 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Query Selection for Crowd-Based Reinforcement Learning
Aug 26, 2025Preference-based reinforcement learning has gained prominence as a strategy for training agents in environments where the reward signal is difficult to specify or misaligned with human intent. However, its effectiveness is often limited by the high cost and low availability of reliable human input, especially in domains where expert feedback is scarce or errors are costly. To address this, we propose a novel framework that combines two complementary strategies: probabilistic crowd modelling to handle noisy, multi-annotator feedback, and active learning to prioritize feedback on the most informative agent actions. We extend the Advise algorithm to support multiple trainers, estimate their reliability online, and incorporate entropy-based query selection to guide feedback requests. We evaluate our approach in a set of environments that span both synthetic and real-world-inspired settings, including 2D games (Taxi, Pacman, Frozen Lake) and a blood glucose control task for Type 1 Diabetes using the clinically approved UVA/Padova simulator. Our preliminary results demonstrate that agents trained with feedback on uncertain trajectories exhibit faster learning in most tasks, and we outperform the baselines for the blood glucose control task.
Safe and Robust Reinforcement Learning: Principles and Practice
Mar 30, 2024Reinforcement Learning (RL) has shown remarkable success in solving relatively complex tasks, yet the deployment of RL systems in real-world scenarios poses significant challenges related to safety and robustness. This paper aims to identify and further understand those challenges thorough the exploration of the main dimensions of the safe and robust RL landscape, encompassing algorithmic, ethical, and practical considerations. We conduct a comprehensive review of methodologies and open problems that summarizes the efforts in recent years to address the inherent risks associated with RL applications. After discussing and proposing definitions for both safe and robust RL, the paper categorizes existing research works into different algorithmic approaches that enhance the safety and robustness of RL agents. We examine techniques such as uncertainty estimation, optimisation methodologies, exploration-exploitation trade-offs, and adversarial training. Environmental factors, including sim-to-real transfer and domain adaptation, are also scrutinized to understand how RL systems can adapt to diverse and dynamic surroundings. Moreover, human involvement is an integral ingredient of the analysis, acknowledging the broad set of roles that humans can take in this context. Importantly, to aid practitioners in navigating the complexities of safe and robust RL implementation, this paper introduces a practical checklist derived from the synthesized literature. The checklist encompasses critical aspects of algorithm design, training environment considerations, and ethical guidelines. It will serve as a resource for developers and policymakers alike to ensure the responsible deployment of RL systems in many application domains.
When the Ground Truth is not True: Modelling Human Biases in Temporal Annotations
Feb 06, 2023



In supervised learning, low quality annotations lead to poorly performing classification and detection models, while also rendering evaluation unreliable. This is particularly apparent on temporal data, where annotation quality is affected by multiple factors. For example, in the post-hoc self-reporting of daily activities, cognitive biases are one of the most common ingredients. In particular, reporting the start and duration of an activity after its finalisation may incorporate biases introduced by personal time perceptions, as well as the imprecision and lack of granularity due to time rounding. Here we propose a method to model human biases on temporal annotations and argue for the use of soft labels. Experimental results in synthetic data show that soft labels provide a better approximation of the ground truth for several metrics. We showcase the method on a real dataset of daily activities.
