 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAmBLA: A Framework for Evaluating the Reliability of LLMs as Assistants in the Biomedical Domain
Mar 21, 2024



Large Language Models (LLMs) increasingly support applications in a wide range of domains, some with potential high societal impact such as biomedicine, yet their reliability in realistic use cases is under-researched. In this work we introduce the Reliability AssesMent for Biomedical LLM Assistants (RAmBLA) framework and evaluate whether four state-of-the-art foundation LLMs can serve as reliable assistants in the biomedical domain. We identify prompt robustness, high recall, and a lack of hallucinations as necessary criteria for this use case. We design shortform tasks and tasks requiring LLM freeform responses mimicking real-world user interactions. We evaluate LLM performance using semantic similarity with a ground truth response, through an evaluator LLM.
Hypothesis Testing for Class-Conditional Noise Using Local Maximum Likelihood
Dec 15, 2023In supervised learning, automatically assessing the quality of the labels before any learning takes place remains an open research question. In certain particular cases, hypothesis testing procedures have been proposed to assess whether a given instance-label dataset is contaminated with class-conditional label noise, as opposed to uniform label noise. The existing theory builds on the asymptotic properties of the Maximum Likelihood Estimate for parametric logistic regression. However, the parametric assumptions on top of which these approaches are constructed are often too strong and unrealistic in practice. To alleviate this problem, in this paper we propose an alternative path by showing how similar procedures can be followed when the underlying model is a product of Local Maximum Likelihood Estimation that leads to more flexible nonparametric logistic regression models, which in turn are less susceptible to model misspecification. This different view allows for wider applicability of the tests by offering users access to a richer model class. Similarly to existing works, we assume we have access to anchor points which are provided by the users. We introduce the necessary ingredients for the adaptation of the hypothesis tests to the case of nonparametric logistic regression and empirically compare against the parametric approach presenting both synthetic and real-world case studies and discussing the advantages and limitations of the proposed approach.
FAT Forensics: A Python Toolbox for Implementing and Deploying Fairness, Accountability and Transparency Algorithms in Predictive Systems
Sep 08, 2022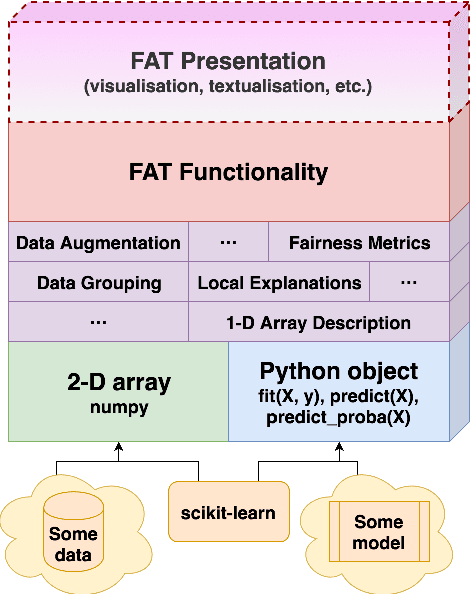
Predictive systems, in particular machine learning algorithms, can take important, and sometimes legally binding, decisions about our everyday life. In most cases, however, these systems and decisions are neither regulated nor certified. Given the potential harm that these algorithms can cause, their qualities such as fairness, accountability and transparency (FAT) are of paramount importance. To ensure high-quality, fair, transparent and reliable predictive systems, we developed an open source Python package called FAT Forensics. It can inspect important fairness, accountability and transparency aspects of predictive algorithms to automatically and objectively report them back to engineers and users of such systems. Our toolbox can evaluate all elements of a predictive pipeline: data (and their features), models and predictions. Published under the BSD 3-Clause open source licence, FAT Forensics is opened up for personal and commercial usage.
