 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Feedback from Multiple Humans with Diverse Skills
Paper and Code
Nov 16, 2021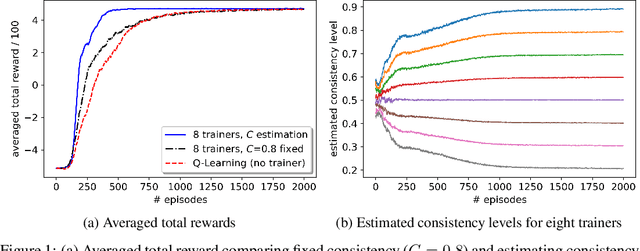
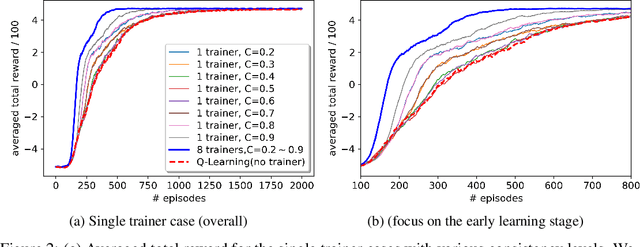
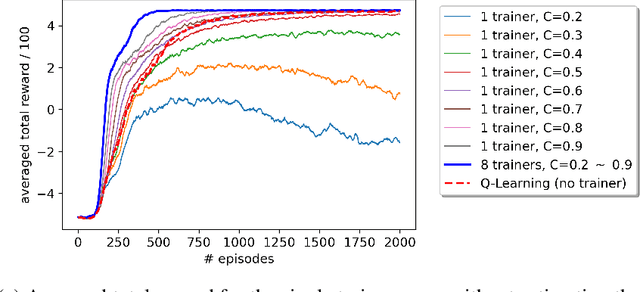
A promising approach to improve the robustness and exploration in Reinforcement Learning is collecting human feedback and that way incorporating prior knowledge of the target environment. It is, however, often too expensive to obtain enough feedback of good quality. To mitigate the issue, we aim to rely on a group of multiple experts (and non-experts) with different skill levels to generate enough feedback. Such feedback can therefore be inconsistent and infrequent. In this paper, we build upon prior work -- Advise, a Bayesian approach attempting to maximise the information gained from human feedback -- extending the algorithm to accept feedback from this larger group of humans, the trainers, while also estimating each trainer's reliability. We show how aggregating feedback from multiple trainers improves the total feedback's accuracy and make the collection process easier in two ways. Firstly, this approach addresses the case of some of the trainers being adversarial. Secondly, having access to the information about each trainer reliability provides a second layer of robustness and offers valuable information for people managing the whole system to improve the overall trust in the system. It offers an actionable tool for improving the feedback collection process or modifying the reward function design if needed. We empirically show that our approach can accurately learn the reliability of each trainer correctly and use it to maximise the information gained from the multiple trainers' feedback, even if some of the sources are adversarial.