 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Bias of Web-filtered Text Datasets and Bias Propagation Through Training
Dec 03, 2024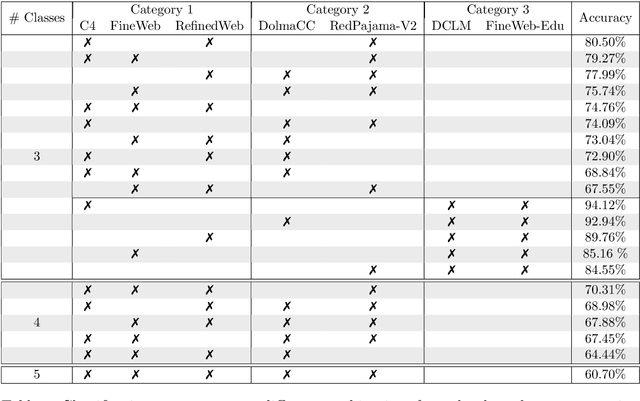
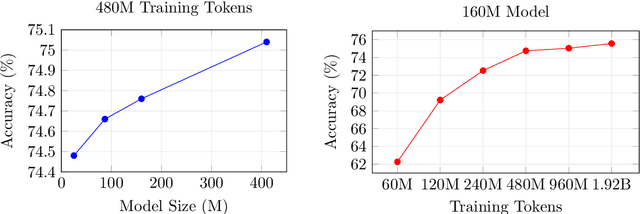


We investigate biases in pretraining datasets for large language models (LLMs) through dataset classification experiments. Building on prior work demonstrating the existence of biases in popular computer vision datasets, we analyze popular open-source pretraining datasets for LLMs derived from CommonCrawl including C4, RefinedWeb, DolmaCC, RedPajama-V2, FineWeb, and DCLM-Baseline. Despite those datasets being obtained with similar filtering and deduplication steps, neural networks can classify surprisingly well which dataset a single text sequence belongs to, significantly better than a human can. This indicates that popular pretraining datasets have their own unique biases or fingerprints. Those biases remain even when the text is rewritten with LLMs. Moreover, these biases propagate through training: Random sequences generated by models trained on those datasets can be classified well by a classifier trained on the original datasets.
GAMA-IR: Global Additive Multidimensional Averaging for Fast Image Restoration
Mar 31, 2024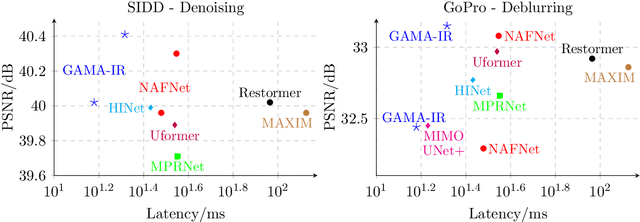

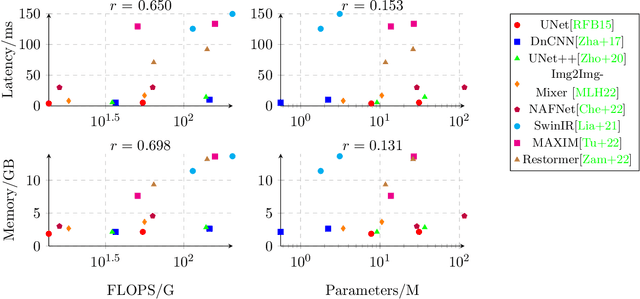
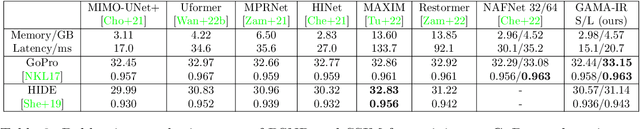
Deep learning-based methods have shown remarkable success for various image restoration tasks such as denoising and deblurring. The current state-of-the-art networks are relatively deep and utilize (variants of) self attention mechanisms. Those networks are significantly slower than shallow convolutional networks, which however perform worse. In this paper, we introduce an image restoration network that is both fast and yields excellent image quality. The network is designed to minimize the latency and memory consumption when executed on a standard GPU, while maintaining state-of-the-art performance. The network is a simple shallow network with an efficient block that implements global additive multidimensional averaging operations. This block can capture global information and enable a large receptive field even when used in shallow networks with minimal computational overhead. Through extensive experiments and evaluations on diverse tasks, we demonstrate that our network achieves comparable or even superior results to existing state-of-the-art image restoration networks with less latency. For instance, we exceed the state-of-the-art result on real-world SIDD denoising by 0.11dB, while being 2 to 10 times faster.
Zero-Shot Noise2Noise: Efficient Image Denoising without any Data
Mar 20, 2023



