 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Margin Hyperdimensional Computing: A Learning-Theoretical Perspective
Mar 04, 2026Overparameterized machine learning (ML) methods such as neural networks may be prohibitively resource intensive for devices with limited computational capabilities. Hyperdimensional computing (HDC) is an emerging resource efficient and low-complexity ML method that allows hardware efficient implementations of (re-)training and inference procedures. In this paper, we propose a maximum-margin HDC classifier, which significantly outperforms baseline HDC methods on several benchmark datasets. Our method leverages a formal relation between HDC and support vector machines (SVMs) that we established for the first time. Our findings may inspire novel HDC methods with potentially more hardware-oriented implementations compared to SVMs, thus enabling more efficient learning solutions for various intelligent resource-constrained applications.
VISOR: Visual Input-based Steering for Output Redirection in Vision-Language Models
Aug 11, 2025Vision Language Models (VLMs) are increasingly being used in a broad range of applications, bringing their security and behavioral control to the forefront. While existing approaches for behavioral control or output redirection, like system prompting in VLMs, are easily detectable and often ineffective, activation-based steering vectors require invasive runtime access to model internals--incompatible with API-based services and closed-source deployments. We introduce VISOR (Visual Input-based Steering for Output Redirection), a novel method that achieves sophisticated behavioral control through optimized visual inputs alone. By crafting universal steering images that induce target activation patterns, VISOR enables practical deployment across all VLM serving modalities while remaining imperceptible compared to explicit textual instructions. We validate VISOR on LLaVA-1.5-7B across three critical alignment tasks: refusal, sycophancy and survival instinct. A single 150KB steering image matches steering vector performance within 1-2% for positive behavioral shifts while dramatically exceeding it for negative steering--achieving up to 25% shifts from baseline compared to steering vectors' modest changes. Unlike system prompting (3-4% shifts), VISOR provides robust bidirectional control while maintaining 99.9% performance on 14,000 unrelated MMLU tasks. Beyond eliminating runtime overhead and model access requirements, VISOR exposes a critical security vulnerability: adversaries can achieve sophisticated behavioral manipulation through visual channels alone, bypassing text-based defenses. Our work fundamentally re-imagines multimodal model control and highlights the urgent need for defenses against visual steering attacks.
Buffer-based Gradient Projection for Continual Federated Learning
Sep 03, 2024Continual Federated Learning (CFL) is essential for enabling real-world applications where multiple decentralized clients adaptively learn from continuous data streams. A significant challenge in CFL is mitigating catastrophic forgetting, where models lose previously acquired knowledge when learning new information. Existing approaches often face difficulties due to the constraints of device storage capacities and the heterogeneous nature of data distributions among clients. While some CFL algorithms have addressed these challenges, they frequently rely on unrealistic assumptions about the availability of task boundaries (i.e., knowing when new tasks begin). To address these limitations, we introduce Fed-A-GEM, a federated adaptation of the A-GEM method (Chaudhry et al., 2019), which employs a buffer-based gradient projection approach. Fed-A-GEM alleviates catastrophic forgetting by leveraging local buffer samples and aggregated buffer gradients, thus preserving knowledge across multiple clients. Our method is combined with existing CFL techniques, enhancing their performance in the CFL context. Our experiments on standard benchmarks show consistent performance improvements across diverse scenarios. For example, in a task-incremental learning scenario using the CIFAR-100 dataset, our method can increase the accuracy by up to 27%. Our code is available at https://github.com/shenghongdai/Fed-A-GEM.