The Weak Supervision Landscape
Mar 30, 2022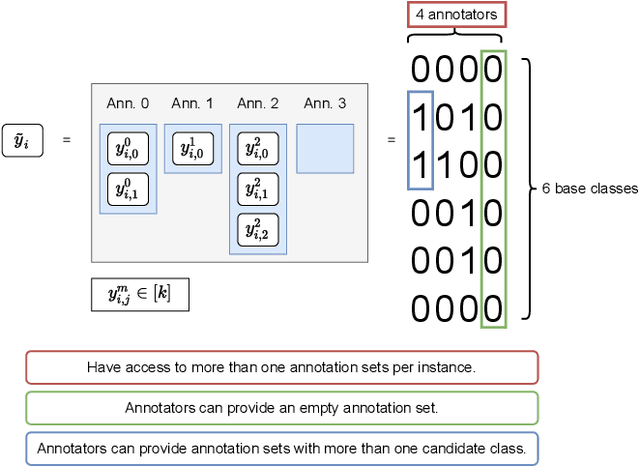
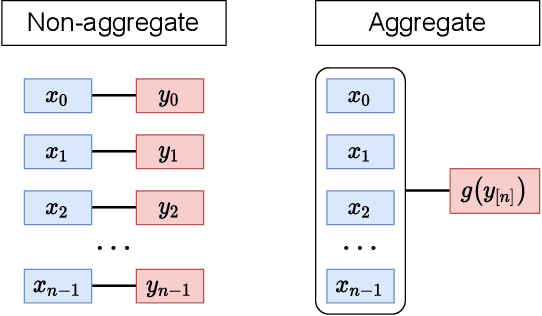
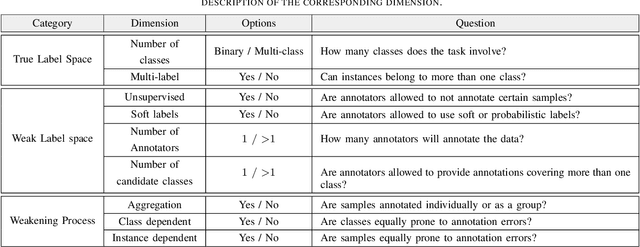
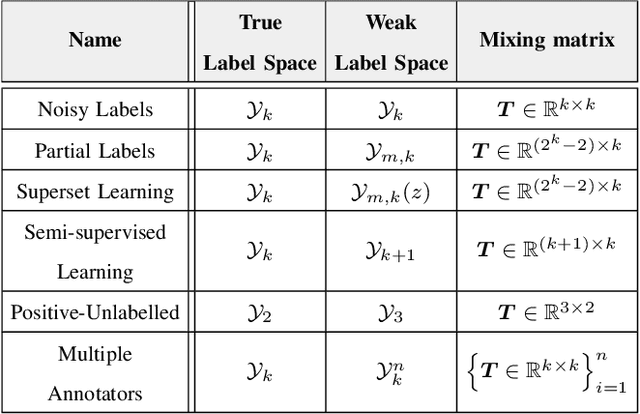
Many ways of annotating a dataset for machine learning classification tasks that go beyond the usual class labels exist in practice. These are of interest as they can simplify or facilitate the collection of annotations, while not greatly affecting the resulting machine learning model. Many of these fall under the umbrella term of weak labels or annotations. However, it is not always clear how different alternatives are related. In this paper we propose a framework for categorising weak supervision settings with the aim of: (1) helping the dataset owner or annotator navigate through the available options within weak supervision when prescribing an annotation process, and (2) describing existing annotations for a dataset to machine learning practitioners so that we allow them to understand the implications for the learning process. To this end, we identify the key elements that characterise weak supervision and devise a series of dimensions that categorise most of the existing approaches. We show how common settings in the literature fit within the framework and discuss its possible uses in practice.
