 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Deep Learning-Driven Multi-Coil MRI Reconstruction via Self-Supervised Denoising
Nov 19, 2024We examine the effect of incorporating self-supervised denoising as a pre-processing step for training deep learning (DL) based reconstruction methods on data corrupted by Gaussian noise. K-space data employed for training are typically multi-coil and inherently noisy. Although DL-based reconstruction methods trained on fully sampled data can enable high reconstruction quality, obtaining large, noise-free datasets is impractical. We leverage Generalized Stein's Unbiased Risk Estimate (GSURE) for denoising. We evaluate two DL-based reconstruction methods: Diffusion Probabilistic Models (DPMs) and Model-Based Deep Learning (MoDL). We evaluate the impact of denoising on the performance of these DL-based methods in solving accelerated multi-coil magnetic resonance imaging (MRI) reconstruction. The experiments were carried out on T2-weighted brain and fat-suppressed proton-density knee scans. We observed that self-supervised denoising enhances the quality and efficiency of MRI reconstructions across various scenarios. Specifically, employing denoised images rather than noisy counterparts when training DL networks results in lower normalized root mean squared error (NRMSE), higher structural similarity index measure (SSIM) and peak signal-to-noise ratio (PSNR) across different SNR levels, including 32dB, 22dB, and 12dB for T2-weighted brain data, and 24dB, 14dB, and 4dB for fat-suppressed knee data. Overall, we showed that denoising is an essential pre-processing technique capable of improving the efficacy of DL-based MRI reconstruction methods under diverse conditions. By refining the quality of input data, denoising can enable the training of more effective DL networks, potentially bypassing the need for noise-free reference MRI scans.
Enabling Quick, Accurate Crowdsourced Annotation for Elevation-Aware Flood Extent Mapping
Jul 31, 2024In order to assess damage and properly allocate relief efforts, mapping the extent of flood events is a necessary and important aspect of disaster management. In recent years, deep learning methods have evolved as an effective tool to quickly label high-resolution imagery and provide necessary flood extent mappings. These methods, though, require large amounts of annotated training data to create models that are accurate and robust to new flooded imagery. In this work, we provide FloodTrace, an application that enables effective crowdsourcing for flooded region annotation for machine learning training data, removing the requirement for annotation to be done solely by researchers. We accomplish this through two orthogonal methods within our application, informed by requirements from domain experts. First, we utilize elevation-guided annotation tools and 3D rendering to inform user annotation decisions with digital elevation model data, improving annotation accuracy. For this purpose, we provide a unique annotation method that uses topological data analysis to outperform the state-of-the-art elevation-guided annotation tool in efficiency. Second, we provide a framework for researchers to review aggregated crowdsourced annotations and correct inaccuracies using methods inspired by uncertainty visualization. We conducted a user study to confirm the application effectiveness in which 266 graduate students annotated high-resolution aerial imagery from Hurricane Matthew in North Carolina. Experimental results show the accuracy and efficiency benefits of our application apply even for untrained users. In addition, using our aggregation and correction framework, flood detection models trained on crowdsourced annotations were able to achieve performance equal to models trained on expert-labeled annotations, while requiring a fraction of the time on the part of the researcher.
Ambient Diffusion Posterior Sampling: Solving Inverse Problems with Diffusion Models trained on Corrupted Data
Mar 13, 2024



We provide a framework for solving inverse problems with diffusion models learned from linearly corrupted data. Our method, Ambient Diffusion Posterior Sampling (A-DPS), leverages a generative model pre-trained on one type of corruption (e.g. image inpainting) to perform posterior sampling conditioned on measurements from a potentially different forward process (e.g. image blurring). We test the efficacy of our approach on standard natural image datasets (CelebA, FFHQ, and AFHQ) and we show that A-DPS can sometimes outperform models trained on clean data for several image restoration tasks in both speed and performance. We further extend the Ambient Diffusion framework to train MRI models with access only to Fourier subsampled multi-coil MRI measurements at various acceleration factors (R=2, 4, 6, 8). We again observe that models trained on highly subsampled data are better priors for solving inverse problems in the high acceleration regime than models trained on fully sampled data. We open-source our code and the trained Ambient Diffusion MRI models: https://github.com/utcsilab/ambient-diffusion-mri .
