 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Reinforcement Learning for QoS-Aware Load Balancing in Open Radio Access Networks
Apr 28, 2025


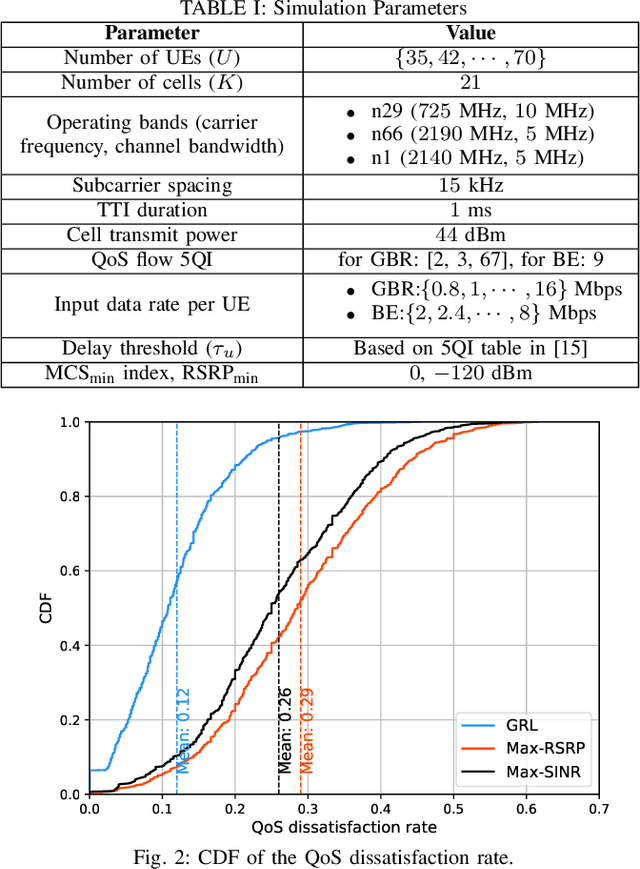
Next-generation wireless cellular networks are expected to provide unparalleled Quality-of-Service (QoS) for emerging wireless applications, necessitating strict performance guarantees, e.g., in terms of link-level data rates. A critical challenge in meeting these QoS requirements is the prevention of cell congestion, which involves balancing the load to ensure sufficient radio resources are available for each cell to serve its designated User Equipments (UEs). In this work, a novel QoS-aware Load Balancing (LB) approach is developed to optimize the performance of Guaranteed Bit Rate (GBR) and Best Effort (BE) traffic in a multi-band Open Radio Access Network (O-RAN) under QoS and resource constraints. The proposed solution builds on Graph Reinforcement Learning (GRL), a powerful framework at the intersection of Graph Neural Network (GNN) and RL. The QoS-aware LB is modeled as a Markov Decision Process, with states represented as graphs. QoS consideration are integrated into both state representations and reward signal design. The LB agent is then trained using an off-policy dueling Deep Q Network (DQN) that leverages a GNN-based architecture. This design ensures the LB policy is invariant to the ordering of nodes (UE or cell), flexible in handling various network sizes, and capable of accounting for spatial node dependencies in LB decisions. Performance of the GRL-based solution is compared with two baseline methods. Results show substantial performance gains, including a $53\%$ reduction in QoS violations and a fourfold increase in the 5th percentile rate for BE traffic.