Equitable Ability Estimation in Neurodivergent Student Populations with Zero-Inflated Learner Models
Mar 18, 2022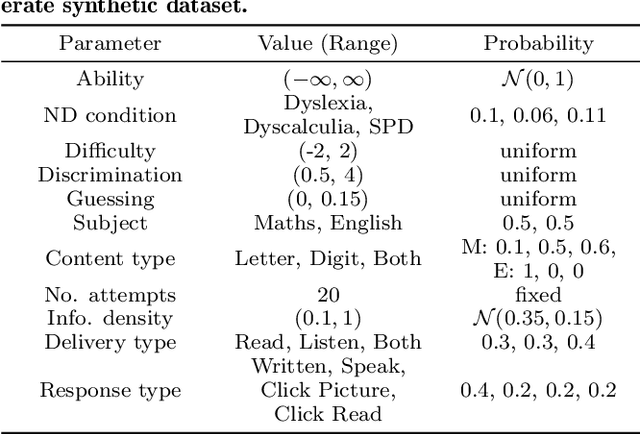
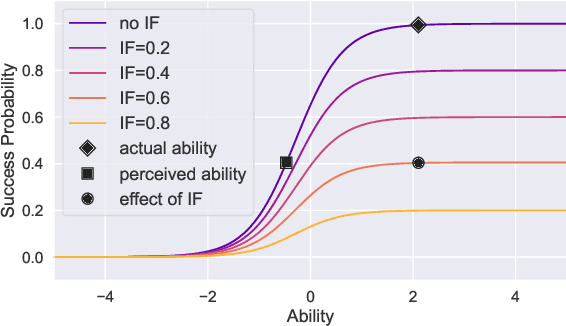
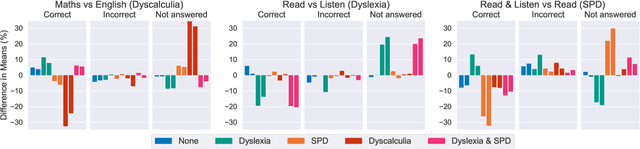
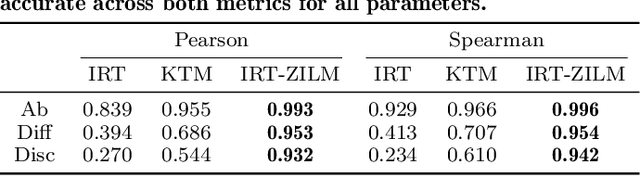
At present, the educational data mining community lacks many tools needed for ensuring equitable ability estimation for Neurodivergent (ND) learners. On one hand, most learner models are susceptible to under-estimating ND ability since confounding contexts cannot be held accountable (e.g. consider dyslexia and text-heavy assessments), and on the other, few (if any) existing datasets are suited for appraising model and data bias in ND contexts. In this paper we attempt to model the relationships between context (delivery and response types) and performance of ND students with zero-inflated learner models. This approach facilitates simulation of several expected ND behavioural traits, provides equitable ability estimates across all student groups from generated datasets, increases interpretability confidence, and can double the number of learning opportunities for ND students in some cases. Our approach consistently out-performs baselines in our experiments and can also be applied to many other learner modelling frameworks
Uncertainty Quantification of Surrogate Explanations: an Ordinal Consensus Approach
