 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame-Theoretic Autonomous Driving: A Graphs of Convex Sets Approach
Jan 27, 2026Multi-vehicle autonomous driving couples strategic interaction with hybrid (discrete-continuous) maneuver planning under shared safety constraints. We introduce IBR-GCS, an Iterative Best Response (IBR) planning approach based on the Graphs of Convex Sets (GCS) framework that models highway driving as a generalized noncooperative game. IBR-GCS integrates combinatorial maneuver reasoning, trajectory planning, and game-theoretic interaction within a unified framework. The key novelty is a vehicle-specific, strategy-dependent GCS construction. Specifically, at each best-response update, each vehicle builds its own graph conditioned on the current strategies of the other vehicles, with vertices representing lane-specific, time-varying, convex, collision-free regions and edges encoding dynamically feasible transitions. This yields a shortest-path problem in GCS for each best-response step, which admits an efficient convex relaxation that can be solved using convex optimization tools without exhaustive discrete tree search. We then apply an iterative best-response scheme in which vehicles update their trajectories sequentially and provide conditions under which the resulting inexact updates converge to an approximate generalized Nash equilibrium. Simulation results across multi-lane, multi-vehicle scenarios demonstrate that IBR-GCS produces safe trajectories and strategically consistent interactive behaviors.
TransformerMPC: Accelerating Model Predictive Control via Transformers
Sep 14, 2024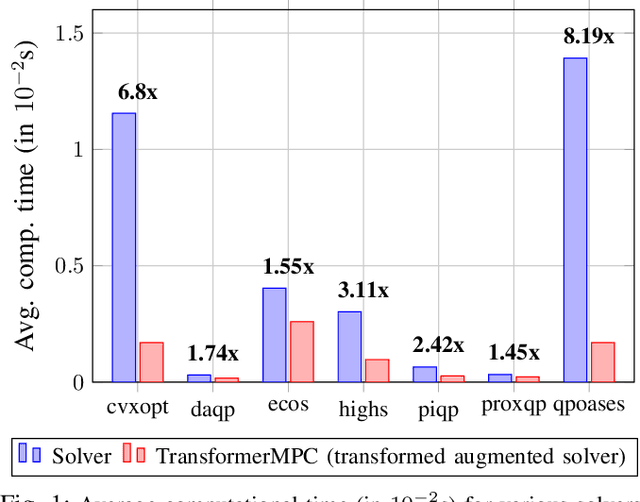
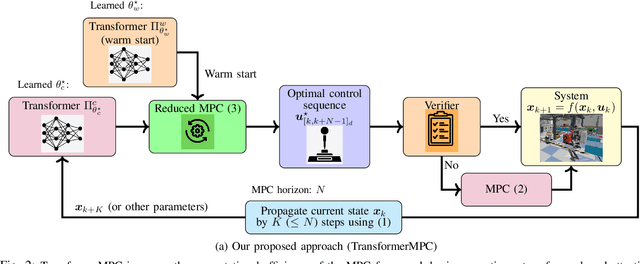
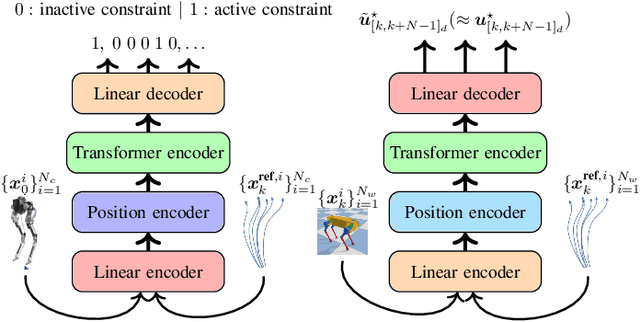
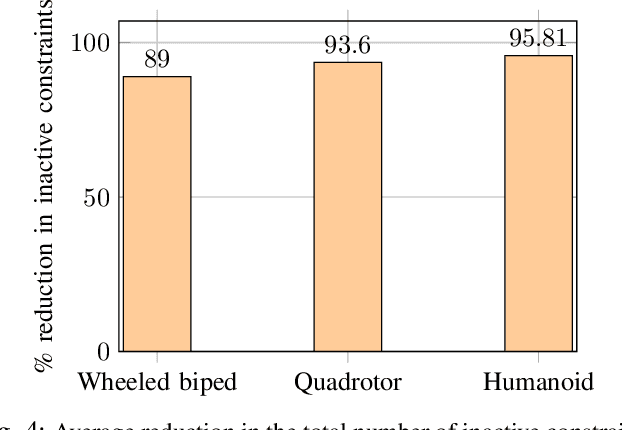
In this paper, we address the problem of reducing the computational burden of Model Predictive Control (MPC) for real-time robotic applications. We propose TransformerMPC, a method that enhances the computational efficiency of MPC algorithms by leveraging the attention mechanism in transformers for both online constraint removal and better warm start initialization. Specifically, TransformerMPC accelerates the computation of optimal control inputs by selecting only the active constraints to be included in the MPC problem, while simultaneously providing a warm start to the optimization process. This approach ensures that the original constraints are satisfied at optimality. TransformerMPC is designed to be seamlessly integrated with any MPC solver, irrespective of its implementation. To guarantee constraint satisfaction after removing inactive constraints, we perform an offline verification to ensure that the optimal control inputs generated by the MPC solver meet all constraints. The effectiveness of TransformerMPC is demonstrated through extensive numerical simulations on complex robotic systems, achieving up to 35x improvement in runtime without any loss in performance.