Solving Inverse Problems with Score-Based Generative Priors learned from Noisy Data
May 02, 2023



We present SURE-Score: an approach for learning score-based generative models using training samples corrupted by additive Gaussian noise. When a large training set of clean samples is available, solving inverse problems via score-based (diffusion) generative models trained on the underlying fully-sampled data distribution has recently been shown to outperform end-to-end supervised deep learning. In practice, such a large collection of training data may be prohibitively expensive to acquire in the first place. In this work, we present an approach for approximately learning a score-based generative model of the clean distribution, from noisy training data. We formulate and justify a novel loss function that leverages Stein's unbiased risk estimate to jointly denoise the data and learn the score function via denoising score matching, while using only the noisy samples. We demonstrate the generality of SURE-Score by learning priors and applying posterior sampling to ill-posed inverse problems in two practical applications from different domains: compressive wireless multiple-input multiple-output channel estimation and accelerated 2D multi-coil magnetic resonance imaging reconstruction, where we demonstrate competitive reconstruction performance when learning at signal-to-noise ratio values of 0 and 10 dB, respectively.
FSE Compensated Motion Correction for MRI Using Data Driven Methods
Jul 01, 2022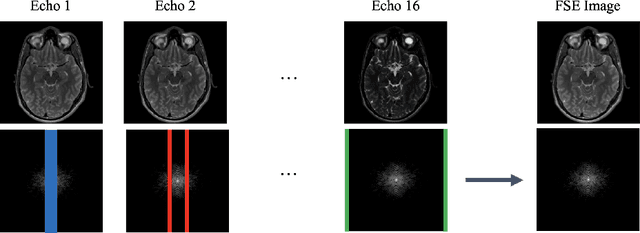
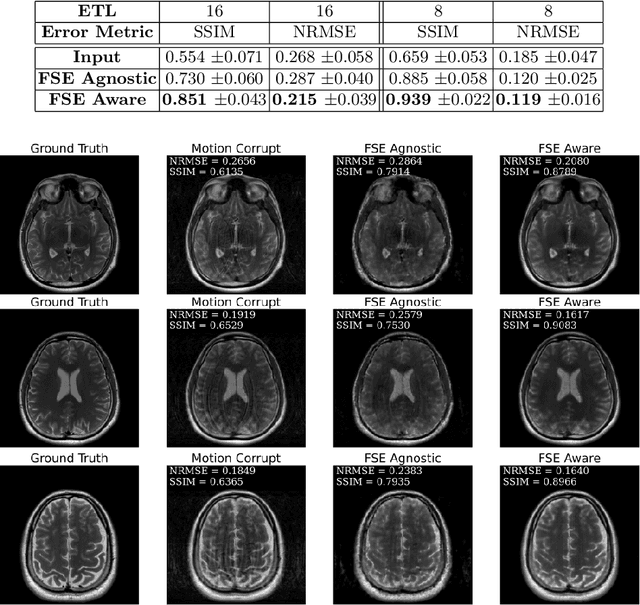
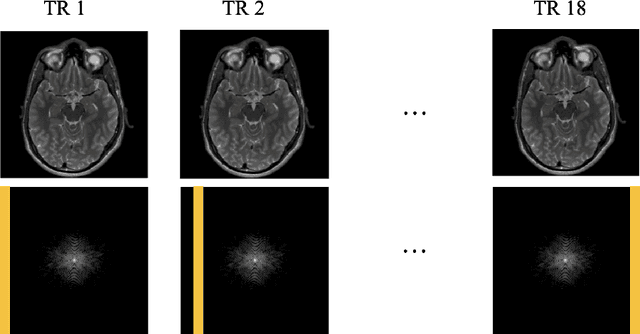
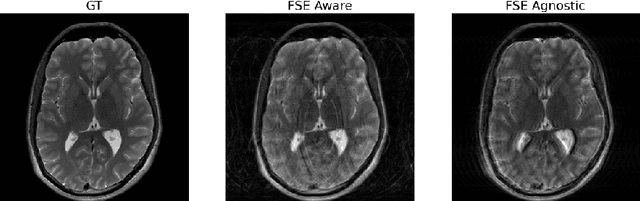
Magnetic Resonance Imaging (MRI) is a widely used medical imaging modality boasting great soft tissue contrast without ionizing radiation, but unfortunately suffers from long acquisition times. Long scan times can lead to motion artifacts, for example due to bulk patient motion such as head movement and periodic motion produced by the heart or lungs. Motion artifacts can degrade image quality and in some cases render the scans nondiagnostic. To combat this problem, prospective and retrospective motion correction techniques have been introduced. More recently, data driven methods using deep neural networks have been proposed. As a large number of publicly available MRI datasets are based on Fast Spin Echo (FSE) sequences, methods that use them for training should incorporate the correct FSE acquisition dynamics. Unfortunately, when simulating training data, many approaches fail to generate accurate motion-corrupt images by neglecting the effects of the temporal ordering of the k-space lines as well as neglecting the signal decay throughout the FSE echo train. In this work, we highlight this consequence and demonstrate a training method which correctly simulates the data acquisition process of FSE sequences with higher fidelity by including sample ordering and signal decay dynamics. Through numerical experiments, we show that accounting for the FSE acquisition leads to better motion correction performance during inference.