Nov 17, 2021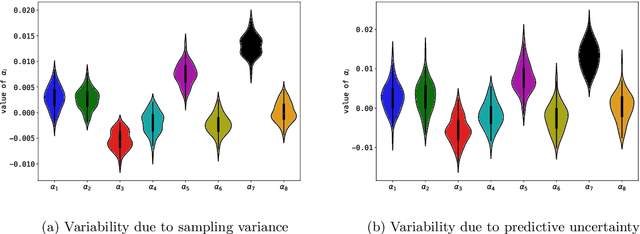
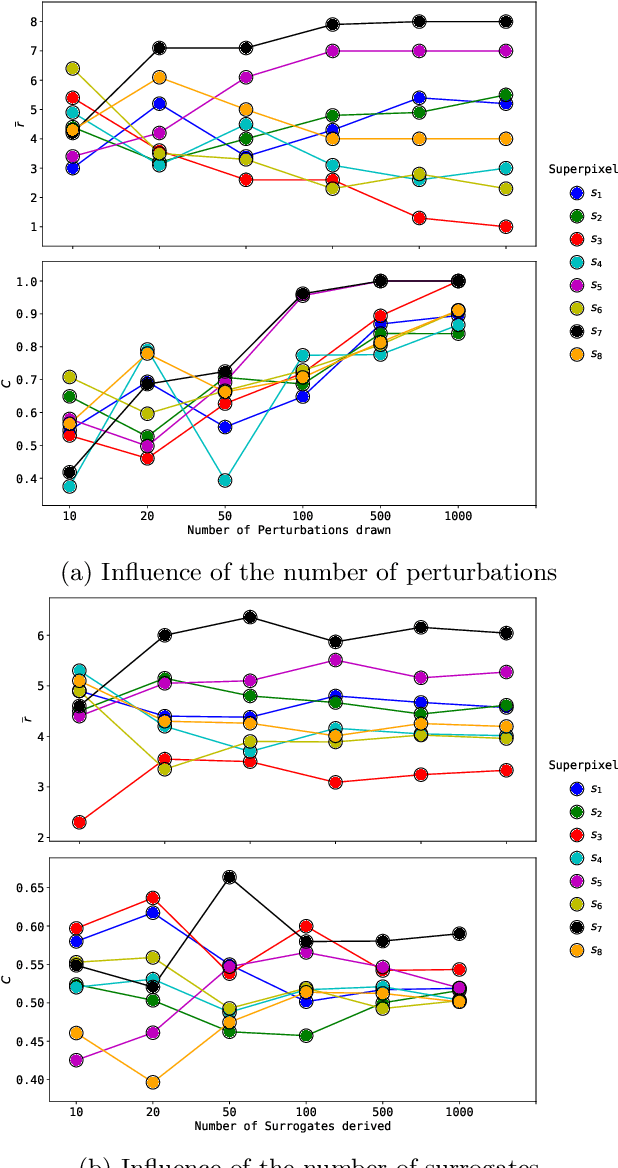
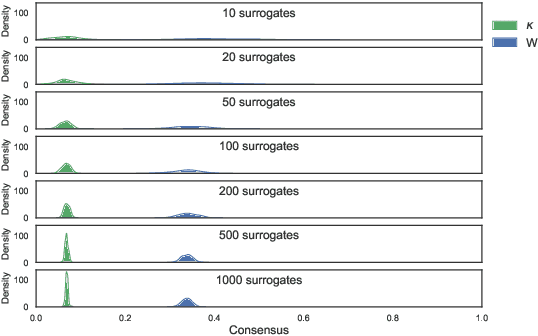
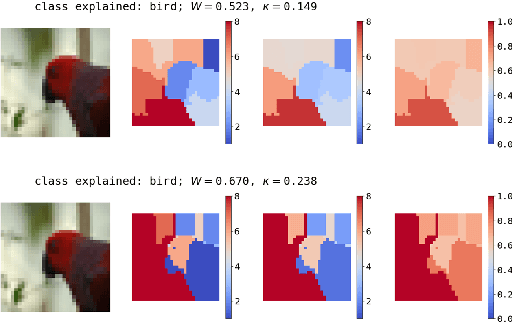
Explainability of black-box machine learning models is crucial, in particular when deployed in critical applications such as medicine or autonomous cars. Existing approaches produce explanations for the predictions of models, however, how to assess the quality and reliability of such explanations remains an open question. In this paper we take a step further in order to provide the practitioner with tools to judge the trustworthiness of an explanation. To this end, we produce estimates of the uncertainty of a given explanation by measuring the ordinal consensus amongst a set of diverse bootstrapped surrogate explainers. While we encourage diversity by using ensemble techniques, we propose and analyse metrics to aggregate the information contained within the set of explainers through a rating scheme. We empirically illustrate the properties of this approach through experiments on state-of-the-art Convolutional Neural Network ensembles. Furthermore, through tailored visualisations, we show specific examples of situations where uncertainty estimates offer concrete actionable insights to the user beyond those arising from standard surrogate explainers.