Q-learning Decision Transformer: Leveraging Dynamic Programming for Conditional Sequence Modelling in Offline RL
Sep 08, 2022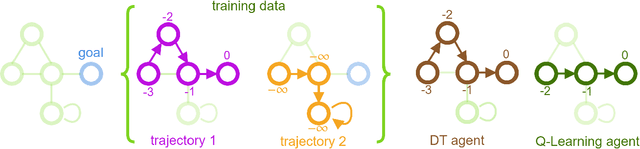
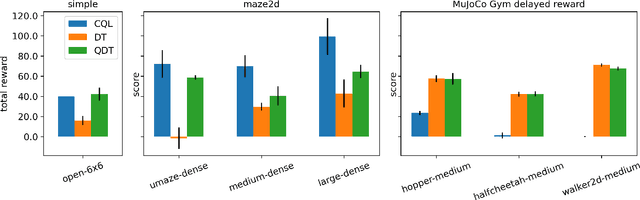
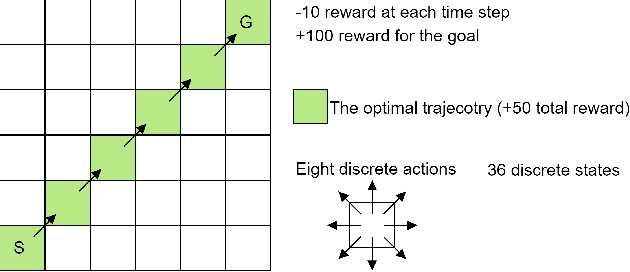

Recent works have shown that tackling offline reinforcement learning (RL) with a conditional policy produces promising results by converting the RL task to a supervised learning task. Decision Transformer (DT) combines the conditional policy approach and Transformer architecture to show competitive performance against several benchmarks. However, DT lacks stitching ability -- one of the critical abilities for offline RL that learns the optimal policy from sub-optimal trajectories. The issue becomes significant when the offline dataset only contains sub-optimal trajectories. On the other hand, the conventional RL approaches based on Dynamic Programming (such as Q-learning) do not suffer the same issue; however, they suffer from unstable learning behaviours, especially when it employs function approximation in an off-policy learning setting. In this paper, we propose Q-learning Decision Transformer (QDT) that addresses the shortcomings of DT by leveraging the benefit of Dynamic Programming (Q-learning). QDT utilises the Dynamic Programming (Q-learning) results to relabel the return-to-go in the training data. We then train the DT with the relabelled data. Our approach efficiently exploits the benefits of these two approaches and compensates for each other's shortcomings to achieve better performance. We demonstrate the issue of DT and the advantage of QDT in a simple environment. We also evaluate QDT in the more complex D4RL benchmark showing good performance gains.
Reinforcement Learning with Feedback from Multiple Humans with Diverse Skills
Nov 16, 2021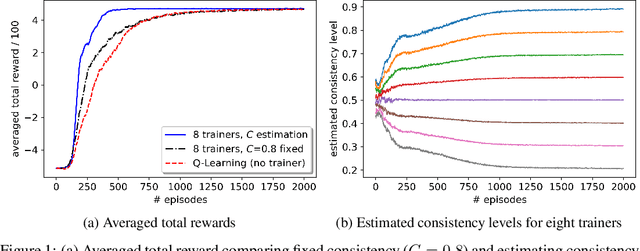
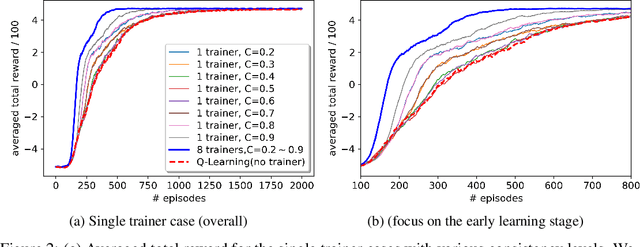
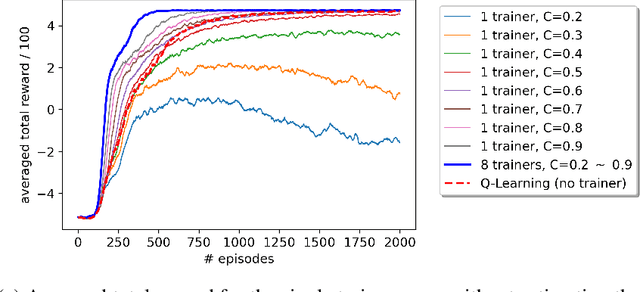
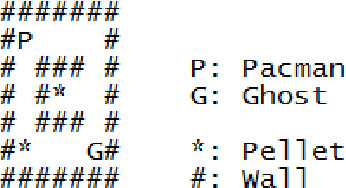
A promising approach to improve the robustness and exploration in Reinforcement Learning is collecting human feedback and that way incorporating prior knowledge of the target environment. It is, however, often too expensive to obtain enough feedback of good quality. To mitigate the issue, we aim to rely on a group of multiple experts (and non-experts) with different skill levels to generate enough feedback. Such feedback can therefore be inconsistent and infrequent. In this paper, we build upon prior work -- Advise, a Bayesian approach attempting to maximise the information gained from human feedback -- extending the algorithm to accept feedback from this larger group of humans, the trainers, while also estimating each trainer's reliability. We show how aggregating feedback from multiple trainers improves the total feedback's accuracy and make the collection process easier in two ways. Firstly, this approach addresses the case of some of the trainers being adversarial. Secondly, having access to the information about each trainer reliability provides a second layer of robustness and offers valuable information for people managing the whole system to improve the overall trust in the system. It offers an actionable tool for improving the feedback collection process or modifying the reward function design if needed. We empirically show that our approach can accurately learn the reliability of each trainer correctly and use it to maximise the information gained from the multiple trainers' feedback, even if some of the sources are adversarial.