Enhancing O-RAN Security: Evasion Attacks and Robust Defenses for Graph Reinforcement Learning-based Connection Management
May 06, 2024Adversarial machine learning, focused on studying various attacks and defenses on machine learning (ML) models, is rapidly gaining importance as ML is increasingly being adopted for optimizing wireless systems such as Open Radio Access Networks (O-RAN). A comprehensive modeling of the security threats and the demonstration of adversarial attacks and defenses on practical AI based O-RAN systems is still in its nascent stages. We begin by conducting threat modeling to pinpoint attack surfaces in O-RAN using an ML-based Connection management application (xApp) as an example. The xApp uses a Graph Neural Network trained using Deep Reinforcement Learning and achieves on average 54% improvement in the coverage rate measured as the 5th percentile user data rates. We then formulate and demonstrate evasion attacks that degrade the coverage rates by as much as 50% through injecting bounded noise at different threat surfaces including the open wireless medium itself. Crucially, we also compare and contrast the effectiveness of such attacks on the ML-based xApp and a non-ML based heuristic. We finally develop and demonstrate robust training-based defenses against the challenging physical/jamming-based attacks and show a 15% improvement in the coverage rates when compared to employing no defense over a range of noise budgets
Reliability-Optimized User Admission Control for URLLC Traffic: A Neural Contextual Bandit Approach
Jan 05, 2024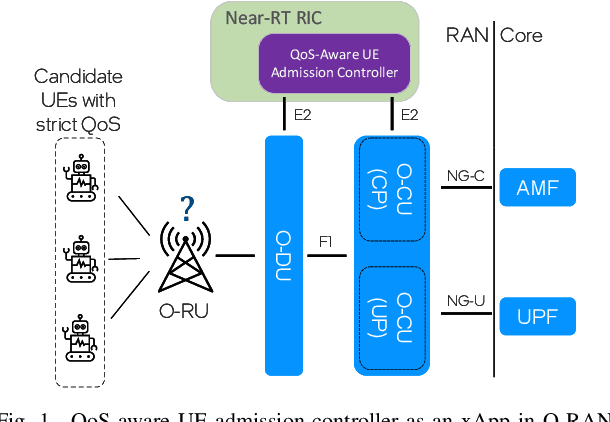
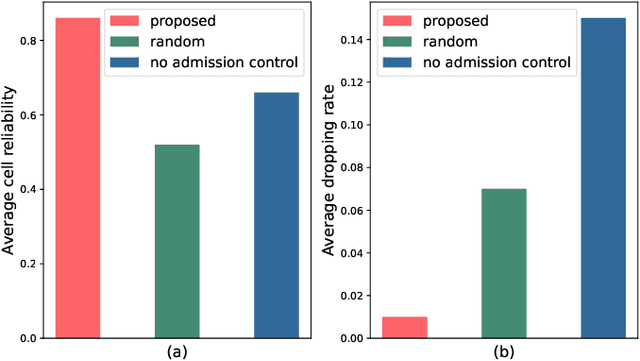
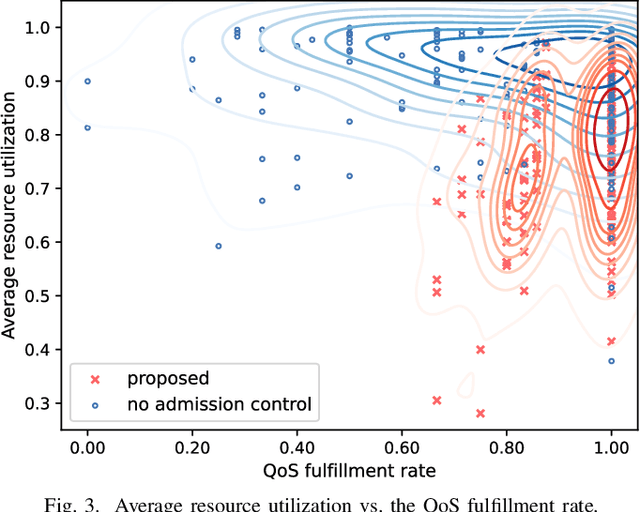
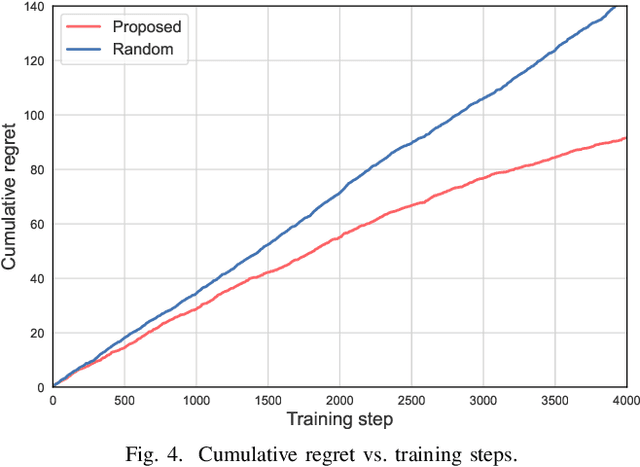
Ultra-reliable low-latency communication (URLLC) is the cornerstone for a broad range of emerging services in next-generation wireless networks. URLLC fundamentally relies on the network's ability to proactively determine whether sufficient resources are available to support the URLLC traffic, and thus, prevent so-called cell overloads. Nonetheless, achieving accurate quality-of-service (QoS) predictions for URLLC user equipment (UEs) and preventing cell overloads are very challenging tasks. This is due to dependency of the QoS metrics (latency and reliability) on traffic and channel statistics, users' mobility, and