LL-VQ-VAE: Learnable Lattice Vector-Quantization For Efficient Representations
Oct 13, 2023In this paper we introduce learnable lattice vector quantization and demonstrate its effectiveness for learning discrete representations. Our method, termed LL-VQ-VAE, replaces the vector quantization layer in VQ-VAE with lattice-based discretization. The learnable lattice imposes a structure over all discrete embeddings, acting as a deterrent against codebook collapse, leading to high codebook utilization. Compared to VQ-VAE, our method obtains lower reconstruction errors under the same training conditions, trains in a fraction of the time, and with a constant number of parameters (equal to the embedding dimension $D$), making it a very scalable approach. We demonstrate these results on the FFHQ-1024 dataset and include FashionMNIST and Celeb-A.
Q-learning Decision Transformer: Leveraging Dynamic Programming for Conditional Sequence Modelling in Offline RL
Sep 08, 2022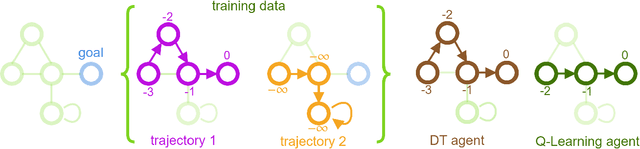
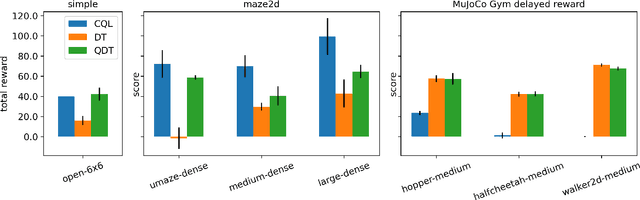
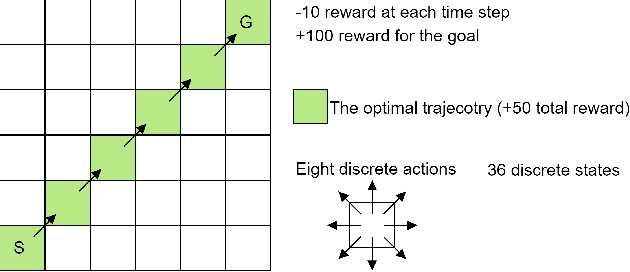

Recent works have shown that tackling offline reinforcement learning (RL) with a conditional policy produces promising results by converting the RL task to a supervised learning task. Decision Transformer (DT) combines the conditional policy approach and Transformer architecture to show competitive performance against several benchmarks. However, DT lacks stitching ability -- one of the critical abilities for offline RL that learns the optimal policy from sub-optimal trajectories. The issue becomes significant when the offline dataset only contains sub-optimal trajectories. On the other hand, the conventional RL approaches based on Dynamic Programming (such as Q-learning) do not suffer the same issue; however, they suffer from unstable learning behaviours, especially when it employs function approximation in an off-policy learning setting. In this paper, we propose Q-learning Decision Transformer (QDT) that addresses the shortcomings of DT by leveraging the benefit of Dynamic Programming (Q-learning). QDT utilises the Dynamic Programming (Q-learning) results to relabel the return-to-go in the training data. We then train the DT with the relabelled data. Our approach efficiently exploits the benefits of these two approaches and compensates for each other's shortcomings to achieve better performance. We demonstrate the issue of DT and the advantage of QDT in a simple environment. We also evaluate QDT in the more complex D4RL benchmark showing good performance gains.
