 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Testing for Class-Conditional Noise Using Local Maximum Likelihood
Dec 15, 2023In supervised learning, automatically assessing the quality of the labels before any learning takes place remains an open research question. In certain particular cases, hypothesis testing procedures have been proposed to assess whether a given instance-label dataset is contaminated with class-conditional label noise, as opposed to uniform label noise. The existing theory builds on the asymptotic properties of the Maximum Likelihood Estimate for parametric logistic regression. However, the parametric assumptions on top of which these approaches are constructed are often too strong and unrealistic in practice. To alleviate this problem, in this paper we propose an alternative path by showing how similar procedures can be followed when the underlying model is a product of Local Maximum Likelihood Estimation that leads to more flexible nonparametric logistic regression models, which in turn are less susceptible to model misspecification. This different view allows for wider applicability of the tests by offering users access to a richer model class. Similarly to existing works, we assume we have access to anchor points which are provided by the users. We introduce the necessary ingredients for the adaptation of the hypothesis tests to the case of nonparametric logistic regression and empirically compare against the parametric approach presenting both synthetic and real-world case studies and discussing the advantages and limitations of the proposed approach.
Inherently Interpretable Time Series Classification via Multiple Instance Learning
Nov 23, 2023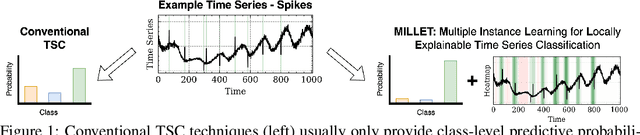

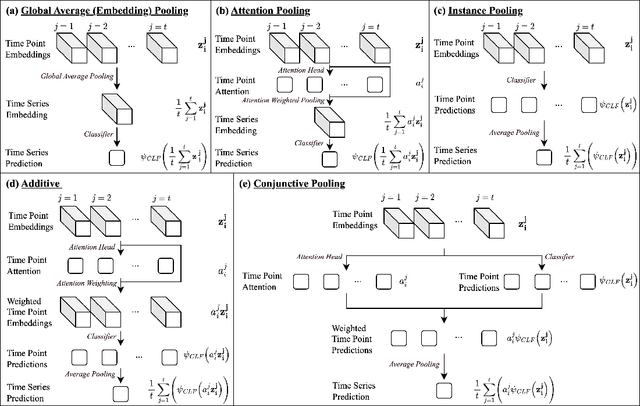
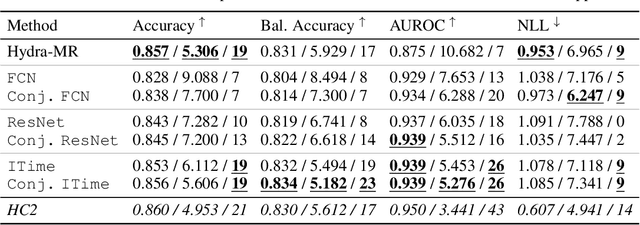
Conventional Time Series Classification (TSC) methods are often black boxes that obscure inherent interpretation of their decision-making processes. In this work, we leverage Multiple Instance Learning (MIL) to overcome this issue, and propose a new framework called MILLET: Multiple Instance Learning for Locally Explainable Time series classification. We apply MILLET to existing deep learning TSC models and show how they become inherently interpretable without compromising (and in some cases, even improving) predictive performance. We evaluate MILLET on 85 UCR TSC datasets and also present a novel synthetic dataset that is specially designed to facilitate interpretability evaluation. On these datasets, we show MILLET produces sparse explanations quickly that are of higher quality than other well-known interpretability methods. To the best of our knowledge, our work with MILLET, which is available on GitHub (https://github.com/JAEarly/MILTimeSeriesClassification), is the first to develop general MIL methods for TSC and apply them to an extensive variety of domains
Low-count Time Series Anomaly Detection
Aug 24, 2023



Low-count time series describe sparse or intermittent events, which are prevalent in large-scale online platforms that capture and monitor diverse data types. Several distinct challenges surface when modelling low-count time series, particularly low signal-to-noise ratios (when anomaly signatures are provably undetectable), and non-uniform performance (when average metrics are not representative of local behaviour). The time series anomaly detection community currently lacks explicit tooling and processes to model and reliably detect anomalies in these settings. We address this gap by introducing a novel generative procedure for creating benchmark datasets comprising of low-count time series with anomalous segments. Via a mixture of theoretical and empirical analysis, our work explains how widely-used algorithms struggle with the distribution overlap between normal and anomalous segments. In order to mitigate this shortcoming, we then leverage our findings to demonstrate how anomaly score smoothing consistently improves performance. The practical utility of our analysis and recommendation is validated on a real-world dataset containing sales data for retail stores.
