 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperceptible Adversarial Examples in the Physical World
Nov 25, 2024



Adversarial examples in the digital domain against deep learning-based computer vision models allow for perturbations that are imperceptible to human eyes. However, producing similar adversarial examples in the physical world has been difficult due to the non-differentiable image distortion functions in visual sensing systems. The existing algorithms for generating physically realizable adversarial examples often loosen their definition of adversarial examples by allowing unbounded perturbations, resulting in obvious or even strange visual patterns. In this work, we make adversarial examples imperceptible in the physical world using a straight-through estimator (STE, a.k.a. BPDA). We employ STE to overcome the non-differentiability -- applying exact, non-differentiable distortions in the forward pass of the backpropagation step, and using the identity function in the backward pass. Our differentiable rendering extension to STE also enables imperceptible adversarial patches in the physical world. Using printout photos, and experiments in the CARLA simulator, we show that STE enables fast generation of $\ell_\infty$ bounded adversarial examples despite the non-differentiable distortions. To the best of our knowledge, this is the first work demonstrating imperceptible adversarial examples bounded by small $\ell_\infty$ norms in the physical world that force zero classification accuracy in the global perturbation threat model and cause near-zero ($4.22\%$) AP50 in object detection in the patch perturbation threat model. We urge the community to re-evaluate the threat of adversarial examples in the physical world.
Enhancing Deep Learning-Driven Multi-Coil MRI Reconstruction via Self-Supervised Denoising
Nov 19, 2024We examine the effect of incorporating self-supervised denoising as a pre-processing step for training deep learning (DL) based reconstruction methods on data corrupted by Gaussian noise. K-space data employed for training are typically multi-coil and inherently noisy. Although DL-based reconstruction methods trained on fully sampled data can enable high reconstruction quality, obtaining large, noise-free datasets is impractical. We leverage Generalized Stein's Unbiased Risk Estimate (GSURE) for denoising. We evaluate two DL-based reconstruction methods: Diffusion Probabilistic Models (DPMs) and Model-Based Deep Learning (MoDL). We evaluate the impact of denoising on the performance of these DL-based methods in solving accelerated multi-coil magnetic resonance imaging (MRI) reconstruction. The experiments were carried out on T2-weighted brain and fat-suppressed proton-density knee scans. We observed that self-supervised denoising enhances the quality and efficiency of MRI reconstructions across various scenarios. Specifically, employing denoised images rather than noisy counterparts when training DL networks results in lower normalized root mean squared error (NRMSE), higher structural similarity index measure (SSIM) and peak signal-to-noise ratio (PSNR) across different SNR levels, including 32dB, 22dB, and 12dB for T2-weighted brain data, and 24dB, 14dB, and 4dB for fat-suppressed knee data. Overall, we showed that denoising is an essential pre-processing technique capable of improving the efficacy of DL-based MRI reconstruction methods under diverse conditions. By refining the quality of input data, denoising can enable the training of more effective DL networks, potentially bypassing the need for noise-free reference MRI scans.
Investigating the Semantic Robustness of CLIP-based Zero-Shot Anomaly Segmentation
May 13, 2024Zero-shot anomaly segmentation using pre-trained foundation models is a promising approach that enables effective algorithms without expensive, domain-specific training or fine-tuning. Ensuring that these methods work across various environmental conditions and are robust to distribution shifts is an open problem. We investigate the performance of WinCLIP [14] zero-shot anomaly segmentation algorithm by perturbing test data using three semantic transformations: bounded angular rotations, bounded saturation shifts, and hue shifts. We empirically measure a lower performance bound by aggregating across per-sample worst-case perturbations and find that average performance drops by up to 20% in area under the ROC curve and 40% in area under the per-region overlap curve. We find that performance is consistently lowered on three CLIP backbones, regardless of model architecture or learning objective, demonstrating a need for careful performance evaluation.
