 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Bounds on Parallel Imaging Implicit Data Crimes in an MRI Reproducing Kernel Hilbert Space
Nov 19, 2025Magnetic Resonance Imaging (MRI) diagnoses and manages a wide range of diseases, yet long scan times drive high costs and limit accessibility. AI methods have demonstrated substantial potential for reducing scan times, but despite rapid progress, clinical translation of AI often fails. One particular class of failure modes, referred to as implicit data crimes, are a result of hidden biases introduced when MRI datasets incompletely model the MRI physics of the acquisition. Previous work identified data crimes resulting from algorithmic completion of k-space with parallel imaging and drew on simulation to demonstrate the resulting downstream biases. This work proposes a mathematical framework to re-characterize the problem as one of error reduction during interpolation between sets of evaluation coordinates. We establish a generalized matrix-based definition of the reconstruction error upper bound as a function of the input sampling pattern. Experiments on relevant sampling pattern structures demonstrate the relevance of the framework and suggest future directions for analysis of data crimes.
MIMO Channel Estimation using Score-Based Generative Models
Apr 14, 2022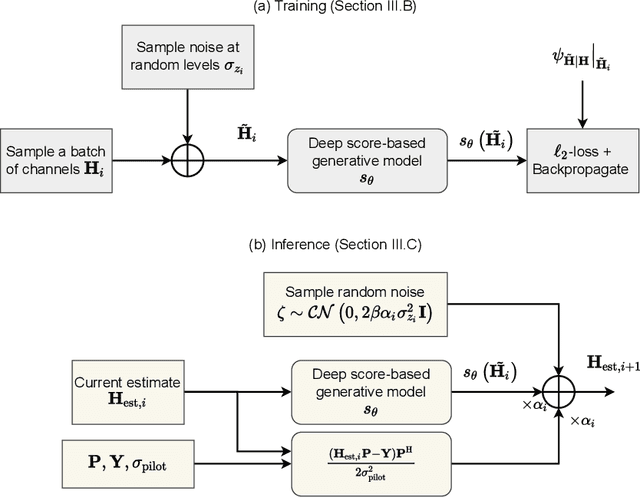
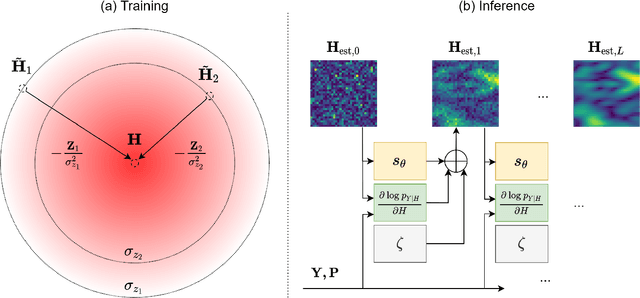
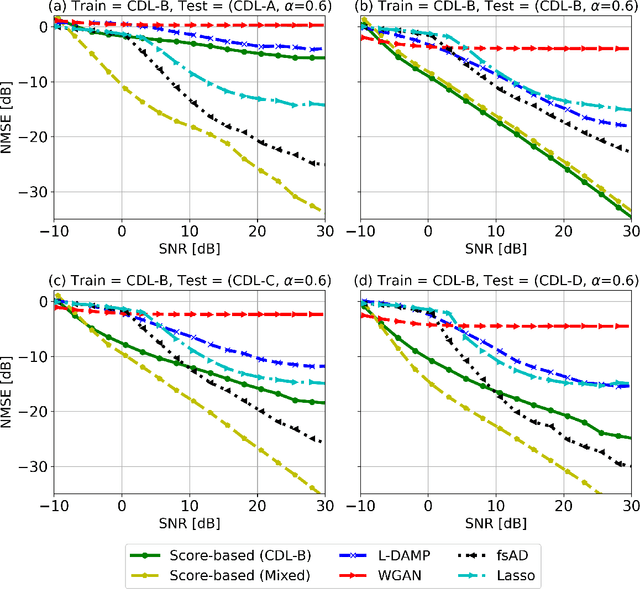
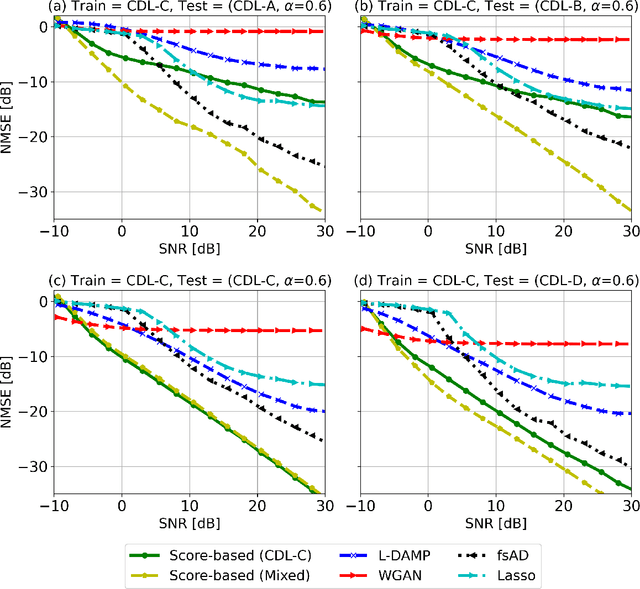
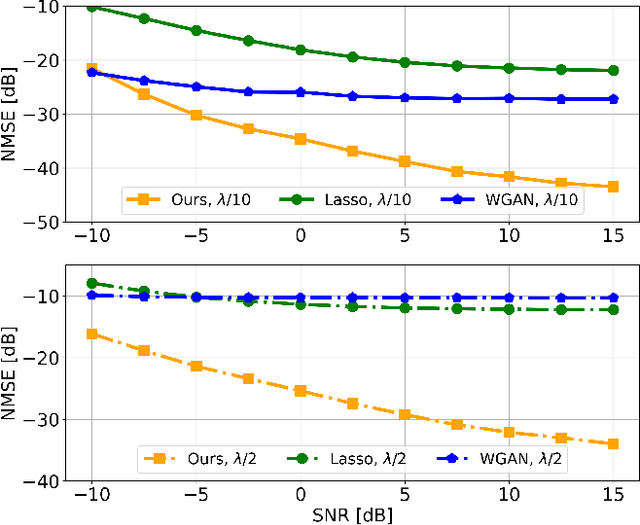
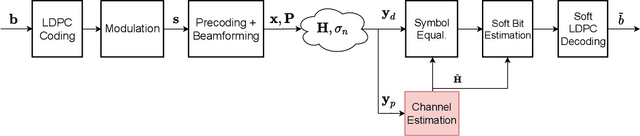
Channel estimation is a critical task in multiple-input multiple-output digital communications that has effects on end-to-end system performance. In this work, we introduce a novel approach for channel estimation using deep score-based generative models. These models are trained to estimate the gradient of the log-prior distribution, and can be used to iteratively refine estimates, given observed measurements of a signal. We introduce a framework for training