Equitable Ability Estimation in Neurodivergent Student Populations with Zero-Inflated Learner Models
Mar 18, 2022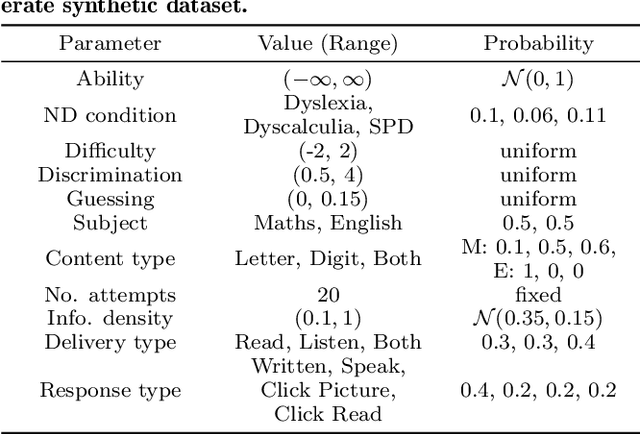
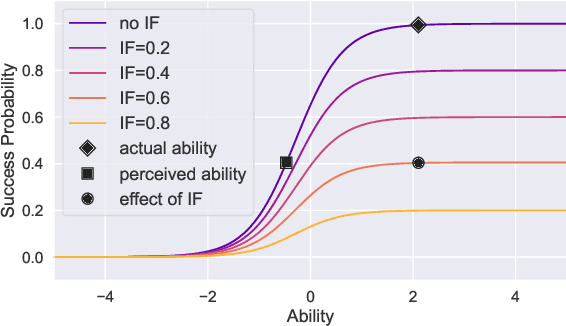
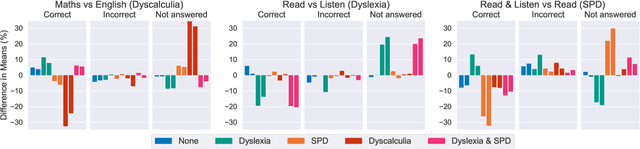
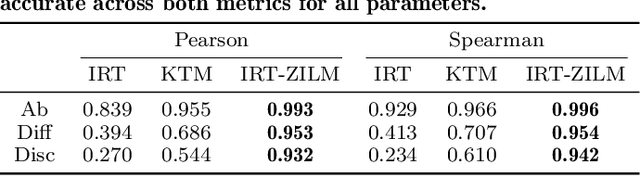
At present, the educational data mining community lacks many tools needed for ensuring equitable ability estimation for Neurodivergent (ND) learners. On one hand, most learner models are susceptible to under-estimating ND ability since confounding contexts cannot be held accountable (e.g. consider dyslexia and text-heavy assessments), and on the other, few (if any) existing datasets are suited for appraising model and data bias in ND contexts. In this paper we attempt to model the relationships between context (delivery and response types) and performance of ND students with zero-inflated learner models. This approach facilitates simulation of several expected ND behavioural traits, provides equitable ability estimates across all student groups from generated datasets, increases interpretability confidence, and can double the number of learning opportunities for ND students in some cases. Our approach consistently out-performs baselines in our experiments and can also be applied to many other learner modelling frameworks
Multi-Field Models in Neural Recipe Ranking -- An Early Exploratory Study
May 12, 2021


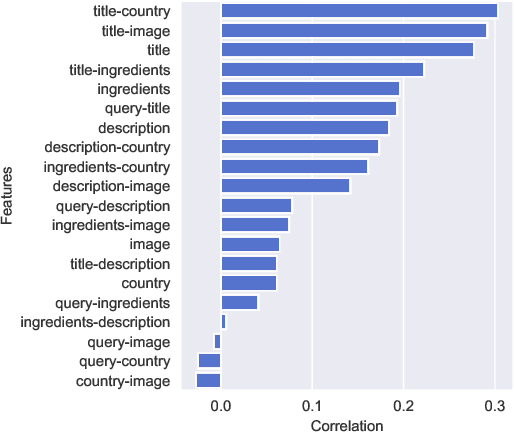
Explicitly modelling field interactions and correlations in complex documents structures has recently gained popularity in neural document embedding and retrieval tasks. Although this requires the specification of bespoke task-dependent models, encouraging empirical results are beginning to emerge. We present the first in-depth analyses of non-linear multi-field interaction (NL-MFI) ranking in the cooking domain in this work. Our results show that field-weighted factorisation machines models provide a statistically significant improvement over baselines in recipe retrieval tasks. Additionally, we show that sparsely capturing subsets of field interactions offers advantages over exhaustive alternatives. Although field-interaction aware models are more elaborate from an architectural basis, they are often more data-efficient in optimisation and are better suited for explainability due to mirrored document and model factorisation.
