 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Video Compression Artifacts on Fisheye Camera Visual Perception Tasks
Mar 25, 2024



Autonomous driving systems require extensive data collection schemes to cover the diverse scenarios needed for building a robust and safe system. The data volumes are in the order of Exabytes and have to be stored for a long period of time (i.e., more than 10 years of the vehicle's life cycle). Lossless compression doesn't provide sufficient compression ratios, hence, lossy video compression has been explored. It is essential to prove that lossy video compression artifacts do not impact the performance of the perception algorithms. However, there is limited work in this area to provide a solid conclusion. In particular, there is no such work for fisheye cameras, which have high radial distortion and where compression may have higher artifacts. Fisheye cameras are commonly used in automotive systems for 3D object detection task. In this work, we provide the first analysis of the impact of standard video compression codecs on wide FOV fisheye camera images. We demonstrate that the achievable compression with negligible impact depends on the dataset and temporal prediction of the video codec. We propose a radial distortion-aware zonal metric to evaluate the performance of artifacts in fisheye images. In addition, we present a novel method for estimating affine mode parameters of the latest VVC codec, and suggest some areas for improvement in video codecs for the application to fisheye imagery.
Automotive RADAR sub-sampling via object detection networks: Leveraging prior signal information
Feb 21, 2023


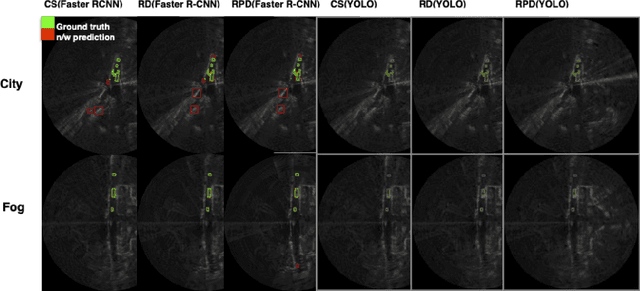
Automotive radar has increasingly attracted attention due to growing interest in autonomous driving technologies. Acquiring situational awareness using multimodal data collected at high sampling rates by various sensing devices including cameras, LiDAR, and radar requires considerable power, memory and compute resources which are often limited at an edge device. In this paper, we present a novel adaptive radar sub-sampling algorithm designed to identify regions that require more detailed/accurate reconstruction based on prior environmental conditions' knowledge, enabling near-optimal performance at considerably lower effective sampling rates. Designed to robustly perform under variable weather conditions, the algorithm was shown on the Oxford raw radar and RADIATE dataset to achieve accurate reconstruction utilizing only 10% of the original samples in good weather and 20% in extreme (snow, fog) weather conditions. A further modification of the algorithm incorporates object motion to enable reliable identification of important regions. This includes monitoring possible future occlusions caused by objects detected in the present frame. Finally, we train a YOLO network on the RADIATE dataset to perform object detection directly on RADAR data and obtain a 6.6% AP50 improvement over the baseline Faster R-CNN network.
