 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Management in Wireless Networks via Multi-Agent Deep Reinforcement Learning
Feb 14, 2020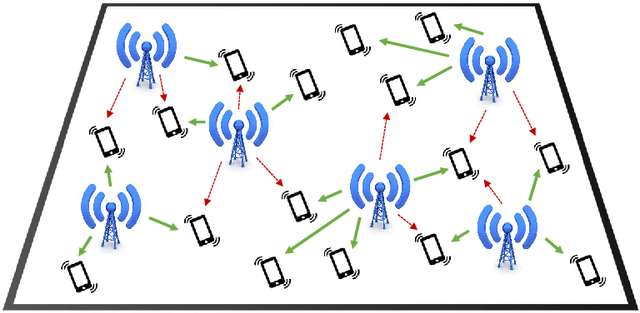
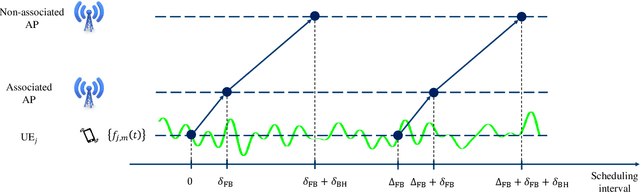
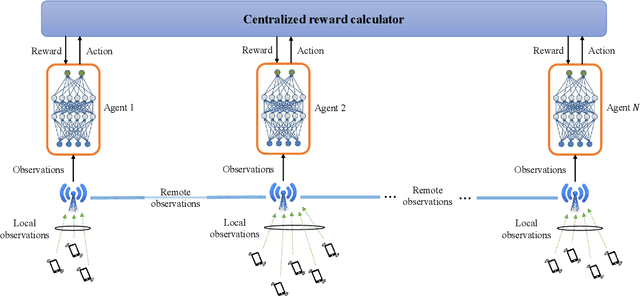
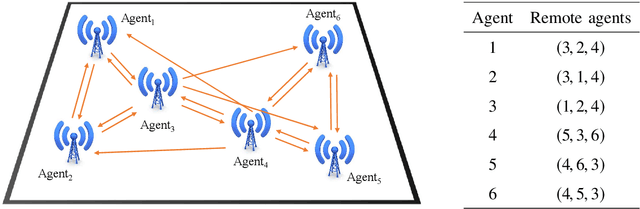
We propose a mechanism for distributed radio resource management using multi-agent deep reinforcement learning (RL) for interference mitigation in wireless networks. We equip each transmitter in the network with a deep RL agent, which receives partial delayed observations from its associated users, while also exchanging observations with its neighboring agents, and decides on which user to serve and what transmit power to use at each scheduling interval. Our proposed framework enables the agents to make decisions simultaneously and in a distributed manner, without any knowledge about the concurrent decisions of other agents. Moreover, our design of the agents' observation and action spaces is scalable, in the sense that an agent trained on a scenario with a specific number of transmitters and receivers can be readily applied to scenarios with different numbers of transmitters and/or receivers. Simulation results demonstrate the superiority of our proposed approach compared to decentralized baselines in terms of the tradeoff between average and $5^{th}$ percentile user rates, while achieving performance close to, and even in certain cases outperforming, that of a centralized information-theoretic scheduling algorithm. We also show that our trained agents are robust and maintain their performance gains when experiencing mismatches between training and testing deployments.
When Multiple Agents Learn to Schedule: A Distributed Radio Resource Management Framework
Jun 20, 2019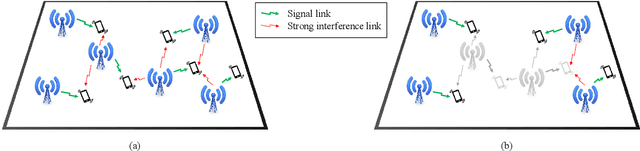
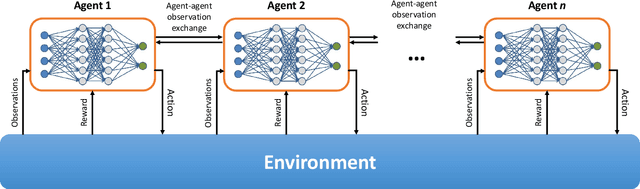
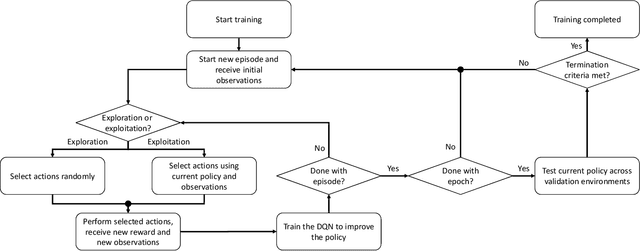
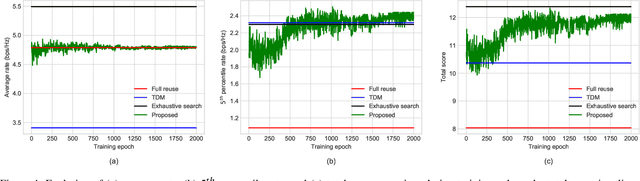
Interference among concurrent transmissions in a wireless network is a key factor limiting the system performance. One way to alleviate this problem is to manage the radio resources in order to maximize either the average or the worst-case performance. However, joint consideration of both metrics is often neglected as they are competing in nature. In this article, a mechanism for radio resource management using multi-agent deep reinforcement learning (RL) is proposed, which strikes the right trade-off between maximizing the average and the $5^{th}$ percentile user throughput. Each transmitter in the network is equipped with a deep RL agent, receiving partial observations from the network (e.g., channel quality, interference level, etc.) and deciding whether to be active or inactive at each scheduling interval for given radio resources, a process referred to as link scheduling. Based on the actions of all agents, the network emits a reward to the agents, indicating how good their joint decisions were. The proposed framework enables the agents to make decisions in a distributed manner, and the reward is designed in such a way that the agents strive to guarantee a minimum performance, leading to a fair resource allocation among all users across the network. Simulation results demonstrate the superiority of our approach compared to decentralized baselines in terms of average and $5^{th}$ percentile user throughput, while achieving performance close to that of a centralized exhaustive search approach. Moreover, the proposed framework is robust to mismatches between training and testing scenarios. In particular, it is shown that an agent trained on a network with low transmitter density maintains its performance and outperforms the baselines when deployed in a network with a higher transmitter density.