Model-Based Reinforcement Learning for Type 1Diabetes Blood Glucose Control
Oct 13, 2020
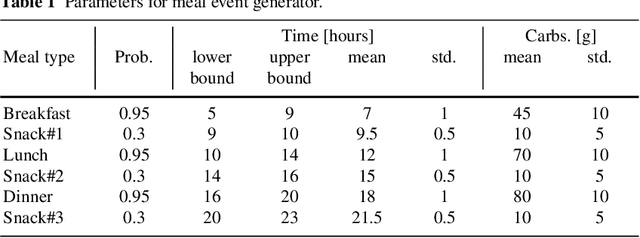
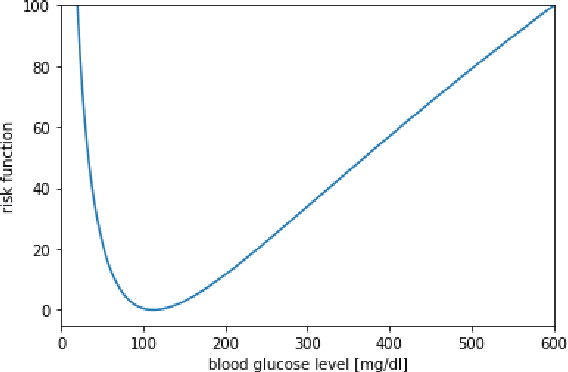
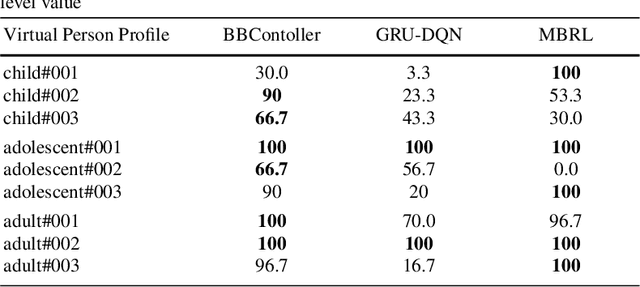
In this paper we investigate the use of model-based reinforcement learning to assist people with Type 1 Diabetes with insulin dose decisions. The proposed architecture consists of multiple Echo State Networks to predict blood glucose levels combined with Model Predictive Controller for planning. Echo State Network is a version of recurrent neural networks which allows us to learn long term dependencies in the input of time series data in an online manner. Additionally, we address the quantification of uncertainty for a more robust control. Here, we used ensembles of Echo State Networks to capture model (epistemic) uncertainty. We evaluated the approach with the FDA-approved UVa/Padova Type 1 Diabetes simulator and compared the results against baseline algorithms such as Basal-Bolus controller and Deep Q-learning. The results suggest that the model-based reinforcement learning algorithm can perform equally or better than the baseline algorithms for the majority of virtual Type 1 Diabetes person profiles tested.