Recently, self-supervised neural networks have shown excellent image denoising performance. However, current dataset free methods are either computationally expensive, require a noise model, or have inadequate image quality. In this work we show that a simple 2-layer network, without any training data or knowledge of the noise distribution, can enable high-quality image denoising at low computational cost. Our approach is motivated by Noise2Noise and Neighbor2Neighbor and works well for denoising pixel-wise independent noise. Our experiments on artificial, real-world camera, and microscope noise show that our method termed ZS-N2N (Zero Shot Noise2Noise) often outperforms existing dataset-free methods at a reduced cost, making it suitable for use cases with scarce data availability and limited compute resources. A demo of our implementation including our code and hyperparameters can be found in the following colab notebook: https://colab.research.google.com/drive/1i82nyizTdszyHkaHBuKPbWnTzao8HF9b
Image-to-Image MLP-mixer for Image Reconstruction
Feb 04, 2022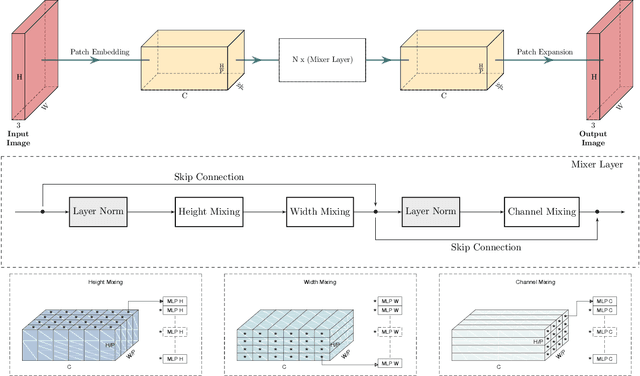
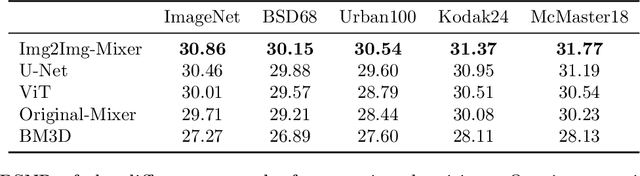
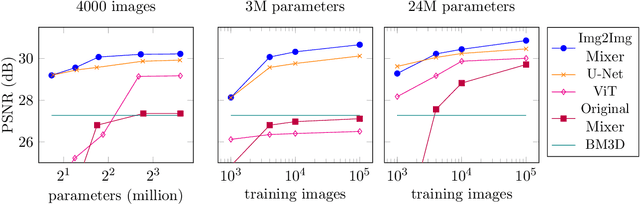

Neural networks are highly effective tools for image reconstruction problems such as denoising and compressive sensing. To date, neural networks for image reconstruction are almost exclusively convolutional. The most popular architecture is the U-Net, a convolutional network with a multi-resolution architecture. In this work, we show that a simple network based on the multi-layer perceptron (MLP)-mixer enables state-of-the art image reconstruction performance without convolutions and without a multi-resolution architecture, provided that the training set and the size of the network are moderately large. Similar to the original MLP-mixer, the image-to-image MLP-mixer is based exclusively on MLPs operating on linearly-transformed image patches. Contrary to the original MLP-mixer, we incorporate structure by retaining the relative positions of the image patches. This imposes an inductive bias towards natural images which enables the image-to-image MLP-mixer to learn to denoise images based on fewer examples than the original MLP-mixer. Moreover, the image-to-image MLP-mixer requires fewer parameters to achieve the same denoising performance than the U-Net and its parameters scale linearly in the image resolution instead of quadratically as for the original MLP-mixer. If trained on a moderate amount of examples for denoising, the image-to-image MLP-mixer outperforms the U-Net by a slight margin. It also outperforms the vision transformer tailored for image reconstruction and classical un-trained methods such as BM3D, making it a very effective tool for image reconstruction problems.