Backretrieval: An Image-Pivoted Evaluation Metric for Cross-Lingual Text Representations Without Parallel Corpora
May 11, 2021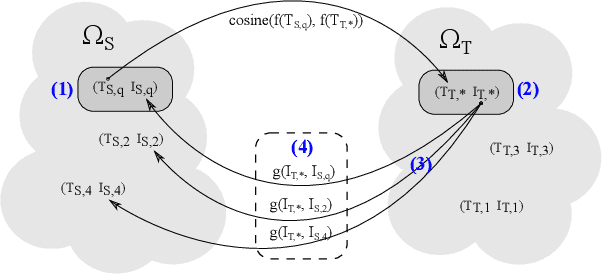
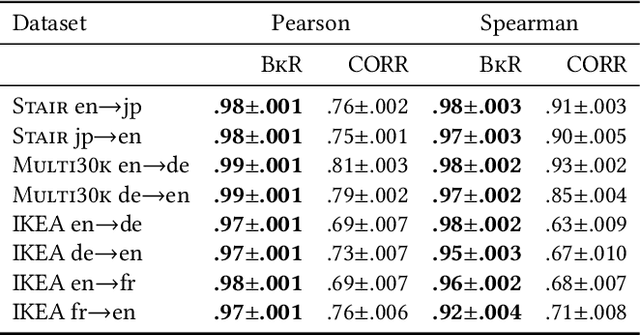
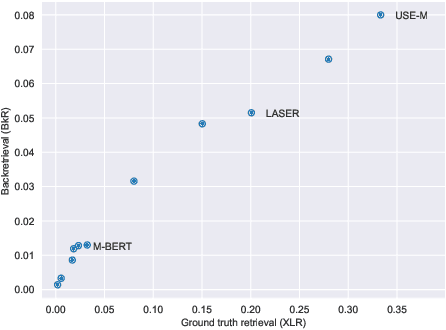

Cross-lingual text representations have gained popularity lately and act as the backbone of many tasks such as unsupervised machine translation and cross-lingual information retrieval, to name a few. However, evaluation of such representations is difficult in the domains beyond standard benchmarks due to the necessity of obtaining domain-specific parallel language data across different pairs of languages. In this paper, we propose an automatic metric for evaluating the quality of cross-lingual textual representations using images as a proxy in a paired image-text evaluation dataset. Experimentally, Backretrieval is shown to highly correlate with ground truth metrics on annotated datasets, and our analysis shows statistically significant improvements over baselines. Our experiments conclude with a case study on a recipe dataset without parallel cross-lingual data. We illustrate how to judge cross-lingual embedding quality with Backretrieval, and validate the outcome with a small human study.