score-based generative models for wireless channels, as well as performing channel estimation using posterior sampling at test time. We derive theoretical robustness guarantees of channel estimation with posterior sampling in single-input single-output scenarios, and show that the observations regarding estimation performance are verified experimentally in MIMO channels. Our results in simulated clustered delay line channels show competitive in-distribution performance without error floors in the high signal-to-noise ratio regime, and robust out-of-distribution performance, outperforming competing deep learning methods by up to 5 dB in end-to-end communication performance, while the complexity analysis reveals how model architecture can efficiently trade performance for estimation latency.
Deep Diffusion Models for Robust Channel Estimation
Nov 16, 2021
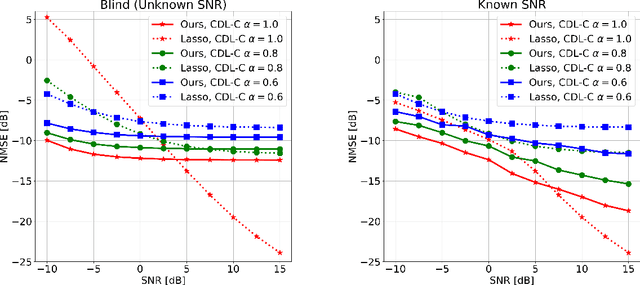
Channel estimation is a critical task in digital communications that greatly impacts end-to-end system performance. In this work, we introduce a novel approach for multiple-input multiple-output (MIMO) channel estimation using deep diffusion models. Our method uses a deep neural network that is trained to estimate the gradient of the log-likelihood of wireless channels at any point in high-dimensional space, and leverages this model to solve channel estimation via posterior sampling. We train a deep diffusion model on channel realizations from the CDL-D model for two antenna spacings and show that the approach leads to competitive in- and out-of-distribution performance when compared to generative adversarial network (GAN) and compressed sensing (CS) methods. When tested on CDL-C channels which are never seen during training or fine-tuned on, our approach leads to end-to-end coded performance gains of up to $3$ dB compared to CS methods and losses of only $0.5$ dB compared to ideal channel knowledge. To encourage open and reproducible research, our source code is available at https://github.com/utcsilab/diffusion-channels .