Context-Aware Mobility Management in HetNets: A Reinforcement Learning Approach
May 07, 2015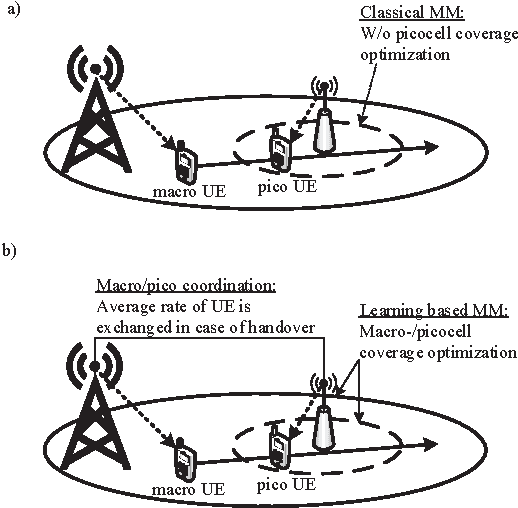
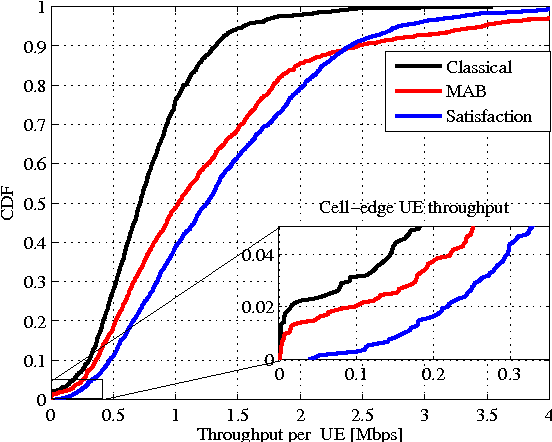
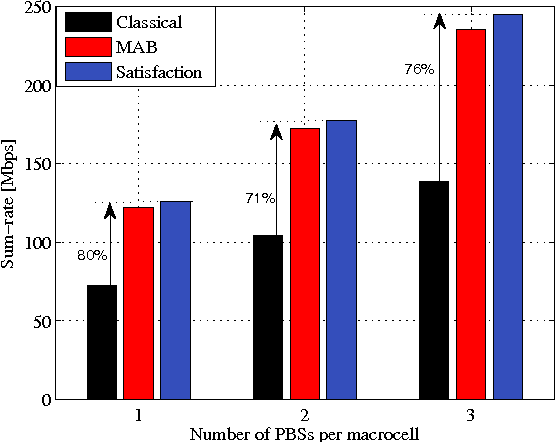
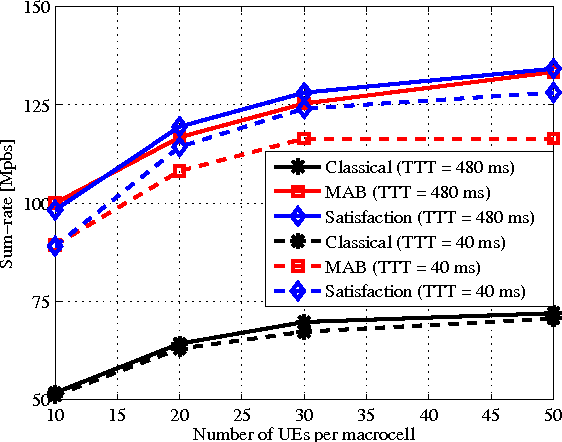
The use of small cell deployments in heterogeneous network (HetNet) environments is expected to be a key feature of 4G networks and beyond, and essential for providing higher user throughput and cell-edge coverage. However, due to different coverage sizes of macro and pico base stations (BSs), such a paradigm shift introduces additional requirements and challenges in dense networks. Among these challenges is the handover performance of user equipment (UEs), which will be impacted especially when high velocity UEs traverse picocells. In this paper, we propose a coordination-based and context-aware mobility management (MM) procedure for small cell networks using tools from reinforcement learning. Here, macro and pico BSs jointly learn their long-term traffic loads and optimal cell range expansion, and schedule their UEs based on their velocities and historical rates (exchanged among tiers). The proposed approach is shown to not only outperform the classical MM in terms of UE throughput, but also to enable better fairness. In average, a gain of up to 80\% is achieved for UE throughput, while the handover failure probability is reduced up to a factor of three by the proposed learning based MM approaches.