 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification of Surrogate Explanations: an Ordinal Consensus Approach
Paper and Code
Nov 17, 2021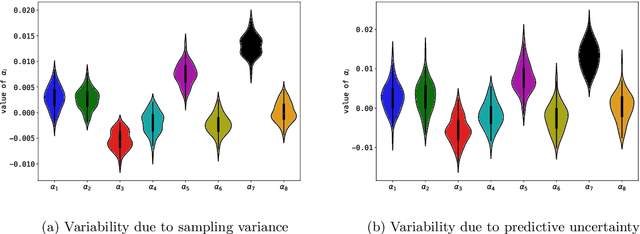
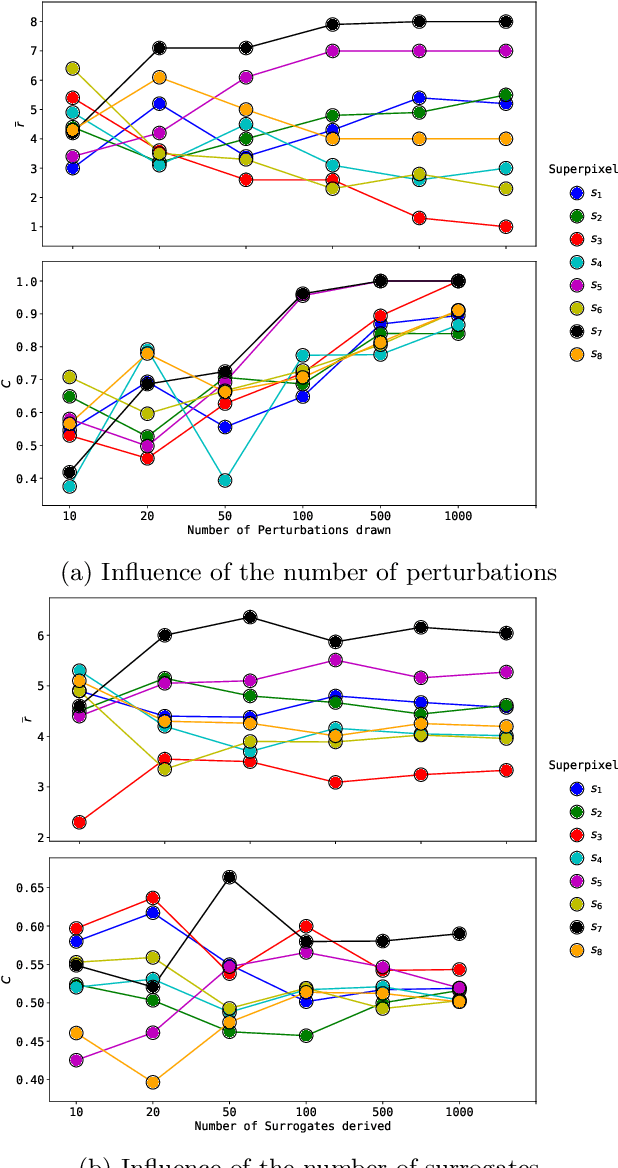
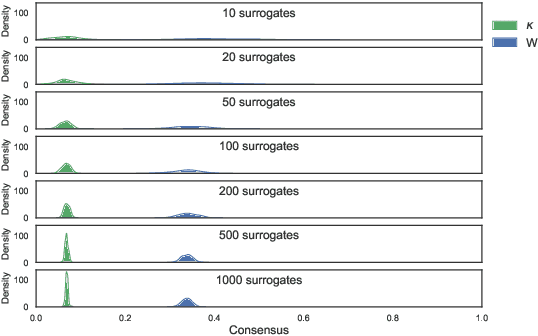
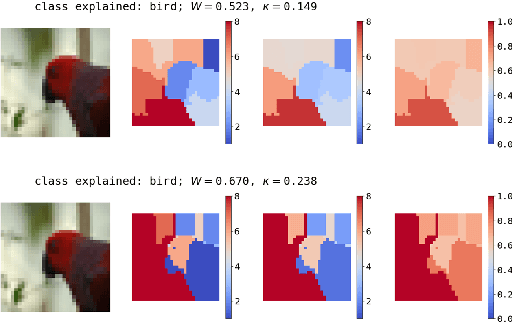
Explainability of black-box machine learning models is crucial, in particular when deployed in critical applications such as medicine or autonomous cars. Existing approaches produce explanations for the predictions of models, however, how to assess the quality and reliability of such explanations remains an open question. In this paper we take a step further in order to provide the practitioner with tools to judge the trustworthiness of an explanation. To this end, we produce estimates of the uncertainty of a given explanation by measuring the ordinal consensus amongst a set of diverse bootstrapped surrogate explainers. While we encourage diversity by using ensemble techniques, we propose and analyse metrics to aggregate the information contained within the set of explainers through a rating scheme. We empirically illustrate the properties of this approach through experiments on state-of-the-art Convolutional Neural Network ensembles. Furthermore, through tailored visualisations, we show specific examples of situations where uncertainty estimates offer concrete actionable insights to the user beyond those arising from standard surrogate explainers.