Enhancing O-RAN Security: Evasion Attacks and Robust Defenses for Graph Reinforcement Learning-based Connection Management
May 06, 2024Adversarial machine learning, focused on studying various attacks and defenses on machine learning (ML) models, is rapidly gaining importance as ML is increasingly being adopted for optimizing wireless systems such as Open Radio Access Networks (O-RAN). A comprehensive modeling of the security threats and the demonstration of adversarial attacks and defenses on practical AI based O-RAN systems is still in its nascent stages. We begin by conducting threat modeling to pinpoint attack surfaces in O-RAN using an ML-based Connection management application (xApp) as an example. The xApp uses a Graph Neural Network trained using Deep Reinforcement Learning and achieves on average 54% improvement in the coverage rate measured as the 5th percentile user data rates. We then formulate and demonstrate evasion attacks that degrade the coverage rates by as much as 50% through injecting bounded noise at different threat surfaces including the open wireless medium itself. Crucially, we also compare and contrast the effectiveness of such attacks on the ML-based xApp and a non-ML based heuristic. We finally develop and demonstrate robust training-based defenses against the challenging physical/jamming-based attacks and show a 15% improvement in the coverage rates when compared to employing no defense over a range of noise budgets
Multi-Task Model Personalization for Federated Supervised SVM in Heterogeneous Networks
Apr 01, 2023Federated systems enable collaborative training on highly heterogeneous data through model personalization, which can be facilitated by employing multi-task learning algorithms. However, significant variation in device computing capabilities may result in substantial degradation in the convergence rate of training. To accelerate the learning procedure for diverse participants in a multi-task federated setting, more efficient and robust methods need to be developed. In this paper, we design an efficient iterative distributed method based on the alternating direction method of multipliers (ADMM) for support vector machines (SVMs), which tackles federated classification and regression. The proposed method utilizes efficient computations and model exchange in a network of heterogeneous nodes and allows personalization of the learning model in the presence of non-i.i.d. data. To further enhance privacy, we introduce a random mask procedure that helps avoid data inversion. Finally, we analyze the impact of the proposed privacy mechanisms and participant hardware and data heterogeneity on the system performance.
Sim-to-Real Transfer in Multi-agent Reinforcement Networking for Federated Edge Computing
Oct 18, 2021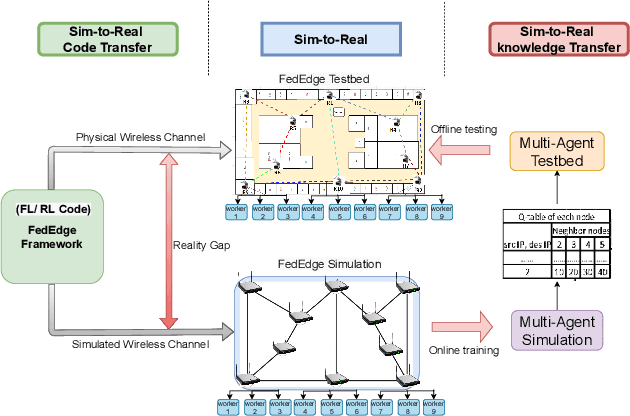
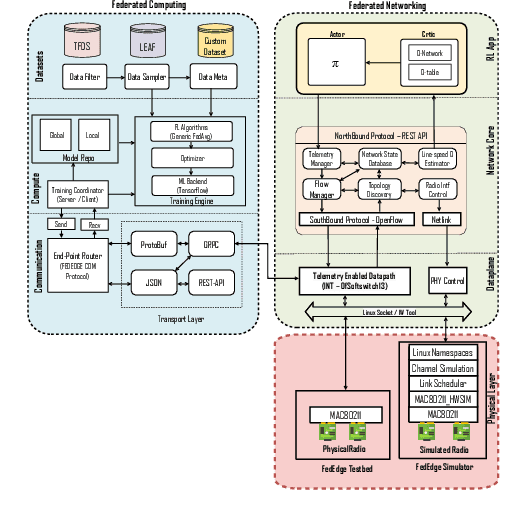

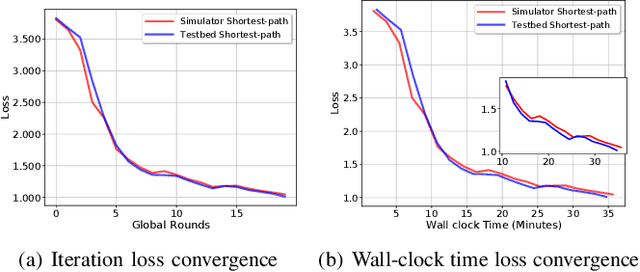
Federated Learning (FL) over wireless multi-hop edge computing networks, i.e., multi-hop FL, is a cost-effective distributed on-device deep learning paradigm. This paper presents FedEdge simulator, a high-fidelity Linux-based simulator, which enables fast prototyping, sim-to-real code, and knowledge transfer for multi-hop FL systems. FedEdge simulator is built on top of the hardware-oriented FedEdge experimental framework with a new extension of the realistic physical layer emulator. This emulator exploits trace-based channel modeling and dynamic link scheduling to minimize the reality gap between the simulator and the physical testbed. Our initial experiments demonstrate the high fidelity of the FedEdge simulator and its superior performance on sim-to-real knowledge transfer in reinforcement learning-optimized multi-hop FL.