interdependent performance across UEs. In this paper, a new QoS-aware UE admission control approach is developed to proactively estimate QoS for URLLC UEs, prior to associating them with a cell, and accordingly, admit only a subset of UEs that do not lead to a cell overload. To this end, an optimization problem is formulated to find an efficient UE admission control policy, cognizant of UEs' QoS requirements and cell-level load dynamics. To solve this problem, a new machine learning based method is proposed that builds on (deep) neural contextual bandits, a suitable framework for dealing with nonlinear bandit problems. In fact, the UE admission controller is treated as a bandit agent that observes a set of network measurements (context) and makes admission control decisions based on context-dependent QoS (reward) predictions. The simulation results show that the proposed scheme can achieve near-optimal performance and yield substantial gains in terms of cell-level service reliability and efficient resource utilization.
Resource Management in Wireless Networks via Multi-Agent Deep Reinforcement Learning
Feb 14, 2020
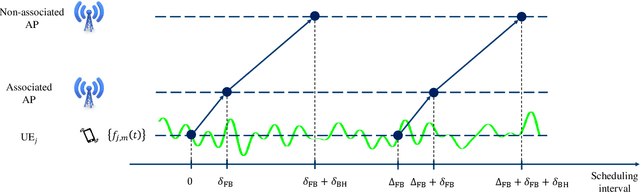
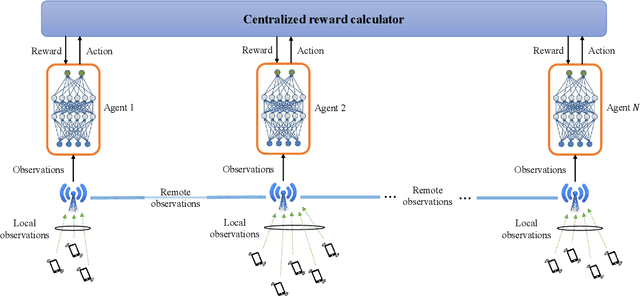
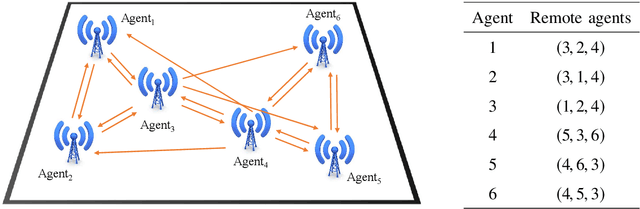
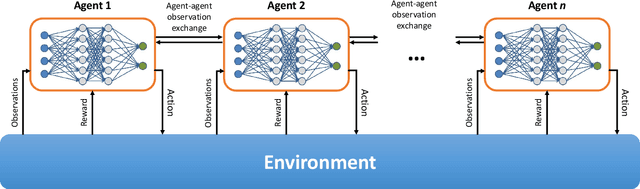
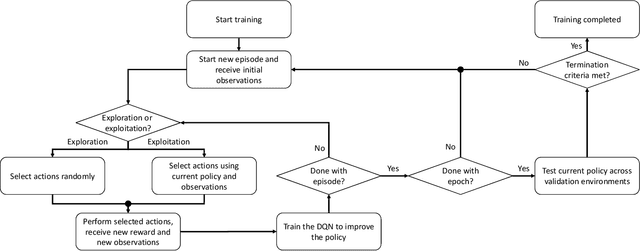
We propose a mechanism for distributed radio resource management using multi-agent deep reinforcement learning (RL) for interference mitigation in wireless networks. We equip each transmitter in the network with a deep RL agent, which receives partial delayed observations from its associated users, while also exchanging observations with its neighboring agents, and decides on which user to serve and what transmit power to use at each scheduling interval. Our proposed framework enables the agents to make decisions simultaneously and in a distributed manner, without any knowledge about the concurrent decisions of other agents. Moreover, our design of the agents' observation and action spaces is scalable, in the sense that an agent trained on a scenario with a specific number of transmitters and receivers can be readily applied to scenarios with different numbers of transmitters and/or receivers. Simulation results demonstrate the superiority of our proposed approach compared to decentralized baselines in terms of the