Domain Generalisation for Apparent Emotional Facial Expression Recognition across Age-Groups
Oct 18, 2021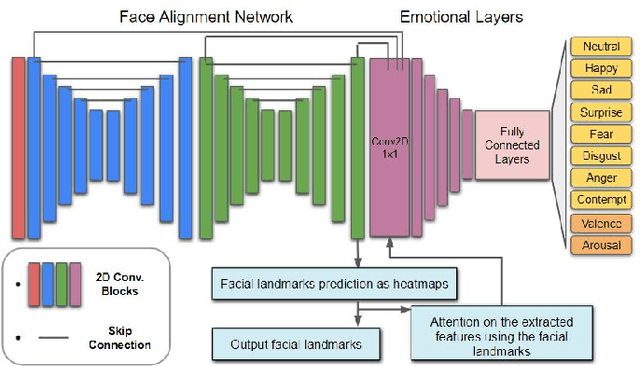
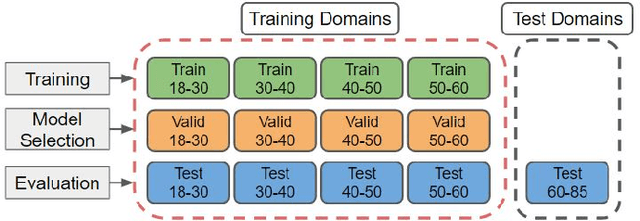
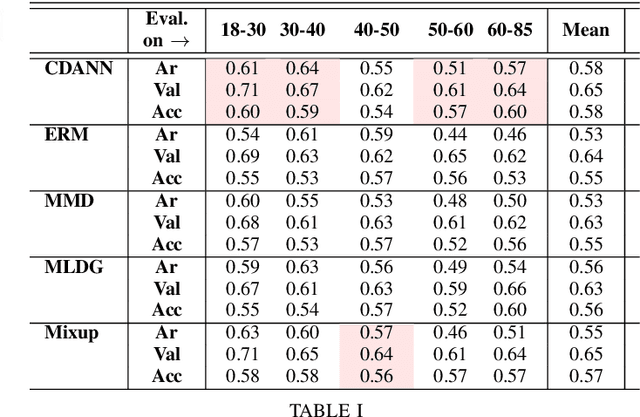
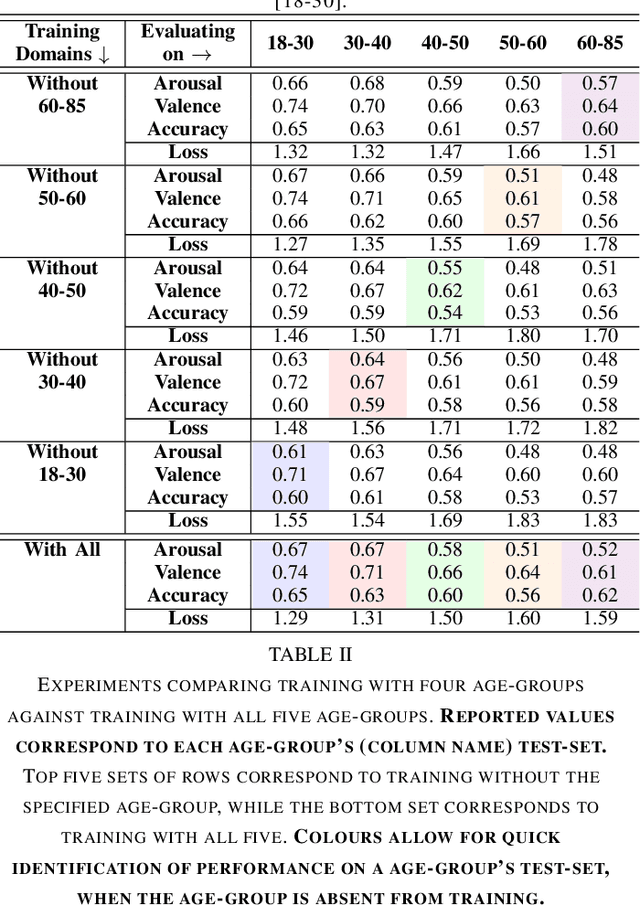
Apparent emotional facial expression recognition has attracted a lot of research attention recently. However, the majority of approaches ignore age differences and train a generic model for all ages. In this work, we study the effect of using different age-groups for training apparent emotional facial expression recognition models. To this end, we study Domain Generalisation in the context of apparent emotional facial expression recognition from facial imagery across different age groups. We first compare several domain generalisation algorithms on the basis of out-of-domain-generalisation, and observe that the Class-Conditional Domain-Adversarial Neural Networks (CDANN) algorithm has the best performance. We then study the effect of variety and number of age-groups used during training on generalisation to unseen age-groups and observe that an increase in the number of training age-groups tends to increase the apparent emotional facial expression recognition performance on unseen age-groups. We also show that exclusion of an age-group during training tends to affect more the performance of the neighbouring age groups.