Few-Max: Few-Shot Domain Adaptation for Unsupervised Contrastive Representation Learning
Jun 22, 2022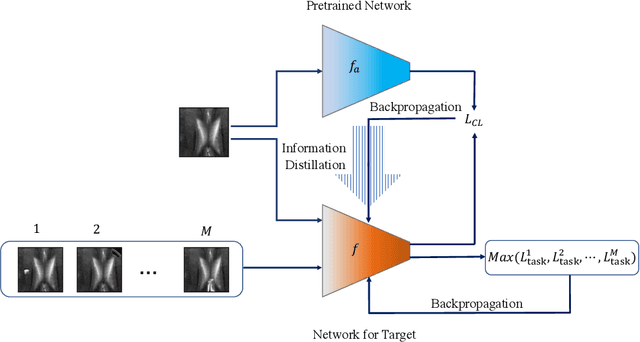
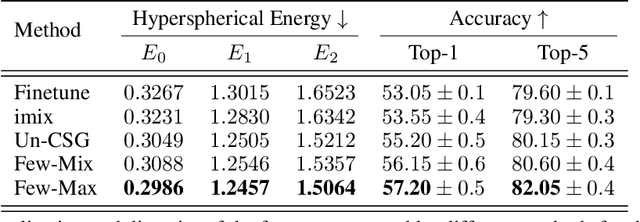
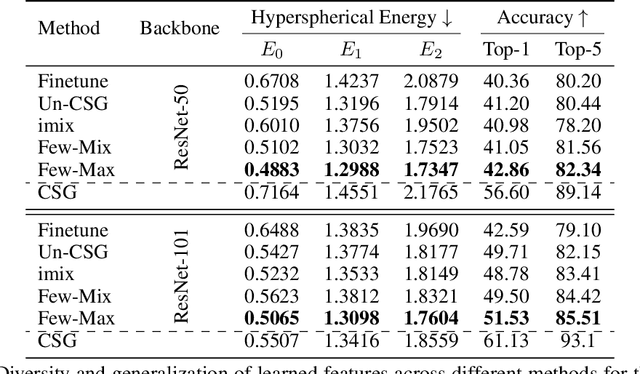
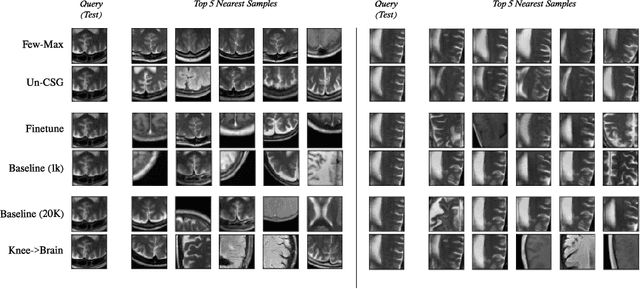
Contrastive self-supervised learning methods learn to map data points such as images into non-parametric representation space without requiring labels. While highly successful, current methods require a large amount of data in the training phase. In situations where the target training set is limited in size, generalization is known to be poor. Pretraining on a large source data set and fine-tuning on the target samples is prone to overfitting in the few-shot regime, where only a small number of target samples are available. Motivated by this, we propose a domain adaption method for self-supervised contrastive learning, termed Few-Max, to address the issue of adaptation to a target distribution under few-shot learning. To quantify the representation quality, we evaluate Few-Max on a range of source and target datasets, including ImageNet, VisDA, and fastMRI, on which Few-Max consistently outperforms other approaches.