Enhancing O-RAN Security: Evasion Attacks and Robust Defenses for Graph Reinforcement Learning-based Connection Management
May 06, 2024Adversarial machine learning, focused on studying various attacks and defenses on machine learning (ML) models, is rapidly gaining importance as ML is increasingly being adopted for optimizing wireless systems such as Open Radio Access Networks (O-RAN). A comprehensive modeling of the security threats and the demonstration of adversarial attacks and defenses on practical AI based O-RAN systems is still in its nascent stages. We begin by conducting threat modeling to pinpoint attack surfaces in O-RAN using an ML-based Connection management application (xApp) as an example. The xApp uses a Graph Neural Network trained using Deep Reinforcement Learning and achieves on average 54% improvement in the coverage rate measured as the 5th percentile user data rates. We then formulate and demonstrate evasion attacks that degrade the coverage rates by as much as 50% through injecting bounded noise at different threat surfaces including the open wireless medium itself. Crucially, we also compare and contrast the effectiveness of such attacks on the ML-based xApp and a non-ML based heuristic. We finally develop and demonstrate robust training-based defenses against the challenging physical/jamming-based attacks and show a 15% improvement in the coverage rates when compared to employing no defense over a range of noise budgets
Investigating the Adversarial Robustness of Density Estimation Using the Probability Flow ODE
Oct 10, 2023



Beyond their impressive sampling capabilities, score-based diffusion models offer a powerful analysis tool in the form of unbiased density estimation of a query sample under the training data distribution. In this work, we investigate the robustness of density estimation using the probability flow (PF) neural ordinary differential equation (ODE) model against gradient-based likelihood maximization attacks and the relation to sample complexity, where the compressed size of a sample is used as a measure of its complexity. We introduce and evaluate six gradient-based log-likelihood maximization attacks, including a novel reverse integration attack. Our experimental evaluations on CIFAR-10 show that density estimation using the PF ODE is robust against high-complexity, high-likelihood attacks, and that in some cases adversarial samples are semantically meaningful, as expected from a robust estimator.
Solving Inverse Problems with Score-Based Generative Priors learned from Noisy Data
May 02, 2023



We present SURE-Score: an approach for learning score-based generative models using training samples corrupted by additive Gaussian noise. When a large training set of clean samples is available, solving inverse problems via score-based (diffusion) generative models trained on the underlying fully-sampled data distribution has recently been shown to outperform end-to-end supervised deep learning. In practice, such a large collection of training data may be prohibitively expensive to acquire in the first place. In this work, we present an approach for approximately learning a score-based generative model of the clean distribution, from noisy training data. We formulate and justify a novel loss function that leverages Stein's unbiased risk estimate to jointly denoise the data and learn the score function via denoising score matching, while using only the noisy samples. We demonstrate the generality of SURE-Score by learning priors and applying posterior sampling to ill-posed inverse problems in two practical applications from different domains: compressive wireless multiple-input multiple-output channel estimation and accelerated 2D multi-coil magnetic resonance imaging reconstruction, where we demonstrate competitive reconstruction performance when learning at signal-to-noise ratio values of 0 and 10 dB, respectively.
Automotive RADAR sub-sampling via object detection networks: Leveraging prior signal information
Feb 21, 2023


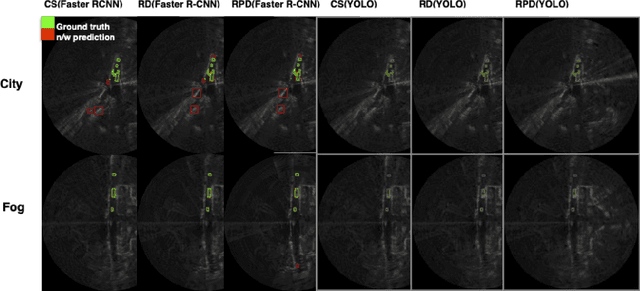
Automotive radar has increasingly attracted attention due to growing interest in autonomous driving technologies. Acquiring situational awareness using multimodal data collected at high sampling rates by various sensing devices including cameras, LiDAR, and radar requires considerable power, memory and compute resources which are often limited at an edge device. In this paper, we present a novel adaptive radar sub-sampling algorithm designed to identify regions that require more detailed/accurate reconstruction based on prior environmental conditions' knowledge, enabling near-optimal performance at considerably lower effective sampling rates. Designed to robustly perform under variable weather conditions, the algorithm was shown on the Oxford raw radar and RADIATE dataset to achieve accurate reconstruction utilizing only 10% of the original samples in good weather and 20% in extreme (snow, fog) weather conditions. A further modification of the algorithm incorporates object motion to enable reliable identification of important regions. This includes monitoring possible future occlusions caused by objects detected in the present frame. Finally, we train a YOLO network on the RADIATE dataset to perform object detection directly on RADAR data and obtain a 6.6% AP50 improvement over the baseline Faster R-CNN network.
