 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Testing for Class-Conditional Noise Using Local Maximum Likelihood
Dec 15, 2023In supervised learning, automatically assessing the quality of the labels before any learning takes place remains an open research question. In certain particular cases, hypothesis testing procedures have been proposed to assess whether a given instance-label dataset is contaminated with class-conditional label noise, as opposed to uniform label noise. The existing theory builds on the asymptotic properties of the Maximum Likelihood Estimate for parametric logistic regression. However, the parametric assumptions on top of which these approaches are constructed are often too strong and unrealistic in practice. To alleviate this problem, in this paper we propose an alternative path by showing how similar procedures can be followed when the underlying model is a product of Local Maximum Likelihood Estimation that leads to more flexible nonparametric logistic regression models, which in turn are less susceptible to model misspecification. This different view allows for wider applicability of the tests by offering users access to a richer model class. Similarly to existing works, we assume we have access to anchor points which are provided by the users. We introduce the necessary ingredients for the adaptation of the hypothesis tests to the case of nonparametric logistic regression and empirically compare against the parametric approach presenting both synthetic and real-world case studies and discussing the advantages and limitations of the proposed approach.
When the Ground Truth is not True: Modelling Human Biases in Temporal Annotations
Feb 06, 2023



In supervised learning, low quality annotations lead to poorly performing classification and detection models, while also rendering evaluation unreliable. This is particularly apparent on temporal data, where annotation quality is affected by multiple factors. For example, in the post-hoc self-reporting of daily activities, cognitive biases are one of the most common ingredients. In particular, reporting the start and duration of an activity after its finalisation may incorporate biases introduced by personal time perceptions, as well as the imprecision and lack of granularity due to time rounding. Here we propose a method to model human biases on temporal annotations and argue for the use of soft labels. Experimental results in synthetic data show that soft labels provide a better approximation of the ground truth for several metrics. We showcase the method on a real dataset of daily activities.
Statistical Hypothesis Testing for Class-Conditional Label Noise
Mar 03, 2021
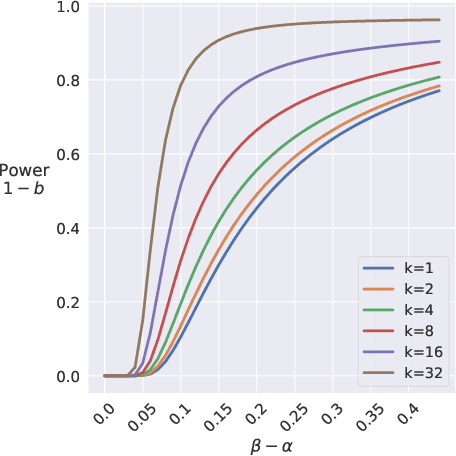
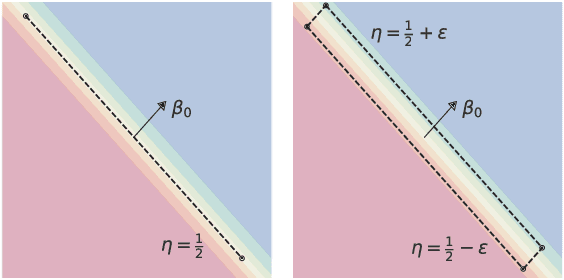
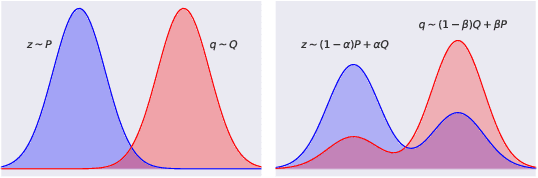
In this work we aim to provide machine learning practitioners with tools to answer the question: is there class-conditional flipping noise in my labels? In particular, we present hypothesis tests to reliably check whether a given dataset of instance-label pairs has been corrupted with class-conditional label noise. While previous works explore the direct estimation of the noise rates, this is known to be hard in practice and does not offer a real understanding of how trustworthy the estimates are. These methods typically require anchor points - examples whose true posterior is either 0 or 1. Differently, in this paper we assume we have access to a set of anchor points whose true posterior is approximately 1/2. The proposed hypothesis tests are built upon the asymptotic properties of Maximum Likelihood Estimators for Logistic Regression models and accurately distinguish the presence of class-conditional noise from uniform noise. We establish the main properties of the tests, including a theoretical and empirical analysis of the dependence of the power on the test on the training sample size, the number of anchor points, the difference of the noise rates and the use of realistic relaxed anchors.
Detecting Signatures of Early-stage Dementia with Behavioural Models Derived from Sensor Data
Jul 03, 2020



There is a pressing need to automatically understand the state and progression of chronic neurological diseases such as dementia. The emergence of state-of-the-art sensing platforms offers unprecedented opportunities for indirect and automatic evaluation of disease state through the lens of behavioural monitoring. This paper specifically seeks to characterise behavioural signatures of mild cognitive impairment (MCI) and Alzheimer's disease (AD) in the \textit{early} stages of the disease. We introduce bespoke behavioural models and analyses of key symptoms and deploy these on a novel dataset of longitudinal sensor data from persons with MCI and AD. We present preliminary findings that show the relationship between levels of sleep quality and wandering can be subtly different between patients in the early stages of dementia and healthy cohabiting controls.