MutualNet: Adaptive ConvNet via Mutual Learning from Different Model Configurations
May 14, 2021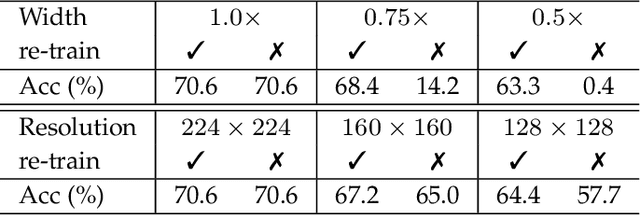

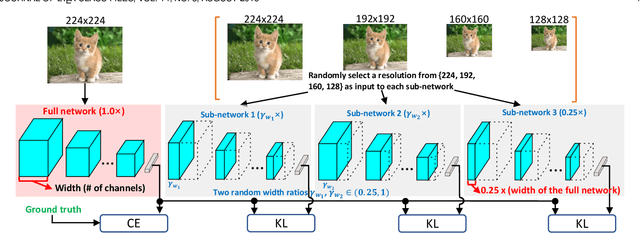
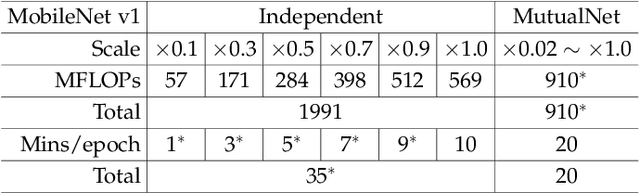
Most existing deep neural networks are static, which means they can only do inference at a fixed complexity. But the resource budget can vary substantially across different devices. Even on a single device, the affordable budget can change with different scenarios, and repeatedly training networks for each required budget would be incredibly expensive. Therefore, in this work, we propose a general method called MutualNet to train a single network that can run at a diverse set of resource constraints. Our method trains a cohort of model configurations with various network widths and input resolutions. This mutual learning scheme not only allows the model to run at different width-resolution configurations but also transfers the unique knowledge among these configurations, helping the model to learn stronger representations overall. MutualNet is a general training methodology that can be applied to various network structures (e.g., 2D networks: MobileNets, ResNet, 3D networks: SlowFast, X3D) and various tasks (e.g., image classification, object detection, segmentation, and action recognition), and is demonstrated to achieve consistent improvements on a variety of datasets. Since we only train the model once, it also greatly reduces the training cost compared to independently training several models. Surprisingly, MutualNet can also be used to significantly boost the performance of a single network, if dynamic resource constraint is not a concern. In summary, MutualNet is a unified method for both static and adaptive, 2D and 3D networks. Codes and pre-trained models are available at \url{https://github.com/taoyang1122/MutualNet}.