An untrained deep learning method for reconstructing dynamic magnetic resonance images from accelerated model-based data
May 04, 2022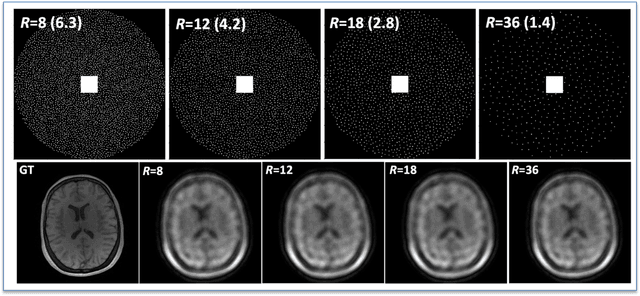

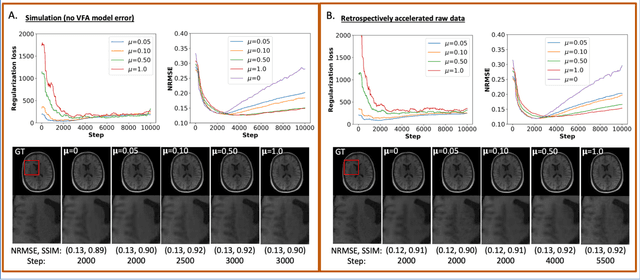
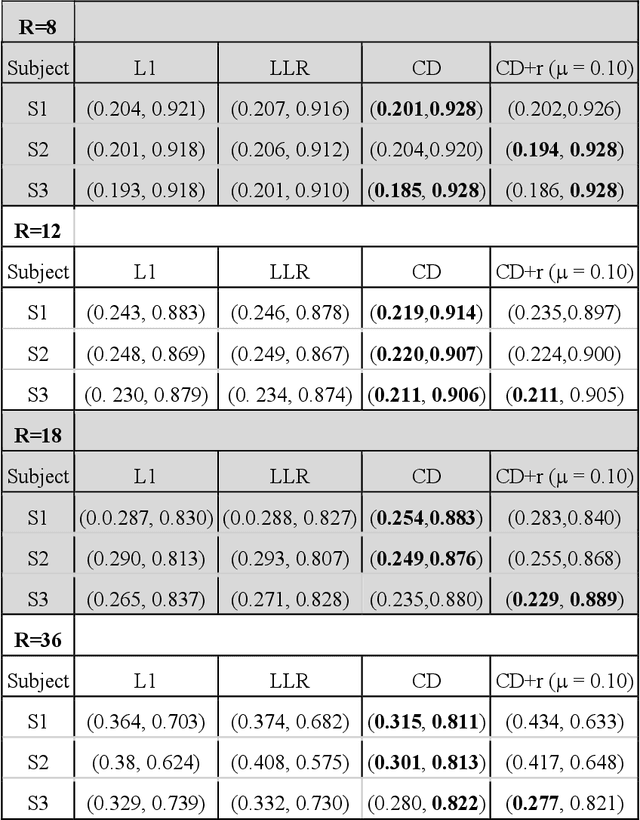
The purpose of this work is to implement physics-based regularization as a stopping condition in tuning an untrained deep neural network for reconstructing MR images from accelerated data. The ConvDecoder neural network was trained with a physics-based regularization term incorporating the spoiled gradient echo equation that describes variable-flip angle (VFA) data. Fully-sampled VFA k-space data were retrospectively accelerated by factors of R={8,12,18,36} and reconstructed with ConvDecoder (CD), ConvDecoder with the proposed regularization (CD+r), locally low-rank (LR) reconstruction, and compressed sensing with L1-wavelet regularization (L1). Final images from CD+r training were evaluated at the \emph{argmin} of the regularization loss; whereas the CD, LR, and L1 reconstructions were chosen optimally based on ground truth data. The performance measures used were the normalized root-mean square error, the concordance correlation coefficient (CCC), and the structural similarity index (SSIM). The CD+r reconstructions, chosen using the stopping condition, yielded SSIMs that were similar to the CD (p=0.47) and LR SSIMs (p=0.95) across R and that were significantly higher than the L1 SSIMs (p=0.04). The CCC values for the CD+r T1 maps across all R and subjects were greater than those corresponding to the L1 (p=0.15) and LR (p=0.13) T1 maps, respectively. For R > 12 (<4.2 minutes scan time), L1 and LR T1 maps exhibit a loss of spatially refined details compared to CD+r. We conclude that the use of an untrained neural network together with a physics-based regularization loss shows promise as a measure for determining the optimal stopping point in training without relying on fully-sampled ground truth data.