High Fidelity Deep Learning-based MRI Reconstruction with Instance-wise Discriminative Feature Matching Loss
Aug 27, 2021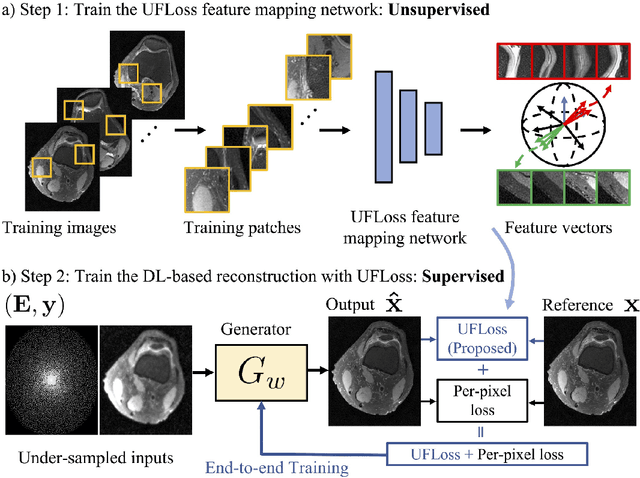
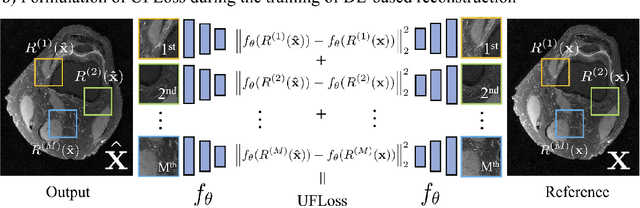
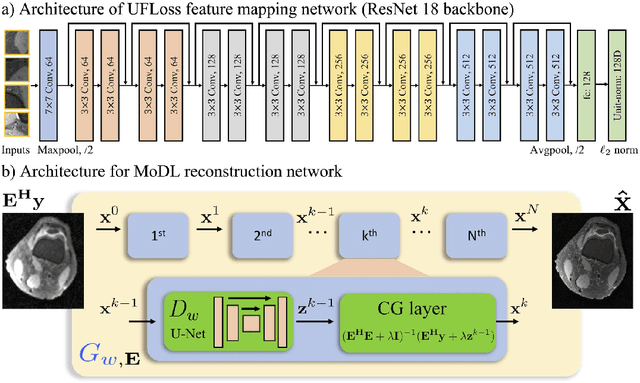
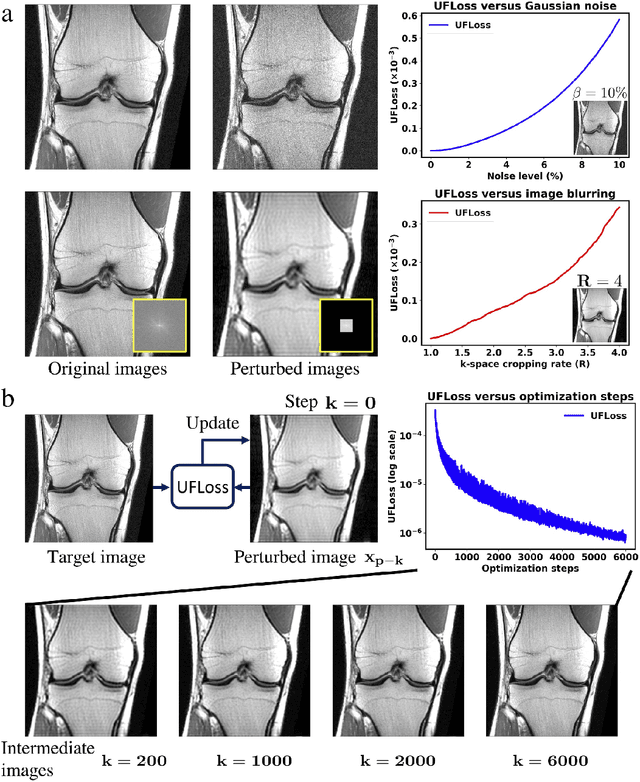
Purpose: To improve reconstruction fidelity of fine structures and textures in deep learning (DL) based reconstructions. Methods: A novel patch-based Unsupervised Feature Loss (UFLoss) is proposed and incorporated into the training of DL-based reconstruction frameworks in order to preserve perceptual similarity and high-order statistics. The UFLoss provides instance-level discrimination by mapping similar instances to similar low-dimensional feature vectors and is trained without any human annotation. By adding an additional loss function on the low-dimensional feature space during training, the reconstruction frameworks from under-sampled or corrupted data can reproduce more realistic images that are closer to the original with finer textures, sharper edges, and improved overall image quality. The performance of the proposed UFLoss is demonstrated on unrolled networks for accelerated 2D and 3D knee MRI reconstruction with retrospective under-sampling. Quantitative metrics including NRMSE, SSIM, and our proposed UFLoss were used to evaluate the performance of the proposed method and compare it with others. Results: In-vivo experiments indicate that adding the UFLoss encourages sharper edges and more faithful contrasts compared to traditional and learning-based methods with pure l2 loss. More detailed textures can be seen in both 2D and 3D knee MR images. Quantitative results indicate that reconstruction with UFLoss can provide comparable NRMSE and a higher SSIM while achieving a much lower UFLoss value. Conclusion: We present UFLoss, a patch-based unsupervised learned feature loss, which allows the training of DL-based reconstruction to obtain more detailed texture, finer features, and sharper edges with higher overall image quality under DL-based reconstruction frameworks.