RLOps: Development Life-cycle of Reinforcement Learning Aided Open RAN
Nov 12, 2021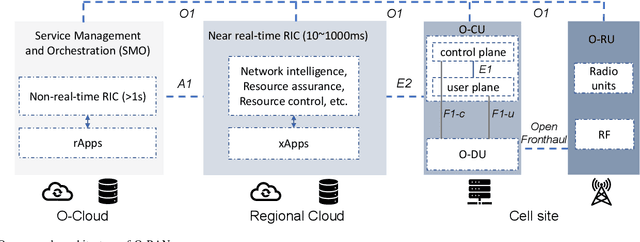
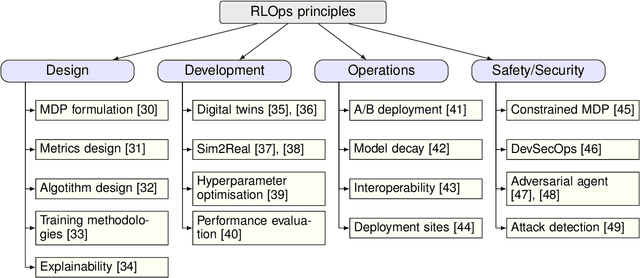
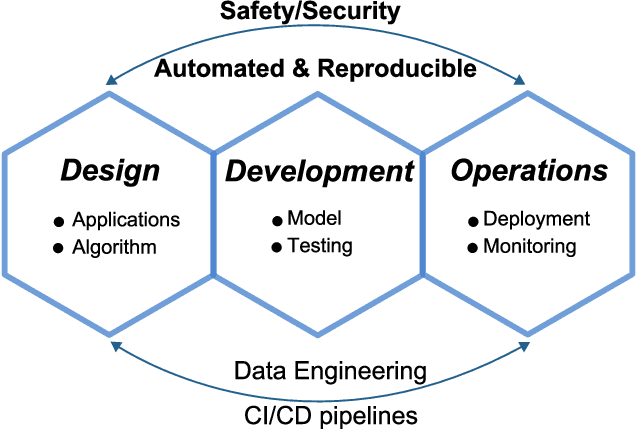
Radio access network (RAN) technologies continue to witness massive growth, with Open RAN gaining the most recent momentum. In the O-RAN specifications, the RAN intelligent controller (RIC) serves as an automation host. This article introduces principles for machine learning (ML), in particular, reinforcement learning (RL) relevant for the O-RAN stack. Furthermore, we review state-of-the-art research in wireless networks and cast it onto the RAN framework and the hierarchy of the O-RAN architecture. We provide a taxonomy of the challenges faced by ML/RL models throughout the development life-cycle: from the system specification to production deployment (data acquisition, model design, testing and management, etc.). To address the challenges, we integrate a set of existing MLOps principles with unique characteristics when RL agents are considered. This paper discusses a systematic life-cycle model development, testing and validation pipeline, termed: RLOps. We discuss all fundamental parts of RLOps, which include: model specification, development and distillation, production environment serving, operations monitoring, safety/security and data engineering platform. Based on these principles, we propose the best practices for RLOps to achieve an automated and reproducible model development process.