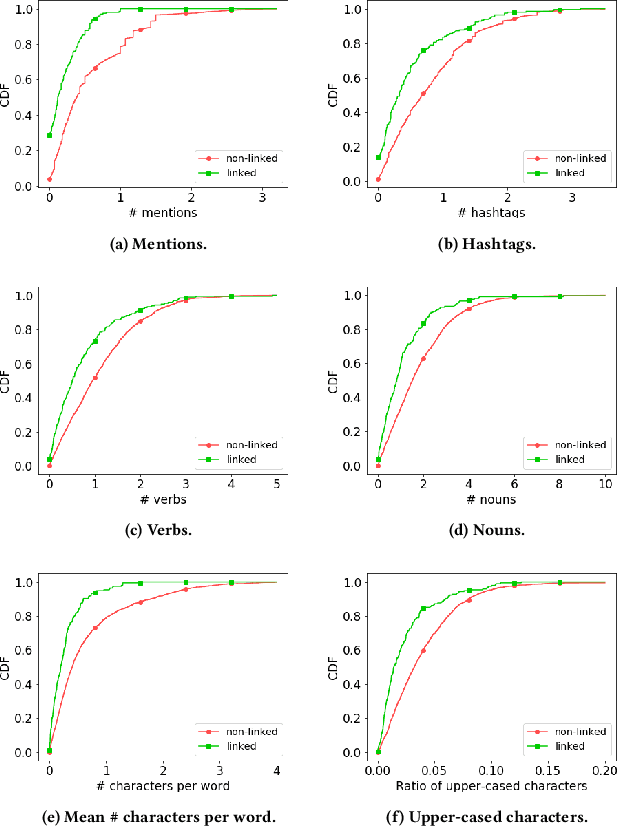
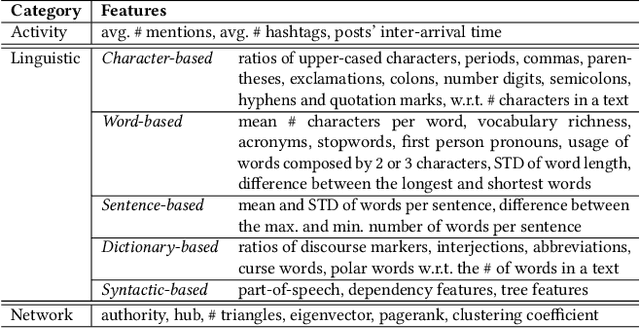
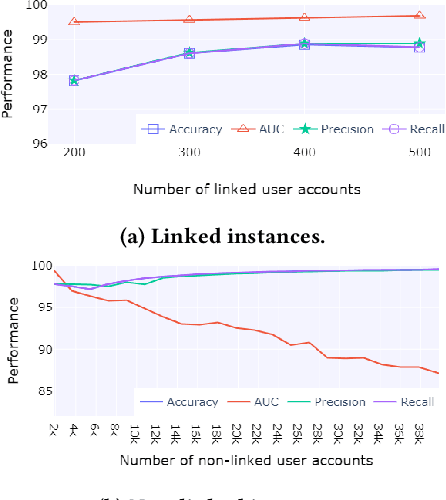
Social media users often hold several accounts in their effort to multiply the spread of their thoughts, ideas, and viewpoints. In the particular case of objectionable content, users tend to create multiple accounts to bypass the combating measures enforced by social media platforms and thus retain their online identity even if some of their accounts are suspended. User identity linkage aims to reveal social media accounts likely to belong to the same natural person so as to prevent the spread of abusive/illegal activities. To this end, this work proposes a machine learning-based detection model, which uses multiple attributes of users' online activity in order to identify whether two or more virtual identities belong to the same real natural person. The models efficacy is demonstrated on two cases on abusive and terrorism-related Twitter content.