Understanding surrogate explanations: the interplay between complexity, fidelity and coverage
Jul 09, 2021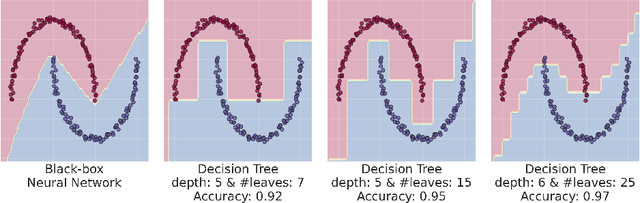
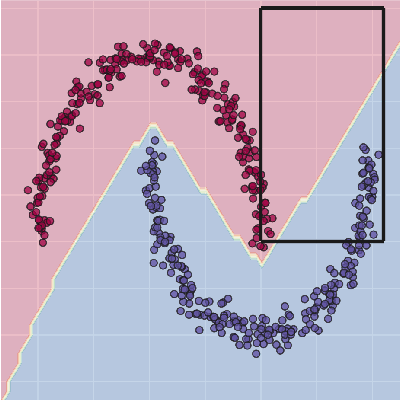
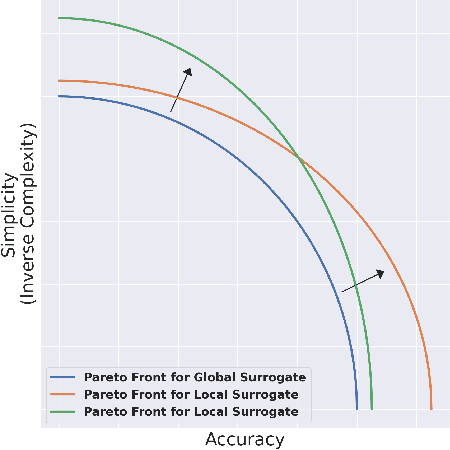
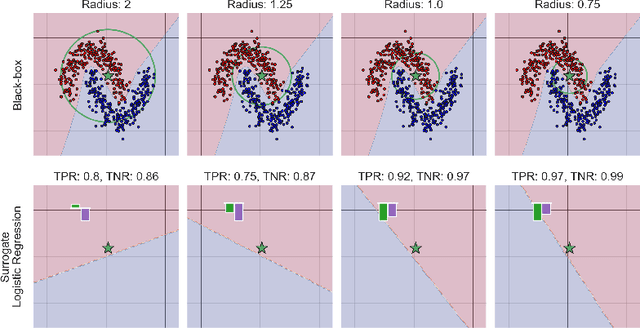
This paper analyses the fundamental ingredients behind surrogate explanations to provide a better understanding of their inner workings. We start our exposition by considering global surrogates, describing the trade-off between complexity of the surrogate and fidelity to the black-box being modelled. We show that transitioning from global to local - reducing coverage - allows for more favourable conditions on the Pareto frontier of fidelity-complexity of a surrogate. We discuss the interplay between complexity, fidelity and coverage, and consider how different user needs can lead to problem formulations where these are either constraints or penalties. We also present experiments that demonstrate how the local surrogate interpretability procedure can be made interactive and lead to better explanations.