Online Feature Selection for Activity Recognition using Reinforcement Learning with Multiple Feedback
Aug 16, 2019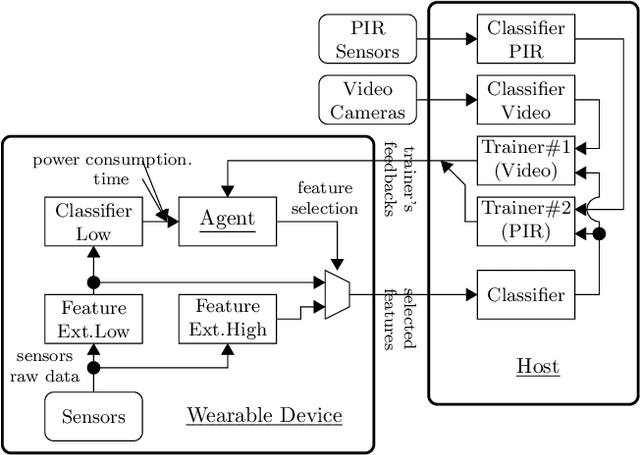
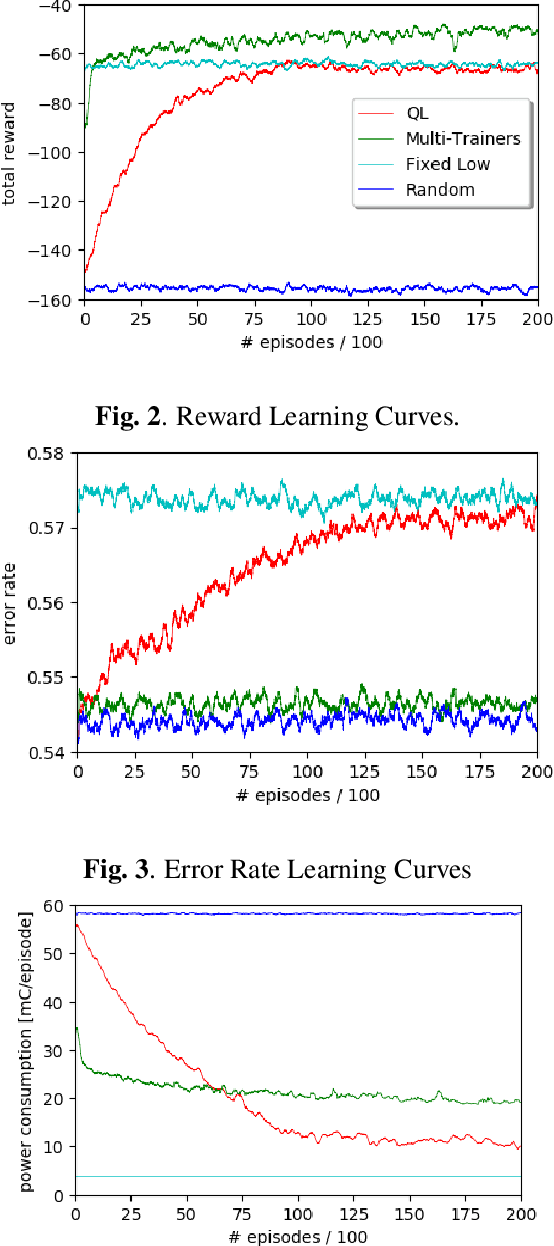
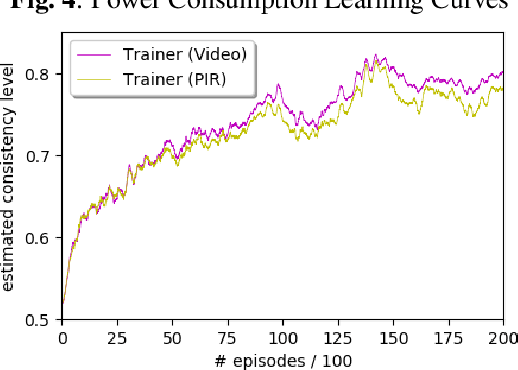
Recent advances in both machine learning and Internet-of-Things have attracted attention to automatic Activity Recognition, where users wear a device with sensors and their outputs are mapped to a predefined set of activities. However, few studies have considered the balance between wearable power consumption and activity recognition accuracy. This is particularly important when part of the computational load happens on the wearable device. In this paper, we present a new methodology to perform feature selection on the device based on Reinforcement Learning (RL) to find the optimum balance between power consumption and accuracy. To accelerate the learning speed, we extend the RL algorithm to address multiple sources of feedback, and use them to tailor the policy in conjunction with estimating the feedback accuracy. We evaluated our system on the SPHERE challenge dataset, a publicly available research dataset. The results show that our proposed method achieves a good trade-off between wearable power consumption and activity recognition accuracy.