 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInherently Interpretable Time Series Classification via Multiple Instance Learning
Nov 23, 2023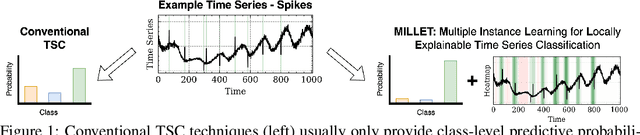

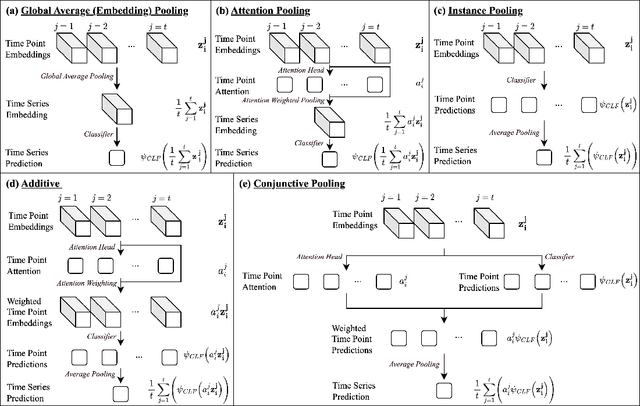
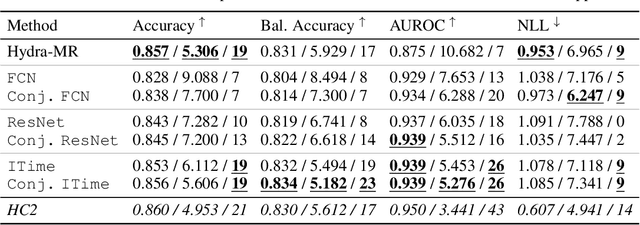
Conventional Time Series Classification (TSC) methods are often black boxes that obscure inherent interpretation of their decision-making processes. In this work, we leverage Multiple Instance Learning (MIL) to overcome this issue, and propose a new framework called MILLET: Multiple Instance Learning for Locally Explainable Time series classification. We apply MILLET to existing deep learning TSC models and show how they become inherently interpretable without compromising (and in some cases, even improving) predictive performance. We evaluate MILLET on 85 UCR TSC datasets and also present a novel synthetic dataset that is specially designed to facilitate interpretability evaluation. On these datasets, we show MILLET produces sparse explanations quickly that are of higher quality than other well-known interpretability methods. To the best of our knowledge, our work with MILLET, which is available on GitHub (https://github.com/JAEarly/MILTimeSeriesClassification), is the first to develop general MIL methods for TSC and apply them to an extensive variety of domains
Low-count Time Series Anomaly Detection
Aug 24, 2023



Low-count time series describe sparse or intermittent events, which are prevalent in large-scale online platforms that capture and monitor diverse data types. Several distinct challenges surface when modelling low-count time series, particularly low signal-to-noise ratios (when anomaly signatures are provably undetectable), and non-uniform performance (when average metrics are not representative of local behaviour). The time series anomaly detection community currently lacks explicit tooling and processes to model and reliably detect anomalies in these settings. We address this gap by introducing a novel generative procedure for creating benchmark datasets comprising of low-count time series with anomalous segments. Via a mixture of theoretical and empirical analysis, our work explains how widely-used algorithms struggle with the distribution overlap between normal and anomalous segments. In order to mitigate this shortcoming, we then leverage our findings to demonstrate how anomaly score smoothing consistently improves performance. The practical utility of our analysis and recommendation is validated on a real-world dataset containing sales data for retail stores.