Deep learning model compression using network sensitivity and gradients
Oct 11, 2022
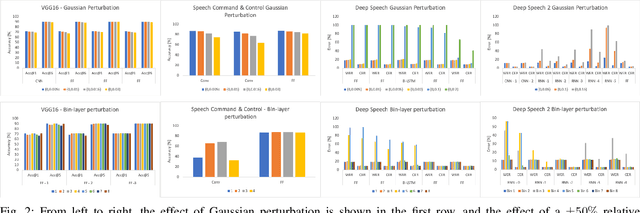
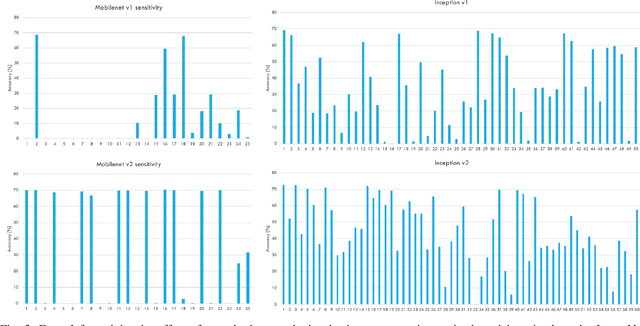
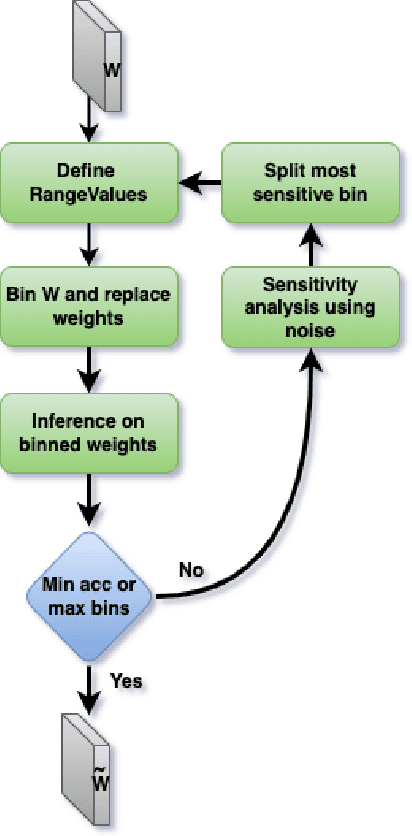
Deep learning model compression is an improving and important field for the edge deployment of deep learning models. Given the increasing size of the models and their corresponding power consumption, it is vital to decrease the model size and compute requirement without a significant drop in the model's performance. In this paper, we present model compression algorithms for both non-retraining and retraining conditions. In the first case where retraining of the model is not feasible due to lack of access to the original data or absence of necessary compute resources while only having access to off-the-shelf models, we propose the Bin & Quant algorithm for compression of the deep learning models using the sensitivity of the network parameters. This results in 13x compression of the speech command and control model and 7x compression of the DeepSpeech2 models. In the second case when the models can be retrained and utmost compression is required for the negligible loss in accuracy, we propose our novel gradient-weighted k-means clustering algorithm (GWK). This method uses the gradients in identifying the important weight values in a given cluster and nudges the centroid towards those values, thereby giving importance to sensitive weights. Our method effectively combines product quantization with the EWGS[1] algorithm for sub-1-bit representation of the quantized models. We test our GWK algorithm on the CIFAR10 dataset across a range of models such as ResNet20, ResNet56, MobileNetv2 and show 35x compression on quantized models for less than 2% absolute loss in accuracy compared to the floating-point models.
End-to-end system for object detection from sub-sampled radar data
Mar 08, 2022


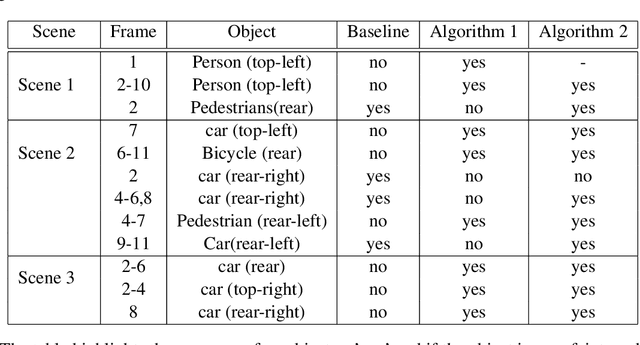
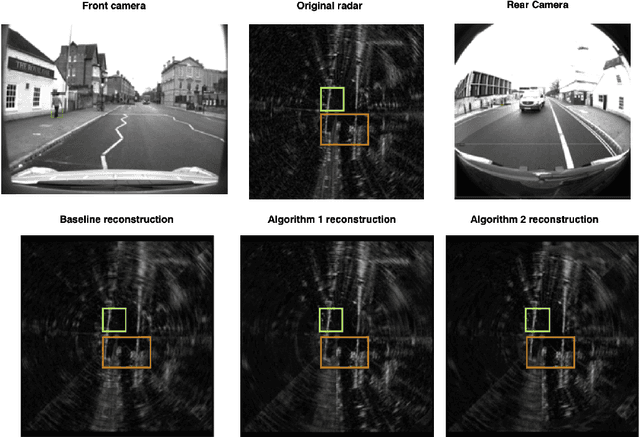
