 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackretrieval: An Image-Pivoted Evaluation Metric for Cross-Lingual Text Representations Without Parallel Corpora
May 11, 2021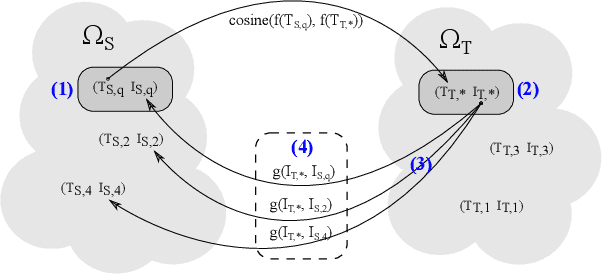
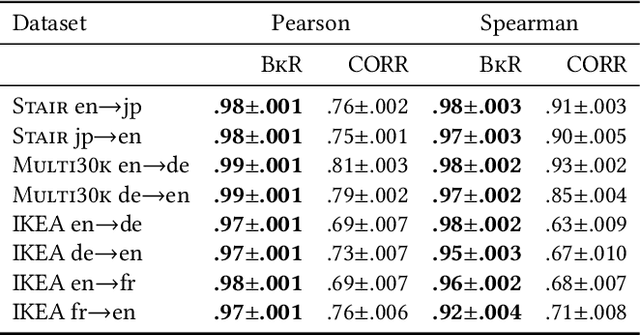
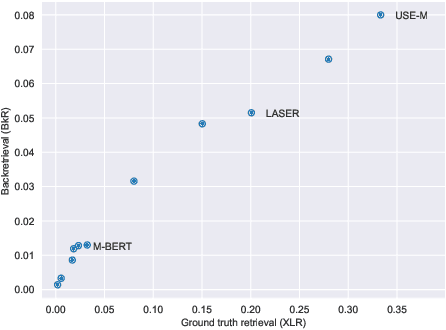

Cross-lingual text representations have gained popularity lately and act as the backbone of many tasks such as unsupervised machine translation and cross-lingual information retrieval, to name a few. However, evaluation of such representations is difficult in the domains beyond standard benchmarks due to the necessity of obtaining domain-specific parallel language data across different pairs of languages. In this paper, we propose an automatic metric for evaluating the quality of cross-lingual textual representations using images as a proxy in a paired image-text evaluation dataset. Experimentally, Backretrieval is shown to highly correlate with ground truth metrics on annotated datasets, and our analysis shows statistically significant improvements over baselines. Our experiments conclude with a case study on a recipe dataset without parallel cross-lingual data. We illustrate how to judge cross-lingual embedding quality with Backretrieval, and validate the outcome with a small human study.
Dividing and Conquering Cross-Modal Recipe Retrieval: from Nearest Neighbours Baselines to SoTA
Nov 28, 2019



We propose a novel non-parametric method for cross-modal retrieval which is applied on top of precomputed image and text embeddings. By combining our method with standard approaches for building image and text encoders, trained independently with a self-supervised classification objective, we create a baseline model which outperforms most existing methods on a challenging image-to-recipe task. We also use our method for comparing image and text encoders trained using different modern approaches, thus addressing the issues hindering the developments of novel methods for cross-modal recipe retrieval. We demonstrate how to use the insights from model comparison and extend our baseline model with standard triplet loss that improves SoTA on the Recipe1M dataset by a large margin, while using only precomputed features and with much less complexity than existing methods.