 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Hyperdimensional Computing for Resource-Constrained Industrial IoT
Mar 20, 2026In the Industrial Internet of Things (IIoT) systems, edge devices often operate under strict constraints in memory, compute capability, and wireless bandwidth. These limitations challenge the deployment of advanced data analytics tasks, such as predictive and prescriptive maintenance. In this work, we explore hyperdimensional computing (HDC) as a lightweight learning paradigm for resource-constrained IIoT. Conventional centralized HDC leverages the properties of high-dimensional vector spaces to enable energy-efficient training and inference. We integrate this paradigm into a federated learning (FL) framework where devices exchange only prototype representations, which significantly reduces communication overhead. Our numerical results highlight the potential of federated HDC to support collaborative learning in IIoT with fast convergence speed and communication efficiency. These results indicate that HDC represents a lightweight and resilient framework for distributed intelligence in large-scale and resource-constrained IIoT environments.
Large-Margin Hyperdimensional Computing: A Learning-Theoretical Perspective
Mar 04, 2026Overparameterized machine learning (ML) methods such as neural networks may be prohibitively resource intensive for devices with limited computational capabilities. Hyperdimensional computing (HDC) is an emerging resource efficient and low-complexity ML method that allows hardware efficient implementations of (re-)training and inference procedures. In this paper, we propose a maximum-margin HDC classifier, which significantly outperforms baseline HDC methods on several benchmark datasets. Our method leverages a formal relation between HDC and support vector machines (SVMs) that we established for the first time. Our findings may inspire novel HDC methods with potentially more hardware-oriented implementations compared to SVMs, thus enabling more efficient learning solutions for various intelligent resource-constrained applications.
Effects of Small-Scale User Mobility on Highly Directional XR Communications
Jul 08, 2024The development of next-generation communication systems promises to enable extended reality (XR) applications, such as XR gaming with ultra-realistic content and human-grade sensory feedback. These demanding applications impose stringent performance requirements on the underlying wireless communication infrastructure. To meet the expected Quality of Experience (QoE) for XR applications, high-capacity connections are necessary, which can be achieved by using millimeter-wave (mmWave) frequency bands and employing highly directional beams. However, these narrow beams are susceptible to even minor misalignments caused by small-scale user mobility, such as changes in the orientation of the XR head-mounted device (HMD) or minor shifts in user body position. This article explores the impact of small-scale user mobility on mmWave connectivity for XR and reviews approaches to resolve the challenges arising due to small-scale mobility. To deepen our understanding of small-scale mobility during XR usage, we prepared a dataset of user mobility during XR gaming. We use this dataset to study the effects of user mobility on highly directional communication, identifying specific aspects of user mobility that significantly affect the performance of narrow-beam wireless communication systems. Our results confirm the substantial influence of small-scale mobility on beam misalignment, highlighting the need for enhanced mechanisms to effectively manage the consequences of small-scale mobility.
Resource-Efficient Federated Hyperdimensional Computing
Jun 02, 2023
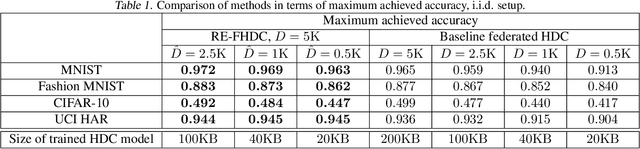


In conventional federated hyperdimensional computing (HDC), training larger models usually results in higher predictive performance but also requires more computational, communication, and energy resources. If the system resources are limited, one may have to sacrifice the predictive performance by reducing the size of the HDC model. The proposed resource-efficient federated hyperdimensional computing (RE-FHDC) framework alleviates such constraints by training multiple smaller independent HDC sub-models and refining the concatenated HDC model using the proposed dropout-inspired procedure. Our numerical comparison demonstrates that the proposed framework achieves a comparable or higher predictive performance while consuming less computational and wireless resources than the baseline federated HDC implementation.
Multi-Task Model Personalization for Federated Supervised SVM in Heterogeneous Networks
Apr 01, 2023Federated systems enable collaborative training on highly heterogeneous data through model personalization, which can be facilitated by employing multi-task learning algorithms. However, significant variation in device computing capabilities may result in substantial degradation in the convergence rate of training. To accelerate the learning procedure for diverse participants in a multi-task federated setting, more efficient and robust methods need to be developed. In this paper, we design an efficient iterative distributed method based on the alternating direction method of multipliers (ADMM) for support vector machines (SVMs), which tackles federated classification and regression. The proposed method utilizes efficient computations and model exchange in a network of heterogeneous nodes and allows personalization of the learning model in the presence of non-i.i.d. data. To further enhance privacy, we introduce a random mask procedure that helps avoid data inversion. Finally, we analyze the impact of the proposed privacy mechanisms and participant hardware and data heterogeneity on the system performance.
Dynamic Network-Assisted D2D-Aided Coded Distributed Learning
Nov 26, 2021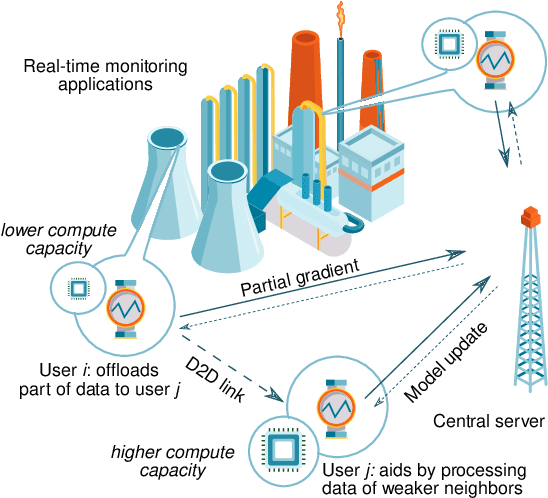

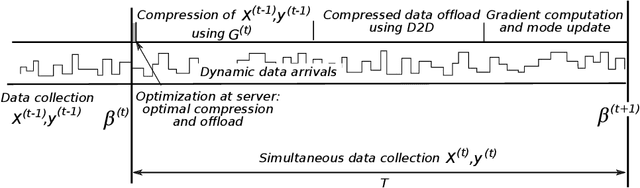
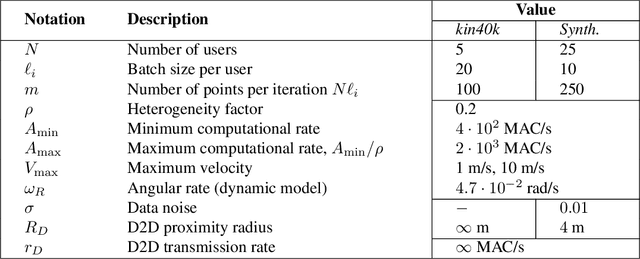
Today, various machine learning (ML) applications offer continuous data processing and real-time data analytics at the edge of a wireless network. Distributed ML solutions are seriously challenged by resource heterogeneity, in particular, the so-called straggler effect. To address this issue, we design a novel device-to-device (D2D)-aided coded federated learning method (D2D-CFL) for load balancing across devices while characterizing privacy leakage. The proposed solution captures system dynamics, including data (time-dependent learning model, varied intensity of data arrivals), device (diverse computational resources and volume of training data), and deployment (varied locations and D2D graph connectivity). We derive an optimal compression rate for achieving minimum processing time and establish its connection with the convergence time. The resulting optimization problem provides suboptimal compression parameters, which improve the total training time. Our proposed method is beneficial for real-time collaborative applications, where the users continuously generate training data.