MIMO Channel Estimation using Score-Based Generative Models
Apr 14, 2022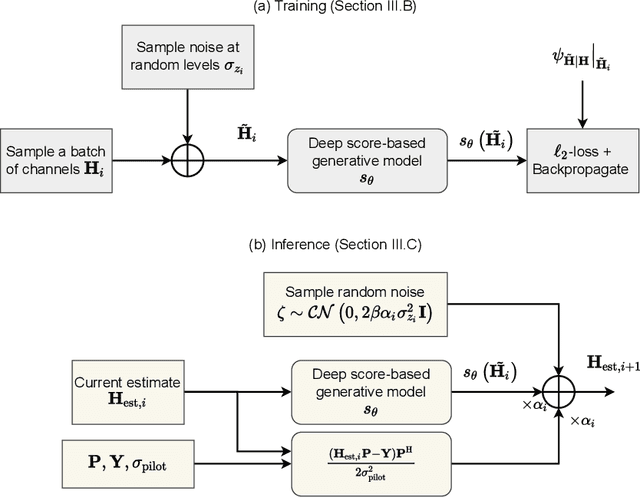
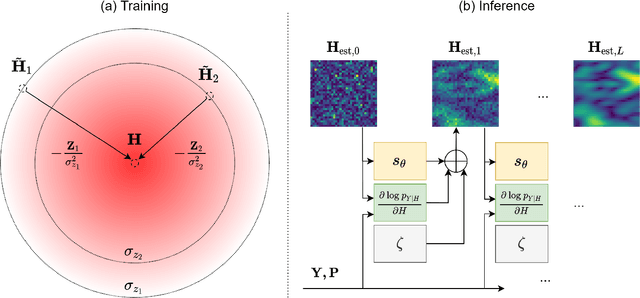
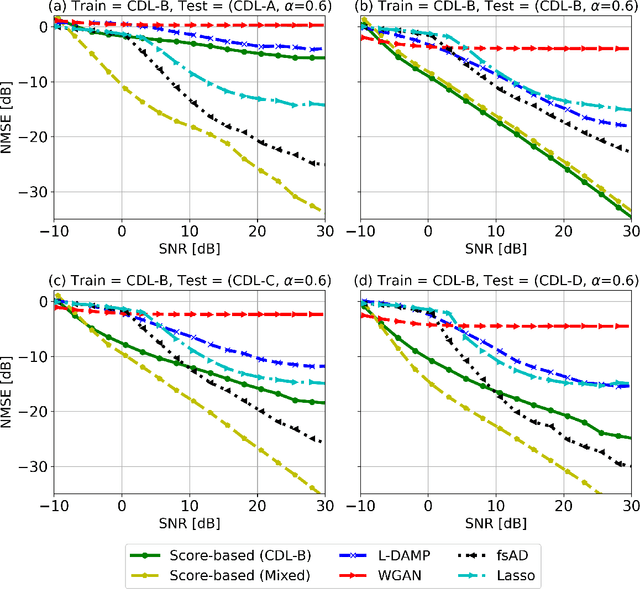
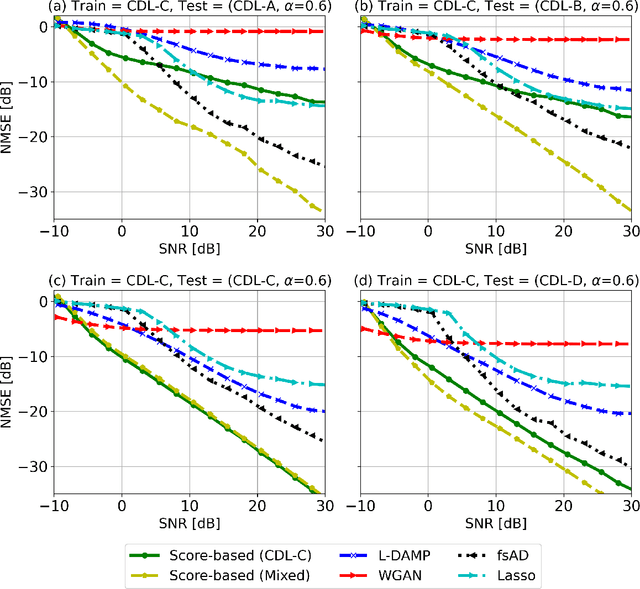
Channel estimation is a critical task in multiple-input multiple-output digital communications that has effects on end-to-end system performance. In this work, we introduce a novel approach for channel estimation using deep score-based generative models. These models are trained to estimate the gradient of the log-prior distribution, and can be used to iteratively refine estimates, given observed measurements of a signal. We introduce a framework for training score-based generative models for wireless channels, as well as performing channel estimation using posterior sampling at test time. We derive theoretical robustness guarantees of channel estimation with posterior sampling in single-input single-output scenarios, and show that the observations regarding estimation performance are verified experimentally in MIMO channels. Our results in simulated clustered delay line channels show competitive in-distribution performance without error floors in the high signal-to-noise ratio regime, and robust out-of-distribution performance, outperforming competing deep learning methods by up to 5 dB in end-to-end communication performance, while the complexity analysis reveals how model architecture can efficiently trade performance for estimation latency.
