 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHS-Mamba: Full-Field Interaction Multi-Groups Mamba for Hyperspectral Image Classification
Apr 22, 2025



Hyperspectral image (HSI) classification has been one of the hot topics in remote sensing fields. Recently, the Mamba architecture based on selective state-space models (S6) has demonstrated great advantages in long sequence modeling. However, the unique properties of hyperspectral data, such as high dimensionality and feature inlining, pose challenges to the application of Mamba to HSI classification. To compensate for these shortcomings, we propose an full-field interaction multi-groups Mamba framework (HS-Mamba), which adopts a strategy different from pixel-patch based or whole-image based, but combines the advantages of both. The patches cut from the whole image are sent to multi-groups Mamba, combined with positional information to perceive local inline features in the spatial and spectral domains, and the whole image is sent to a lightweight attention module to enhance the global feature representation ability. Specifically, HS-Mamba consists of a dual-channel spatial-spectral encoder (DCSS-encoder) module and a lightweight global inline attention (LGI-Att) branch. The DCSS-encoder module uses multiple groups of Mamba to decouple and model the local features of dual-channel sequences with non-overlapping patches. The LGI-Att branch uses a lightweight compressed and extended attention module to perceive the global features of the spatial and spectral domains of the unsegmented whole image. By fusing local and global features, high-precision classification of hyperspectral images is achieved. Extensive experiments demonstrate the superiority of the proposed HS-Mamba, outperforming state-of-the-art methods on four benchmark HSI datasets.
Robustness of Deep Learning for Accelerated MRI: Benefits of Diverse Training Data
Dec 16, 2023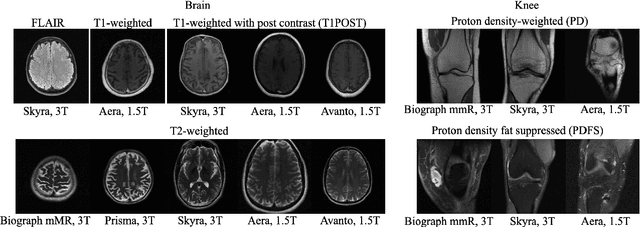



Deep learning based methods for image reconstruction are state-of-the-art for a variety of imaging tasks. However, neural networks often perform worse if the training data differs significantly from the data they are applied to. For example, a network trained for accelerated magnetic resonance imaging (MRI) on one scanner performs worse on another scanner. In this work, we investigate the impact of the training data on the model's performance and robustness for accelerated MRI. We find that models trained on the combination of various data distributions, such as those obtained from different MRI scanners and anatomies, exhibit robustness equal or superior to models trained on the best single distribution for a specific target distribution. Thus training on diverse data tends to improve robustness. Furthermore, training on diverse data does not compromise in-distribution performance, i.e., a model trained on diverse data yields in-distribution performance at least as good as models trained on the more narrow individual distributions. Our results suggest that training a model for imaging on a variety of distributions tends to yield a more effective and robust model than maintaining separate models for individual distributions.
Image-to-Image MLP-mixer for Image Reconstruction
Feb 04, 2022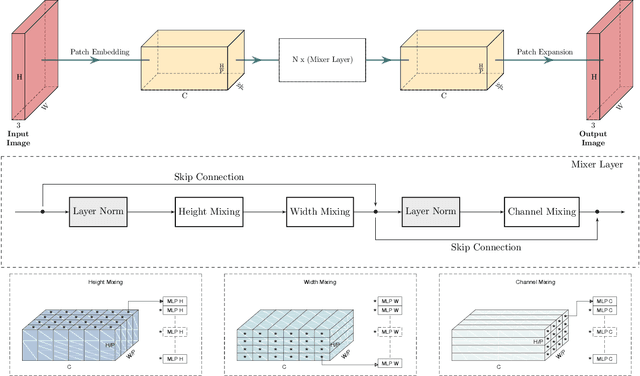
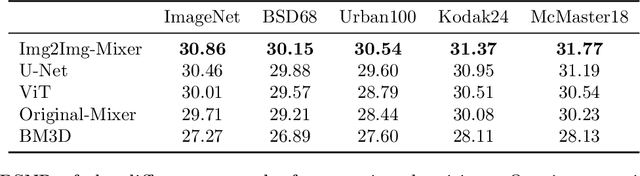
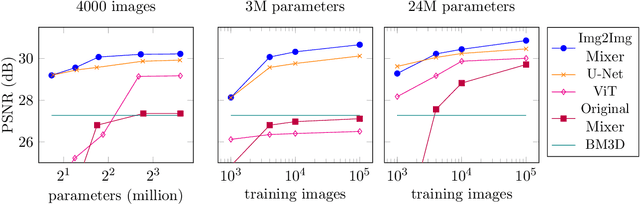

Neural networks are highly effective tools for image reconstruction problems such as denoising and compressive sensing. To date, neural networks for image reconstruction are almost exclusively convolutional. The most popular architecture is the U-Net, a convolutional network with a multi-resolution architecture. In this work, we show that a simple network based on the multi-layer perceptron (MLP)-mixer enables state-of-the art image reconstruction performance without convolutions and without a multi-resolution architecture, provided that the training set and the size of the network are moderately large. Similar to the original MLP-mixer, the image-to-image MLP-mixer is based exclusively on MLPs operating on linearly-transformed image patches. Contrary to the original MLP-mixer, we incorporate structure by retaining the relative positions of the image patches. This imposes an inductive bias towards natural images which enables the image-to-image MLP-mixer to learn to denoise images based on fewer examples than the original MLP-mixer. Moreover, the image-to-image MLP-mixer requires fewer parameters to achieve the same denoising performance than the U-Net and its parameters scale linearly in the image resolution instead of quadratically as for the original MLP-mixer. If trained on a moderate amount of examples for denoising, the image-to-image MLP-mixer outperforms the U-Net by a slight margin. It also outperforms the vision transformer tailored for image reconstruction and classical un-trained methods such as BM3D, making it a very effective tool for image reconstruction problems.