tradeoff between average and $5^{th}$ percentile user rates, while achieving performance close to, and even in certain cases outperforming, that of a centralized information-theoretic scheduling algorithm. We also show that our trained agents are robust and maintain their performance gains when experiencing mismatches between training and testing deployments.
When Multiple Agents Learn to Schedule: A Distributed Radio Resource Management Framework
Jun 20, 2019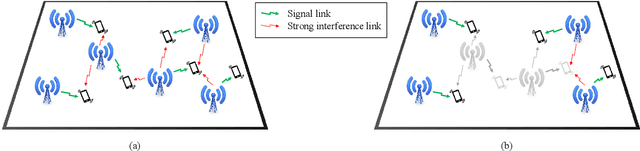
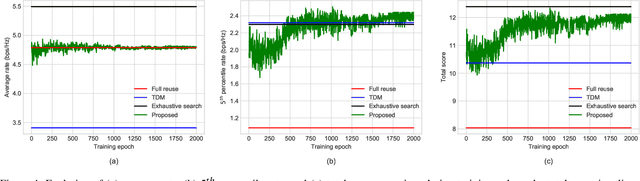
Interference among concurrent transmissions in a wireless network is a key factor limiting the system performance. One way to alleviate this problem is to manage the radio resources in order to maximize either the average or the worst-case performance. However, joint consideration of both metrics is often neglected as they are competing in nature. In this article, a mechanism for radio resource management using multi-agent deep reinforcement learning (RL) is proposed, which strikes the right trade-off between maximizing the average and the $5^{th}$ percentile user throughput. Each transmitter in the network is equipped with a deep RL agent, receiving partial observations from the network (e.g., channel quality, interference level, etc.) and deciding whether to be active or inactive at each scheduling interval for given radio resources, a process referred to as link scheduling. Based on the actions of all agents, the network emits a reward to the agents, indicating how good their joint decisions were. The proposed framework enables the agents to make decisions in a distributed manner, and the reward is designed in such a way that the agents strive to guarantee a minimum performance, leading to a fair resource allocation among all users across the network. Simulation results demonstrate the superiority of our approach compared to decentralized baselines in terms of average and $5^{th}$ percentile user throughput, while achieving performance close to that of a centralized exhaustive search approach. Moreover, the proposed framework is robust to mismatches between training and testing scenarios. In particular, it is shown that an agent trained on a network with low transmitter density maintains its performance and outperforms the baselines when deployed in a network with a higher transmitter density.