On the overlooked issue of defining explanation objectives for local-surrogate explainers
Jun 10, 2021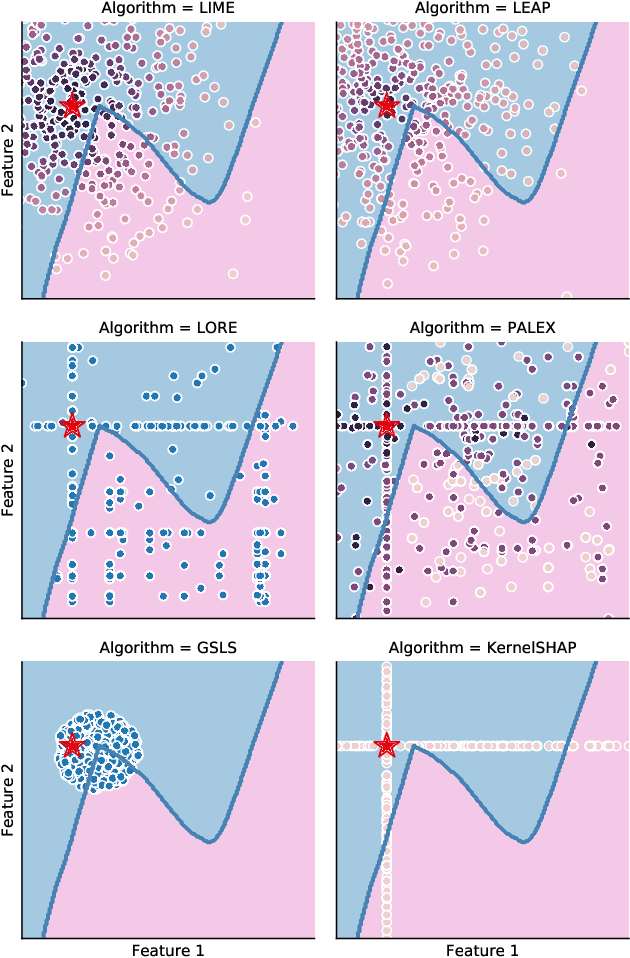

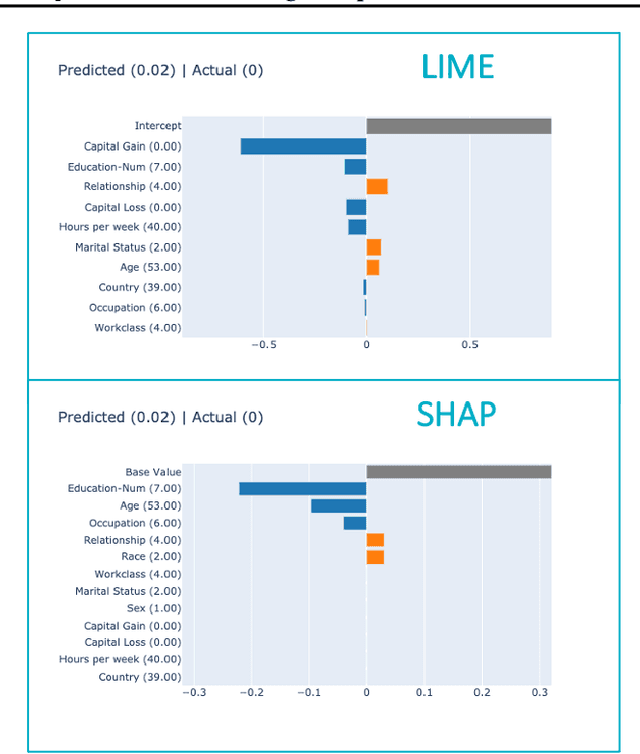
Local surrogate approaches for explaining machine learning model predictions have appealing properties, such as being model-agnostic and flexible in their modelling. Several methods exist that fit this description and share this goal. However, despite their shared overall procedure, they set out different objectives, extract different information from the black-box, and consequently produce diverse explanations, that are -- in general -- incomparable. In this work we review the similarities and differences amongst multiple methods, with a particular focus on what information they extract from the model, as this has large impact on the output: the explanation. We discuss the implications of the lack of agreement, and clarity, amongst the methods' objectives on the research and practice of explainability.
Statistical Hypothesis Testing for Class-Conditional Label Noise
Mar 03, 2021
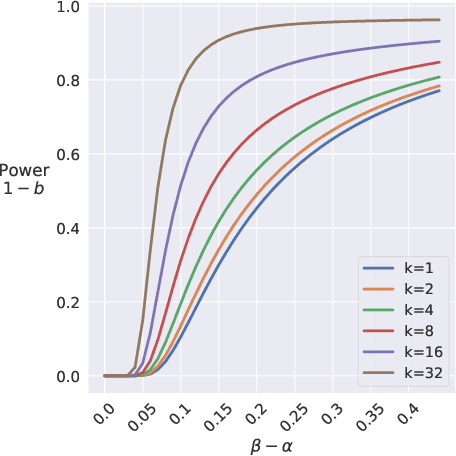
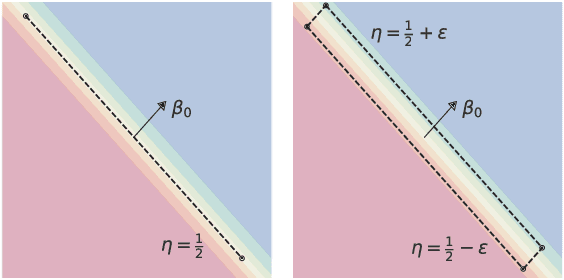
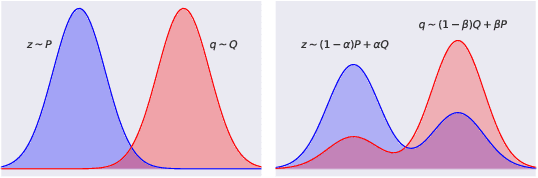
In this work we aim to provide machine learning practitioners with tools to answer the question: is there class-conditional flipping noise in my labels? In particular, we present hypothesis tests to reliably check whether a given dataset of instance-label pairs has been corrupted with class-conditional label noise. While previous works explore the direct estimation of the noise rates, this is known to be hard in practice and does not offer a real understanding of how trustworthy the estimates are. These methods typically require anchor points - examples whose true posterior is either 0 or 1. Differently, in this paper we assume we have access to a set of anchor points whose true posterior is approximately 1/2. The proposed hypothesis tests are built upon the asymptotic properties of Maximum Likelihood Estimators for Logistic Regression models and accurately distinguish the presence of class-conditional noise from uniform noise. We establish the main properties of the tests, including a theoretical and empirical analysis of the dependence of the power on the test on the training sample size, the number of anchor points, the difference of the noise rates and the use of realistic relaxed anchors.