 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Max: Few-Shot Domain Adaptation for Unsupervised Contrastive Representation Learning
Paper and Code
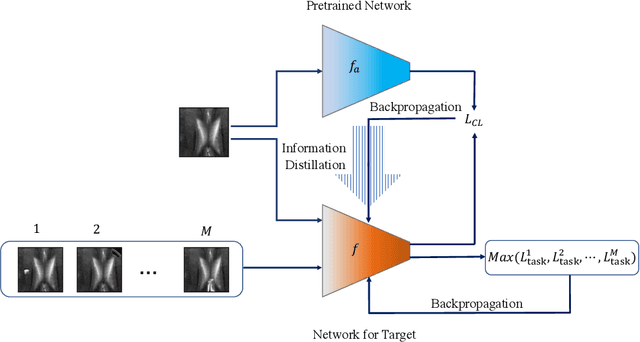
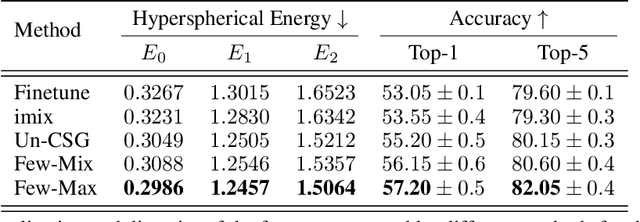
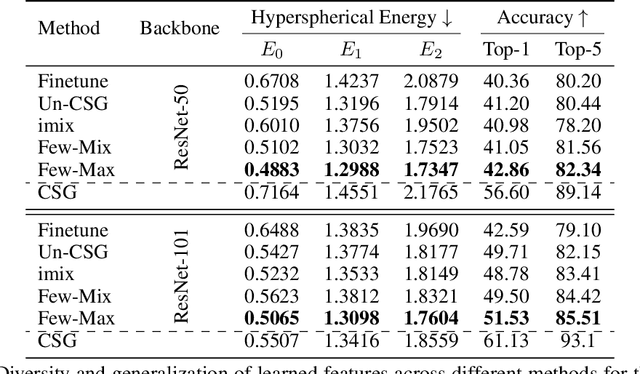
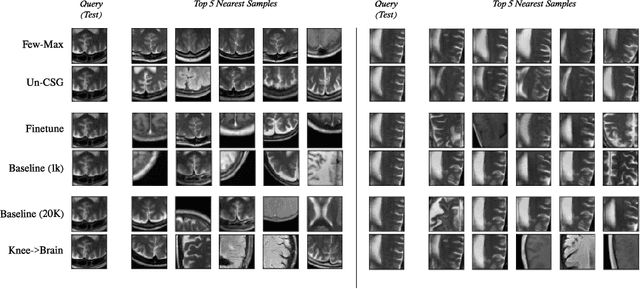
Contrastive self-supervised learning methods learn to map data points such as images into non-parametric representation space without requiring labels. While highly successful, current methods require a large amount of data in the training phase. In situations where the target training set is limited in size, generalization is known to be poor. Pretraining on a large source data set and fine-tuning on the target samples is prone to overfitting in the few-shot regime, where only a small number of target samples are available. Motivated by this, we propose a domain adaption method for self-supervised contrastive learning, termed Few-Max, to address the issue of adaptation to a target distribution under few-shot learning. To quantify the representation quality, we evaluate Few-Max on a range of source and target datasets, including ImageNet, VisDA, and fastMRI, on which Few-Max consistently outperforms other approaches.