Statistical Hypothesis Testing for Class-Conditional Label Noise
Mar 03, 2021
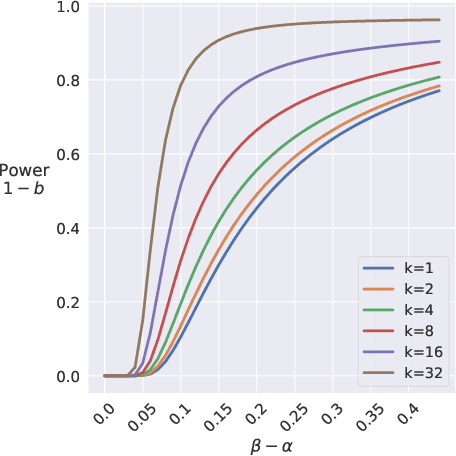
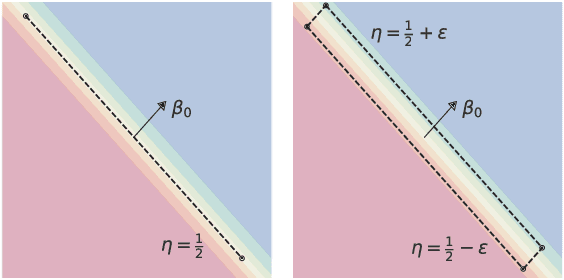
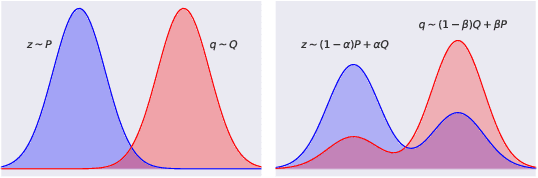
In this work we aim to provide machine learning practitioners with tools to answer the question: is there class-conditional flipping noise in my labels? In particular, we present hypothesis tests to reliably check whether a given dataset of instance-label pairs has been corrupted with class-conditional label noise. While previous works explore the direct estimation of the noise rates, this is known to be hard in practice and does not offer a real understanding of how trustworthy the estimates are. These methods typically require anchor points - examples whose true posterior is either 0 or 1. Differently, in this paper we assume we have access to a set of anchor points whose true posterior is approximately 1/2. The proposed hypothesis tests are built upon the asymptotic properties of Maximum Likelihood Estimators for Logistic Regression models and accurately distinguish the presence of class-conditional noise from uniform noise. We establish the main properties of the tests, including a theoretical and empirical analysis of the dependence of the power on the test on the training sample size, the number of anchor points, the difference of the noise rates and the use of realistic relaxed anchors.
Non-Linear Multiple Field Interactions Neural Document Ranking
Nov 18, 2020


Ranking tasks are usually based on the text of the main body of the page and the actions (clicks) of users on the page. There are other elements that could be leveraged to better contextualise the ranking experience (e.g. text in other fields, query made by the user, images, etc). We present one of the first in-depth analyses of field interaction for multiple field ranking in two separate datasets. While some works have taken advantage of full document structure, some aspects remain unexplored. In this work we build on previous analyses to show how query-field interactions, non-linear field interactions, and the architecture of the underlying neural model affect performance.
Detecting Signatures of Early-stage Dementia with Behavioural Models Derived from Sensor Data
Jul 03, 2020



There is a pressing need to automatically understand the state and progression of chronic neurological diseases such as dementia. The emergence of state-of-the-art sensing platforms offers unprecedented opportunities for indirect and automatic evaluation of disease state through the lens of behavioural monitoring. This paper specifically seeks to characterise behavioural signatures of mild cognitive impairment (MCI) and Alzheimer's disease (AD) in the \textit{early} stages of the disease. We introduce bespoke behavioural models and analyses of key symptoms and deploy these on a novel dataset of longitudinal sensor data from persons with MCI and AD. We present preliminary findings that show the relationship between levels of sleep quality and wandering can be subtly different between patients in the early stages of dementia and healthy cohabiting controls.
HyperStream: a Workflow Engine for Streaming Data
Aug 07, 2019
This paper describes HyperStream, a large-scale, flexible and robust software package, written in the Python language, for processing streaming data with workflow creation capabilities. HyperStream overcomes the limitations of other computational engines and provides high-level interfaces to execute complex nesting, fusion, and prediction both in online and offline forms in streaming environments. HyperStream is a general purpose tool that is well-suited for the design, development, and deployment of Machine Learning algorithms and predictive models in a wide space of sequential predictive problems. Source code, installation instructions, examples, and documentation can be found at: https://github.com/IRC-SPHERE/HyperStream.