End-to-end system for object detection from sub-sampled radar data
Mar 08, 2022


Robust and accurate sensing is of critical importance for advancing autonomous automotive systems. The need to acquire situational awareness in complex urban conditions using sensors such as radar has motivated research on power and latency-efficient signal acquisition methods. In this paper, we present an end-to-end signal processing pipeline, capable of operating in extreme weather conditions, that relies on sub-sampled radar data to perform object detection in vehicular settings. The results of the object detection are further utilized to sub-sample forthcoming radar data, which stands in contrast to prior work where the sub-sampling relies on image information. We show robust detection based on radar data reconstructed using 20% of samples under extreme weather conditions such as snow or fog, and on low-illuminated nights. Additionally, we generate 20% sampled radar data in a fine-tuning set and show 1.1% gain in AP50 across scenes and 3% AP50 gain in motorway condition.
Deep Diffusion Models for Robust Channel Estimation
Nov 16, 2021
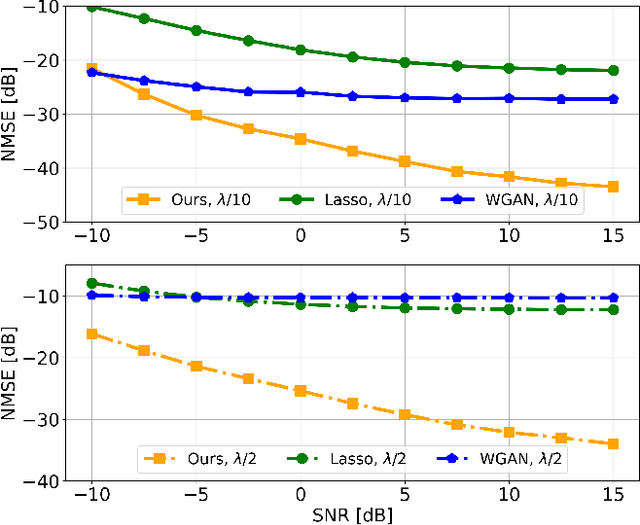
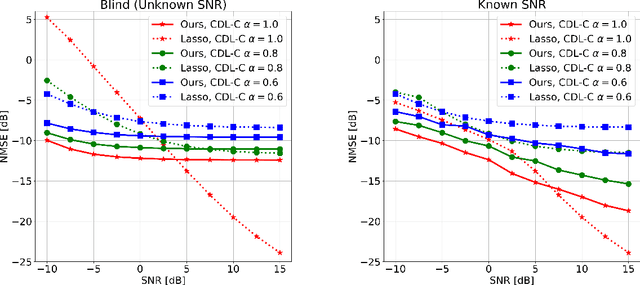
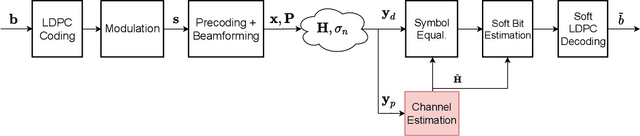
Channel estimation is a critical task in digital communications that greatly impacts end-to-end system performance. In this work, we introduce a novel approach for multiple-input multiple-output (MIMO) channel estimation using deep diffusion models. Our method uses a deep neural network that is trained to estimate the gradient of the log-likelihood of wireless channels at any point in high-dimensional space, and leverages this model to solve channel estimation via posterior sampling. We train a deep diffusion model on channel realizations from the CDL-D model for two antenna spacings and show that the approach leads to competitive in- and out-of-distribution performance when compared to generative adversarial network (GAN) and compressed sensing (CS) methods. When tested on CDL-C channels which are never seen during training or fine-tuned on, our approach leads to end-to-end coded performance gains of up to $3$ dB compared to CS methods and losses of only $0.5$ dB compared to ideal channel knowledge. To encourage open and reproducible research, our source code is available at https://github.com/utcsilab/diffusion-channels .