Robust and accurate sensing is of critical importance for advancing autonomous automotive systems. The need to acquire situational awareness in complex urban conditions using sensors such as radar has motivated research on power and latency-efficient signal acquisition methods. In this paper, we present an end-to-end signal processing pipeline, capable of operating in extreme weather conditions, that relies on sub-sampled radar data to perform object detection in vehicular settings. The results of the object detection are further utilized to sub-sample forthcoming radar data, which stands in contrast to prior work where the sub-sampling relies on image information. We show robust detection based on radar data reconstructed using 20% of samples under extreme weather conditions such as snow or fog, and on low-illuminated nights. Additionally, we generate 20% sampled radar data in a fine-tuning set and show 1.1% gain in AP50 across scenes and 3% AP50 gain in motorway condition.
Adaptive Automotive Radar data Acquisition
Oct 05, 2020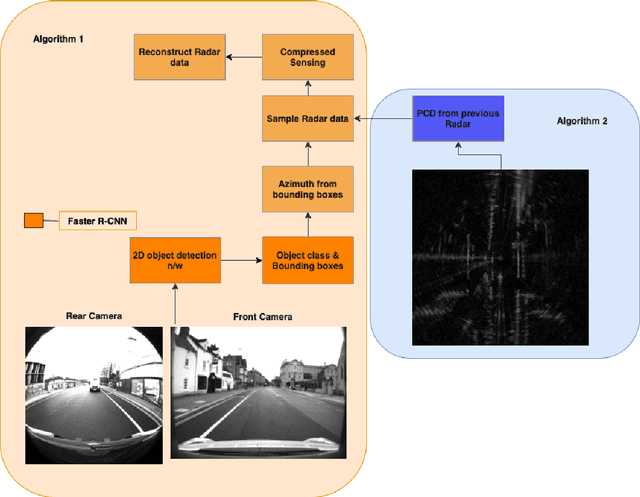
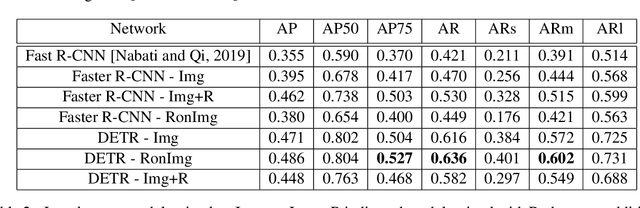
In an autonomous driving scenario, it is vital to acquire and efficiently process data from various sensors to obtain a complete and robust perspective of the surroundings. Many studies have shown the importance of having radar data in addition to images since radar is robust to weather conditions. We develop a novel algorithm for selecting radar return regions to be sampled at a higher rate based on prior reconstructed radar frames and image data. Our approach uses adaptive block-based Compressed Sensing(CS) to allocate higher sampling rates to "important" blocks dynamically while maintaining the overall sampling budget per frame. This improves over block-based CS, which parallelizes computation by dividing the radar frame into blocks. Additionally, we use the Faster R-CNN object detection network to determine these important blocks from previous radar and image information. This mitigates the potential information loss of an object missed by the image or the object detection network. We also develop an end-to-end transformer-based 2D object detection network using the NuScenes radar and image data. Finally, we compare the performance of our algorithm against that of standard CS on the Oxford Radar RobotCar dataset.