 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning model compression using network sensitivity and gradients
Oct 11, 2022
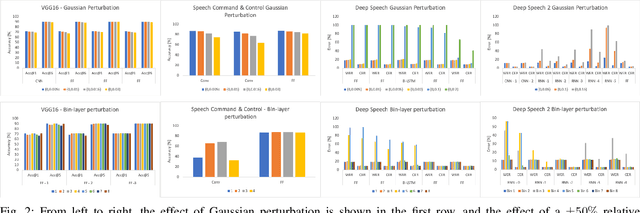
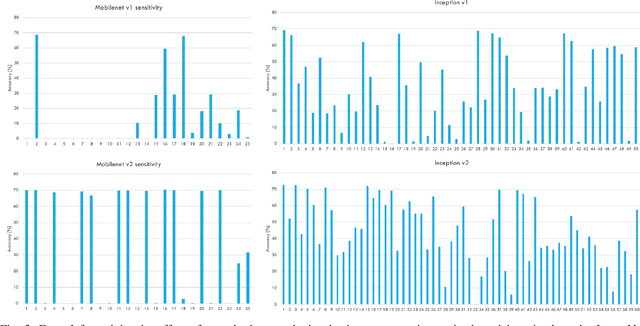
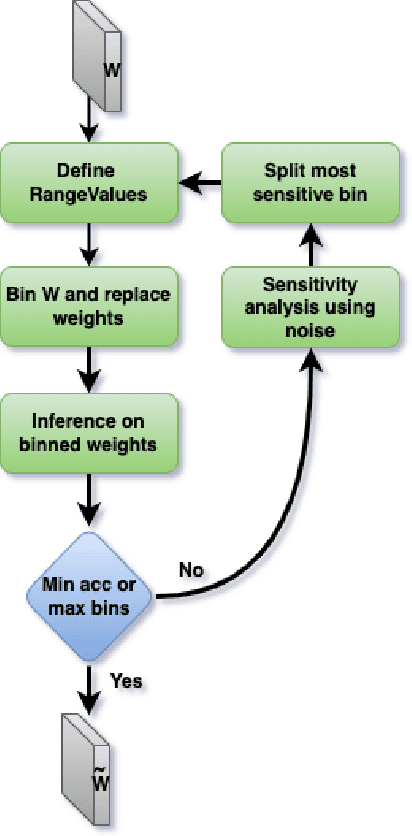
Deep learning model compression is an improving and important field for the edge deployment of deep learning models. Given the increasing size of the models and their corresponding power consumption, it is vital to decrease the model size and compute requirement without a significant drop in the model's performance. In this paper, we present model compression algorithms for both non-retraining and retraining conditions. In the first case where retraining of the model is not feasible due to lack of access to the original data or absence of necessary compute resources while only having access to off-the-shelf models, we propose the Bin & Quant algorithm for compression of the deep learning models using the sensitivity of the network parameters. This results in 13x compression of the speech command and control model and 7x compression of the DeepSpeech2 models. In the second case when the models can be retrained and utmost compression is required for the negligible loss in accuracy, we propose our novel gradient-weighted k-means clustering algorithm (GWK). This method uses the gradients in identifying the important weight values in a given cluster and nudges the centroid towards those values, thereby giving importance to sensitive weights. Our method effectively combines product quantization with the EWGS[1] algorithm for sub-1-bit representation of the quantized models. We test our GWK algorithm on the CIFAR10 dataset across a range of models such as ResNet20, ResNet56, MobileNetv2 and show 35x compression on quantized models for less than 2% absolute loss in accuracy compared to the floating-point models.